
这节课解决的不是同一个问题
上一讲 AlphaProof 展示了一个强系统:把问题放进 Lean,利用 proof assistant 的反馈做搜索和强化学习。这一讲 Kaiyu Yang 反过来问更基础的问题:为什么今天的 math/coding LLM 会成为能力竞赛中心?为什么只靠自然语言数学训练还不够?LLM 如何与 Lean 这样的形式系统结合成为 theorem prover?以及最难的,如何把非形式数学忠实地转换成形式数学?
因此这节课可以理解成 AlphaProof 的前置层和泛化层。AlphaProof 偏向“已有形式化问题以后,如何证明”;本讲覆盖“如何训练 theorem prover、如何评估 prover、如何自动形式化 theorem/proof、如何处理几何图形中的隐含推理”。

本章小结
这节课不是 AlphaProof 的重复,而是把“AI + formal math”的问题拆开:先看现代 math LLM 的训练路径,再看形式推理为什么是缺失环节,最后落到 theorem proving 与 autoformalization 两条技术线。
现代 Math LLM:SFT、RL 与可验证性
Yang 首先解释当前 LLM 数学能力竞赛的背景。OpenAI、Google、xAI 等模型发布时,经常突出 AIME、IMO、Codeforces 等数学和代码指标。原因不是这些任务覆盖了所有智能,而是它们既需要推理和规划,又比写小说、作曲等任务更容易定义评价标准。
SFT:好数据非常关键
监督微调的路径可以概括为:预训练模型先吸收文本和代码,再用数学网页、分步解题数据、工具集成解法等数据做后训练。这个路径的优势是直接、稳定、工程上成熟;限制是高度依赖数据质量和覆盖面。slides 提到公开数学数据集的规模可达约 900K,但高级数学、研究数学和高质量 proof 数据仍然稀缺。

RL:可验证题目让训练信号变硬
RL 路径的关键是 verifiable problems。如果题目有可检查答案,系统可以采样多个解法,只要最终答案正确就给奖励;对代码任务,可以跑 unit tests;对某些数学题,可以检查答案或用工具验证。这个思路解释了为什么 math/coding 任务在后训练中非常有吸引力。
但这也暴露出一个边界:答案正确不等于证明正确。对 pre-college math 或竞赛答案题,验证答案常常够用;对高级数学和证明写作,真正需要验证的是推理结构,而不是一个数值答案。

本章小结
SFT 和 RL 解释了当前数学 LLM 的快速进步:一个依赖高质量数据,一个依赖硬反馈。但它们在高级数学和证明任务上会遇到数据稀缺、推理不可直接验证、动作空间巨大等问题。这正是 formal reasoning 出场的原因。
为什么 LLM Alone 不够
Yang 用两类 gap 说明普通 math LLM 的不足。第一,从 pre-college math 到 advanced math。已有成功更多集中在 AIME、IMO 等竞赛任务,研究数学的数据更少、结构更开放。第二,从 guessing answers 到 writing proofs。模型可能给出正确答案或看似合理的证明,但证明是否有效仍需要形式检查。

缺失环节:Formal Reasoning
本讲给出的立场是:缺失环节是 formal reasoning,即把数学推理锚定在 Lean、Coq、Isabelle 等形式系统中。形式系统让 theorem/proof 变成机器可检查对象,并且可以在 proof search 过程中给出局部反馈。

Lean:把数学写成可检查程序
slides 用 Lean 文件展示 formalizing mathematics:一个 theorem statement、上下文、目标、proof tree、project 和依赖库共同构成形式证明环境。Lean 不是一个普通语法格式,而是一个交互式证明环境。模型要做 theorem proving,就需要在这个环境里选择下一步 tactic 或生成完整 proof。

本章小结
LLM alone 的问题不是模型完全不会数学,而是缺少足够可靠的推理核验和结构化交互环境。形式系统提供了这个环境,使 theorem proving 可以被训练、搜索和评估。
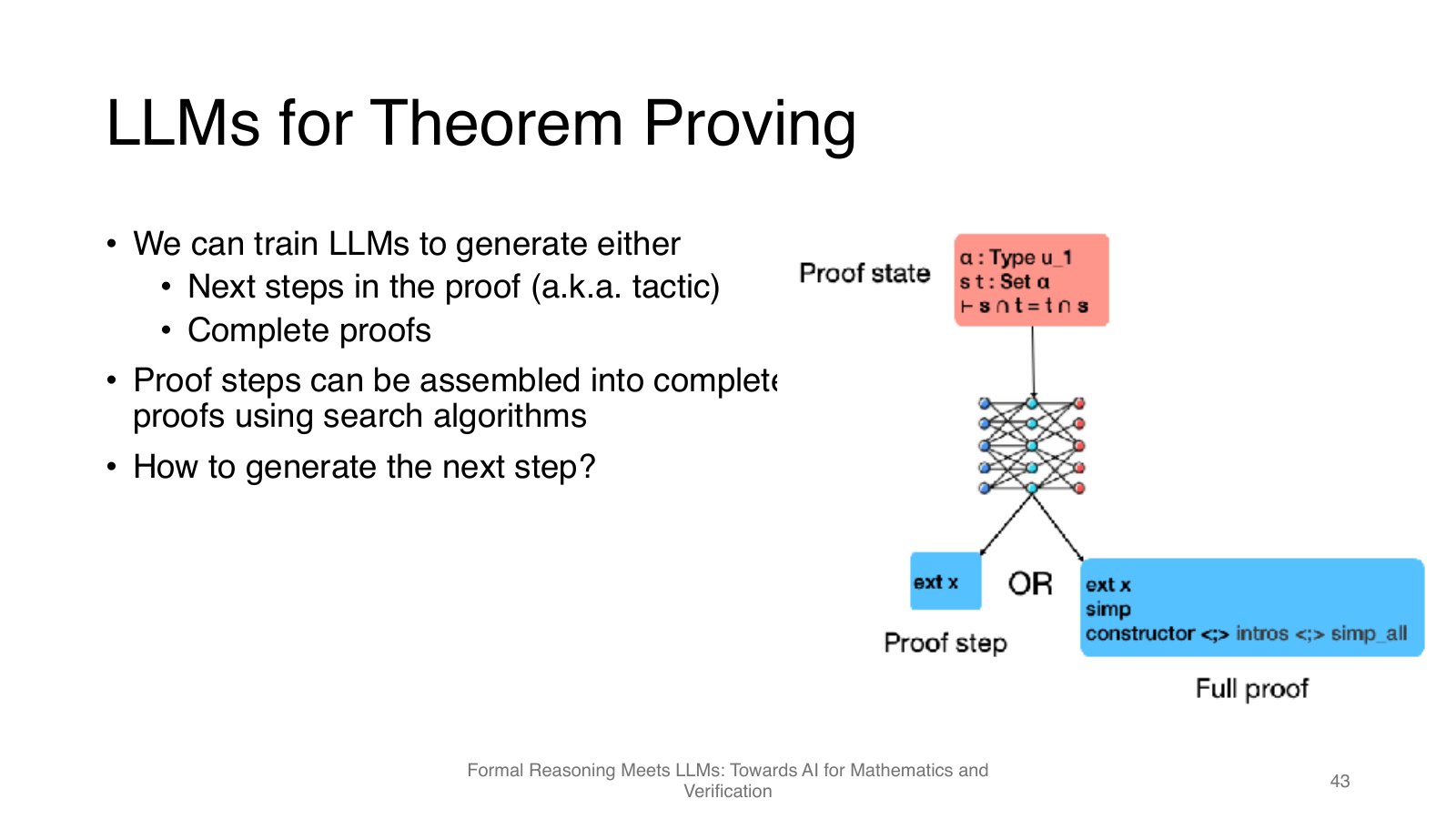
LLM 做自动定理证明
自动定理证明在这节课中主要指:给定一个形式化 theorem 和当前 Lean proof state,模型生成下一步 tactic 或完整 proof,并与 Lean 交互直到证明完成。这里最重要的概念是“交互式证明”:模型不是一次性写完自然语言证明,而是在 proof assistant 中逐步推进。
LeanDojo:开放数据、工具和基准
Yang 介绍 LeanDojo,是因为早期很多 LLM prover 是私有系统,难以复现和比较。LeanDojo 提供开源的数据、训练/评估基准、模型 checkpoint,以及从 Lean 项目中抽取数据和与 Lean 交互的工具。slides 中给出的 LeanDojo Benchmark 包含 98,641 个 theorem/proof、217,639 个 tactic、129,162 个 premise。

ReProver:检索增强 theorem prover
ReProver 的核心思想是:给定当前 proof state,从所有可访问 premises 中检索相关前提,把检索结果和 state 拼接后用于 tactic generation。这里的检索不是普通 RAG 的装饰,而是在 formal proof 中缩小可用知识空间。一个证明状态可调用的 lemma 太多,如果不检索,模型很难在巨大库中找到合适工具。

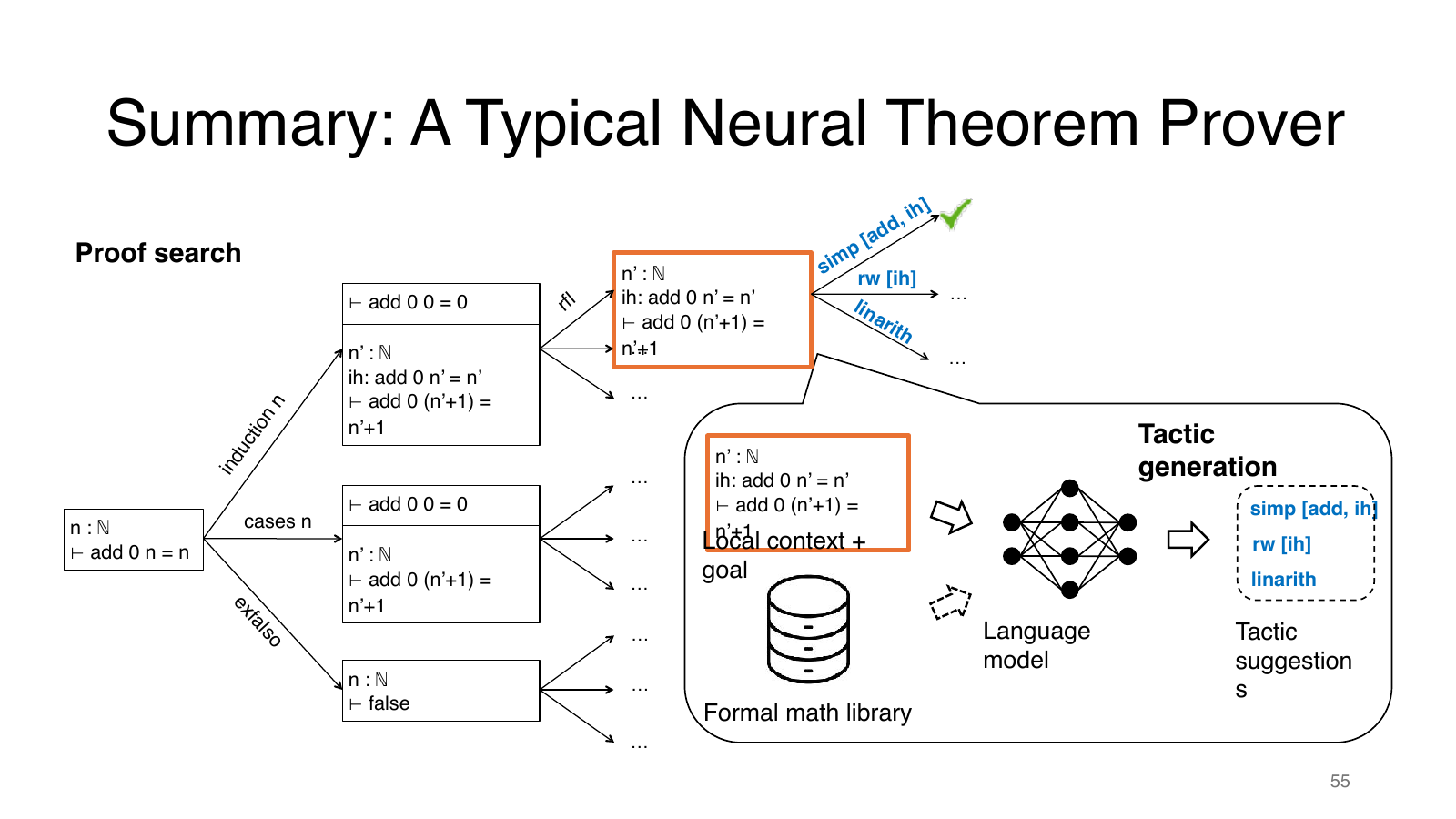
典型 neural theorem prover 的结构
一个典型 neural theorem prover 可以概括为:从 theorem 出发,维护 proof search tree;每个节点是 Lean state;模型根据 state 和检索到的 premises 生成 tactic;Lean 执行 tactic 后返回新 state;搜索策略决定继续扩展哪个节点。
本章小结
LLM theorem proving 的关键不是让模型“像人一样写证明”,而是让模型成为 proof search 中的策略组件。LeanDojo 提供开放环境,ReProver 展示检索如何缩小知识空间,Lean 交互则提供可靠反馈。
动作空间问题:从无限搜索到领域约束
Yang 接着指出 theorem proving 的一个核心限制:动作空间巨大,甚至可以说近似无限。围棋虽然复杂,但棋盘和合法动作有限;数学证明中的 tactic、lemma、变形、定义展开、构造选择和中间命题几乎无穷。人类数据无法均匀覆盖这个空间,RL 探索也会变得困难。
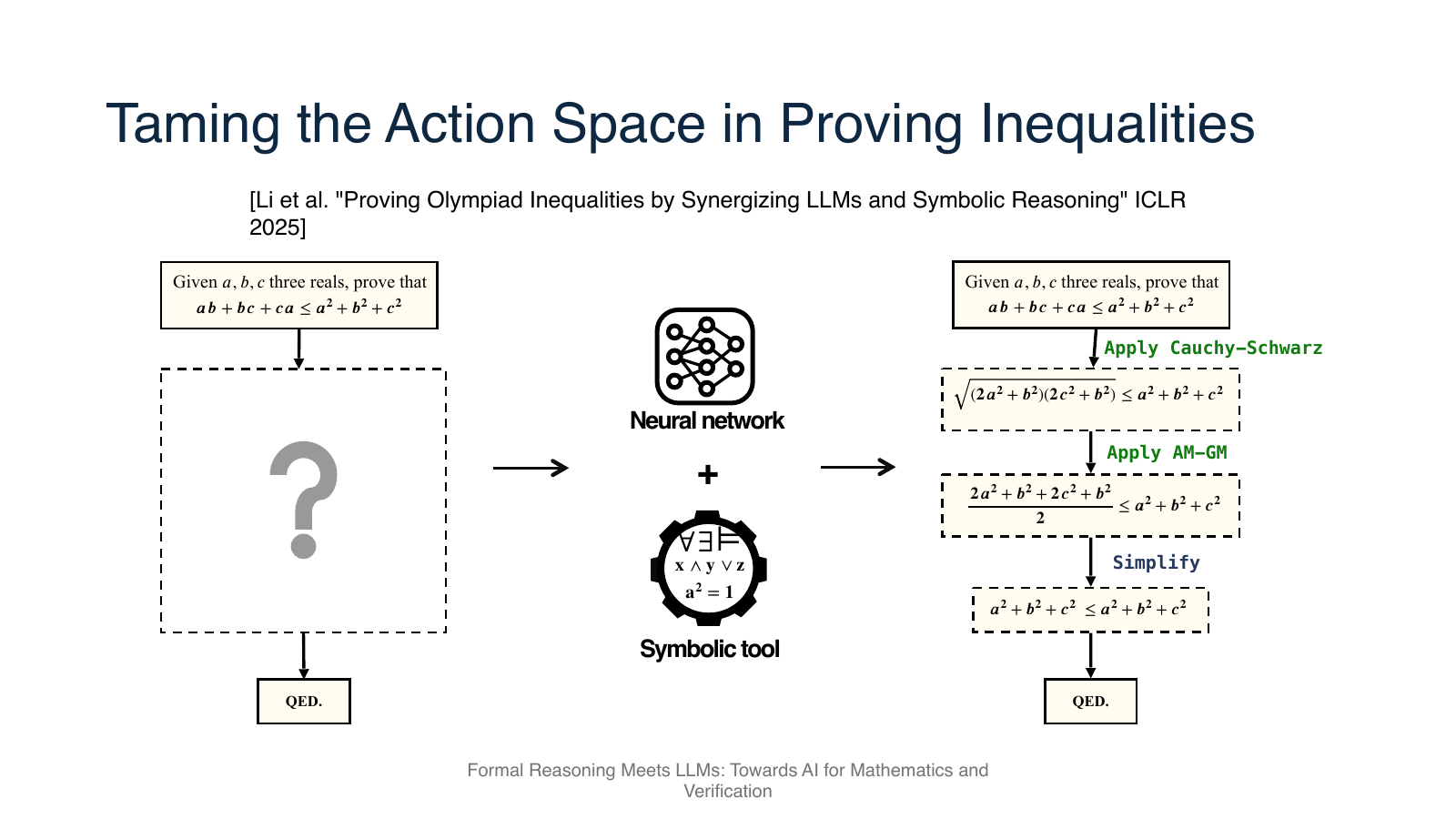
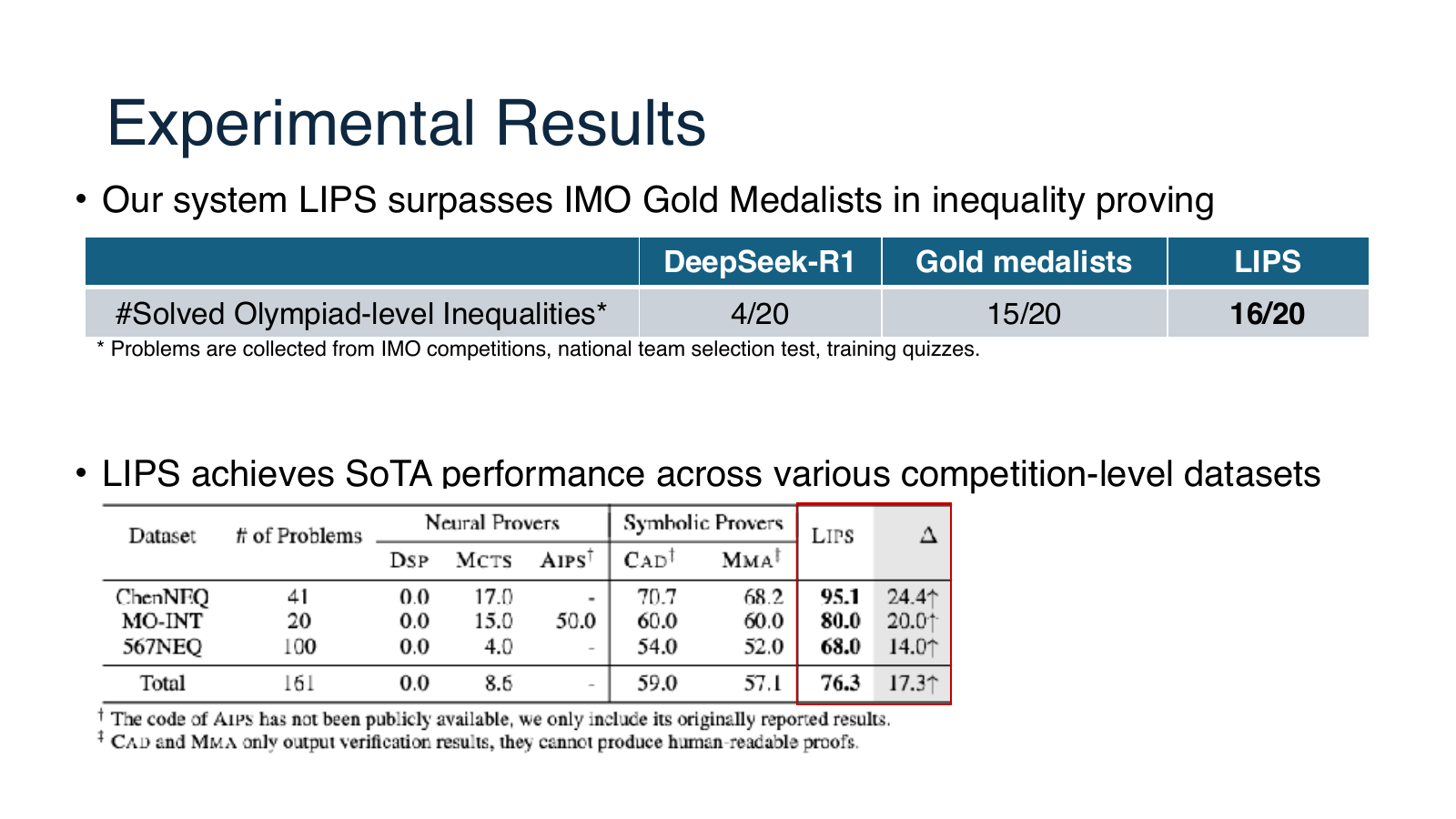
LIPS:用领域结构约束不等式证明
为了解释如何缩小动作空间,讲座介绍 LIPS,即 LLM-based Inequality Prover with Symbolic Reasoning。它面向 Olympiad-level inequalities,把不等式证明中的步骤分成更有结构的类型,例如 rewriting 和 scaling,并让 LLM 与 symbolic tools 分工:LLM 负责提出重写方向,符号工具负责缩放或验证相关变换。
本章小结
自动定理证明的难点不只是“模型聪不聪明”,还包括如何组织搜索空间。LIPS 的启发是:在特定数学领域里引入符号工具和领域动作,可以把不可搜索的问题变得可搜索。
Autoformalization:从 informal 到 formal
自动形式化是本讲后半段的重心。slides 区分了两类任务:
-
Theorem autoformalization:informal theorem \(\rightarrow\) formal theorem。
-
Proof autoformalization:informal theorem/proof + formal theorem \(\rightarrow\) formal proof。

为什么 theorem autoformalization 难评估
定理自动形式化最棘手的问题是:没有可靠自动评价。一个生成的 Lean statement 可以通过语法检查,也可能类型正确,但它是否和原始自然语言 theorem 等价,并不容易自动判断。理论上可以做 equivalence checking:证明两个 theorem 互相推出。但一般情况下这不可行,因为你又回到了 theorem proving 本身。

人工评价又昂贵,尤其当 statement 涉及复杂定义、隐含条件或领域约定时。于是 autoformalization 研究中常见的通过率、类型检查率、BLEU/相似度等指标都只能反映一部分,不足以证明忠实性。
为什么 proof autoformalization 难
proof autoformalization 的主要困难是 informal proofs 有 reasoning gaps。自然语言证明常写“显然”“类似可得”“留给读者”,也依赖读者从图形、上下文或常识补全细节。形式证明必须 gap-free,所有隐含步骤都要展开到 proof assistant 能检查的程度。
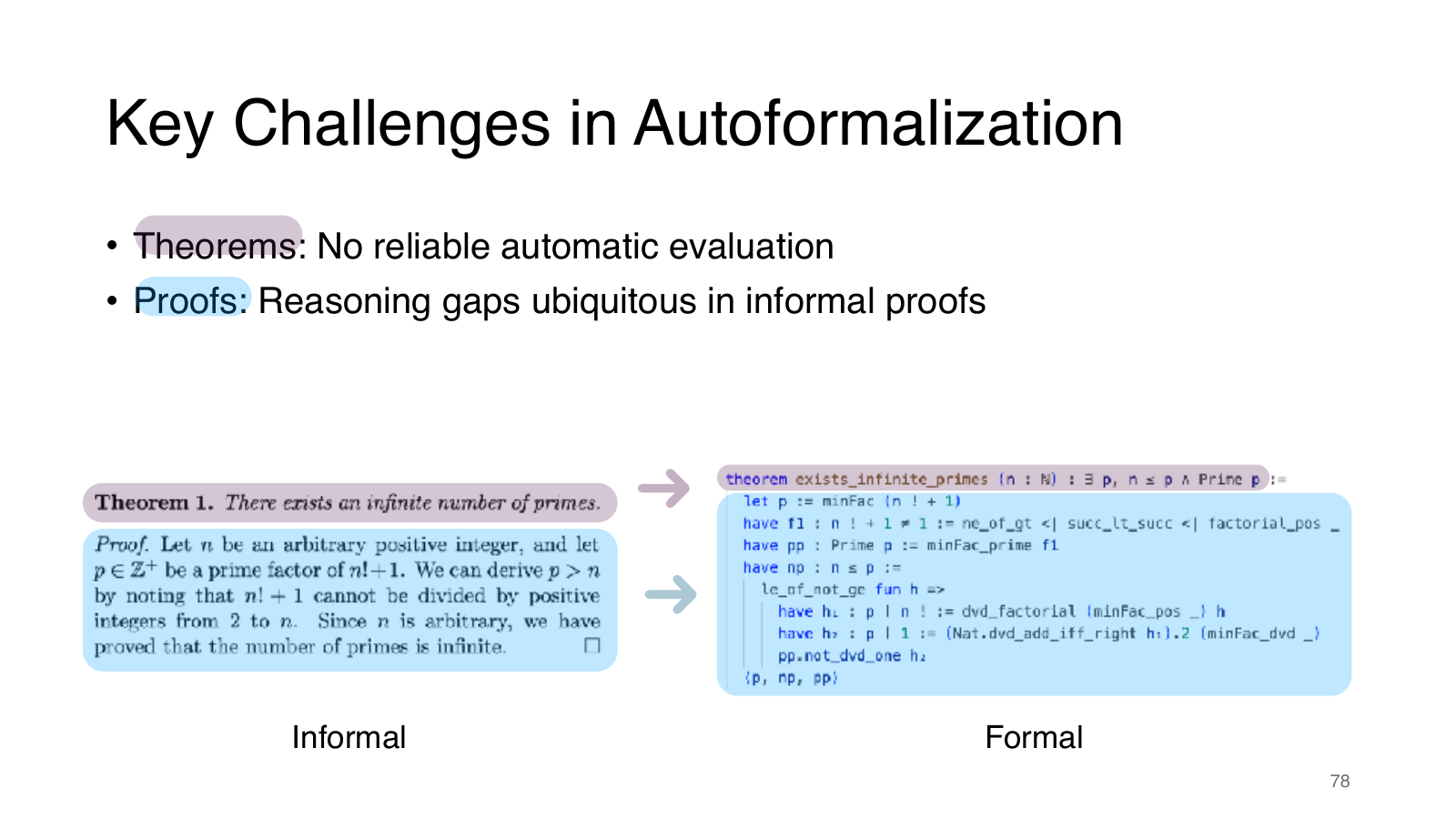
本章小结
Autoformalization 不是把英文变成 Lean 的机器翻译。它涉及语义等价、隐含条件、证明缺口、库定义选择和领域表示。它是 ATP 的前置环节,也是最容易隐藏错误的环节。
欧几里得几何:图形推理与隐含缺口
Yang 用 Euclidean geometry 展示 autoformalization 的困难,因为几何是人类和机器智能的经典 arena,也因为几何证明高度依赖 diagrammatic reasoning。讲座介绍 LeanEuclid:一个用于自动形式化欧几里得几何的 benchmark,包含来自 Euclid’s Elements 和 UniGeo 的问题。

逻辑缺口:图上看见的不等于 Lean 知道
几何证明常依赖图。人看到两个圆相交、点在某条线上、三角形方向关系,就自然补全了许多事实。但 Lean 不看图,也不会自动知道“这个点在这个区域”“这两个对象按图形位置相交”。形式化时,必须把这些关系显式写出来,或用可证明的构造替代图形直觉。
讲座用 Euclid’s Elements Book I Proposition 24 说明:非形式证明里存在多个隐含步骤,形式化时必须补出等腰三角形、角相等、角大小关系等推理。图形帮助人理解,但机器需要逻辑对象。
等价检查与符号引擎
对于几何 theorem,讲座还介绍了 theorem equivalence checking:两个 theorem 等价,当且仅当可以证明 \(T_1 \Leftrightarrow T_2\)。在特定几何设置中,可以借助 SMT solver 等符号推理引擎做一部分检查。这是把一般不可行的问题放到特定领域里变得可处理的例子。

Diagrammatic reasoning 如何形式化
slides 提到 Formal System E,用于刻画 Euclid’s Elements 中的图形推理。核心思想是:图形推理可以被当成逻辑规则建模,并与 SMT solver 结合。这样,几何图上的某些“看得见”的关系可以转化成形式系统内的可推理对象。

本章小结
欧几里得几何显示了 autoformalization 的本质困难:人类证明依赖大量未显式写出的图形事实,而形式证明要求这些事实全部进入逻辑系统。解决几何,需要把图形推理、符号推理和 Lean formalization 放在同一条管线里。
把两条线合起来
到这里,本讲的两条线可以合并:
Theorem proving 需要形式化输入;autoformalization 需要可靠评价;评价又常常需要 theorem proving 或领域符号系统。这就是为什么这个方向不能被拆成一个简单的“翻译模型”和一个“证明模型”。它更像一条闭环系统:生成、检索、证明、验证、修复互相依赖。

本章小结
本讲最后给出的 takeaways 很克制:autoformalized theorems 很难评价,autoformalizing proofs 需要填补 ubiquitous reasoning gaps;这两者可以借助特定领域知识处理,但开放问题是如何跨领域泛化。
总结与延伸
这节课的实用价值在于,它把“LLM 做数学”拆成了可操作的研究接口。SFT/RL 提供当前 math LLM 的基础;formal reasoning 提供更强验证层;LeanDojo/ReProver 展示 neural theorem prover 的数据、检索和交互结构;LIPS 展示领域约束如何缩小动作空间;autoformalization 和 LeanEuclid 展示自然语言/图形数学进入形式系统时的语义风险。
从后续工作角度,最重要的结论有五个:
-
答案可验证不是证明可验证:普通 math RL 的奖励信号不足以覆盖高级证明。
-
ATP 是系统工程:模型、检索、proof search、Lean 交互和库依赖共同决定结果。
-
动作空间必须被结构化:领域工具和符号推理能把无限搜索空间变窄。
-
Autoformalization 的核心是忠实性:可编译 statement 不是成功,语义等价才是关键。
-
几何暴露了隐含推理:diagrammatic reasoning 是从人类证明到形式证明时必须处理的难点。
建议继续追踪的问题
-
如何构造比 type-check 更强、比人工评审更便宜的 autoformalization 评价?
-
ReProver 式 premise retrieval 在不同数学领域的瓶颈是什么?
-
LIPS 的领域动作分解能否迁移到组合、数论、拓扑等领域?
-
几何中的 diagrammatic reasoning 能否作为多模态 formal reasoning 的通用测试场?
-
AlphaProof 的 test-time RL 如何和本讲的 LeanDojo/ReProver/autoformalization 管线合并?
拓展阅读
-
课程主页:Berkeley CS294/194-280 Advanced Large Language Model Agents, Spring 2025
-
讲座 slides:Formal Reasoning Meets LLMs: Towards AI for Mathematics and Verification
作者线:cnfjlhj & Codex。内容依据 Berkeley CS294/194-280 Advanced Large Language Model Agents, Spring 2025 的公开课程视频、slides 以及本地生成的 PDF/TeX 学习笔记整理。