
问题框架:什么才算 AI 自我修正?
本节的核心问题不是“语言模型在被人指出错误之后能不能改”,而是更严格的版本:模型输出答案之后,能不能在没有人类额外指出错误的情况下,自己发现问题并修正输出。课程把这个问题放在三个层次里讨论:
- Decoding 层:不改模型参数,只在输出 token 时修改概率分布,让模型远离看起来像错误的状态。
- Workflow 层:让模型先生成答案,再自动插入一个泛用的 verification/reflection 指令,让模型检查并修正。
- Reasoning/RL 层:训练模型,让它在推理过程中自然地产生验证、反思和修正行为。
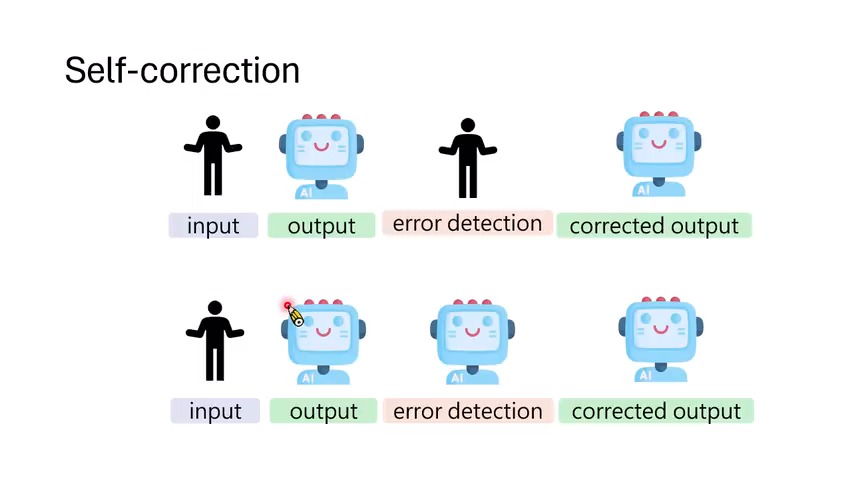
课程开头强调了一个关键差异:人在环路中的纠错和模型自发纠错不是一回事。如果人类告诉模型“你错了,错在这里”,模型能改是比较容易的;真正有研究价值的是,能不能用模型内部信号、自动 workflow 或训练机制,让模型自己触发这个过程。
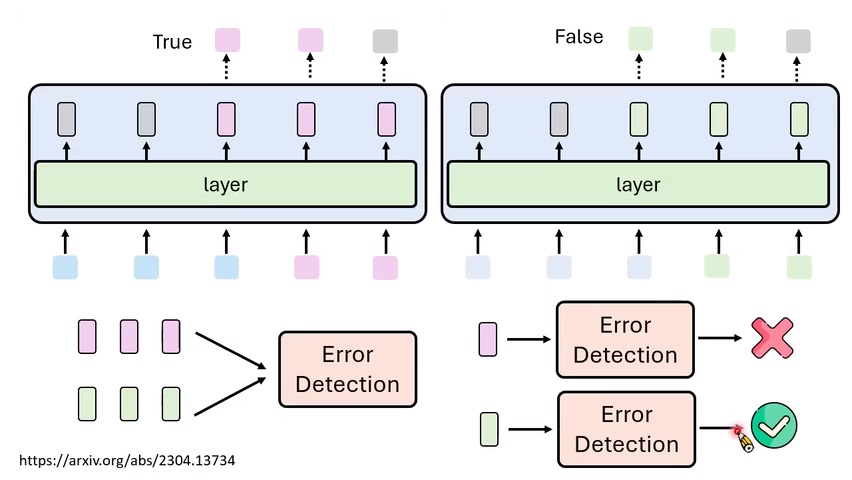
早期直觉:错误状态能不能从内部表示看出来?
开头部分提到,早期工作尝试观察模型在答对与答错时的内部 representation 是否有差异:如果模型处于“答错状态”,某些中间层表征或 logits 分布可能和答对状态不同。这样就出现了一个很自然的思路:
- 如果我们能识别出“错误状态”的表示,就能做 error detection。
- 如果我们能把输出从错误状态推开,就能做 error correction。
- 这种方法不一定需要重新训练模型,只需要在推理时改变输出概率或中间表示。
本章小结
本节课的主线是从“输出时干预”走向“流程上检查”,再走向“训练出内生推理”。三条路线都可以被称为自我修正,但它们的强度不同:decoding 是外部算法在帮模型改分布,workflow 是程序自动要求模型再检查,reasoning/RL 则试图让模型自己学会什么时候检查、什么时候停止。
路线一:从 Contrastive Decoding 开始的输出分布修正
Contrastive Decoding 的核心想法是:既然模型在好状态和坏状态下会给出不同的 token 分布,就可以把“坏状态偏好的 token”从“正常状态偏好的 token”里减掉。它不是让模型重新学习知识,而是在解码时重新排序下一步 token 的分数。
可以把这种方法写成一个统一形式。对候选 token \(v\),令正常路径给出的概率为 \(p_{\text{good}}\),坏路径或弱路径给出的概率为 \(p_{\text{bad}}\),则修正后的分数可以写成:
- \(s_t(v)\):第 \(t\) 步候选 token \(v\) 的修正后分数。
- \(x\):正常输入或完整上下文。
- \(\tilde{x}\):被破坏、弱化或去掉关键信息后的输入。
- \(y_{<t}\):第 \(t\) 步之前已经生成的 token。
- \(\alpha\):减去坏路径分布的强度;太小修正不明显,太大可能把有用信号也减掉。
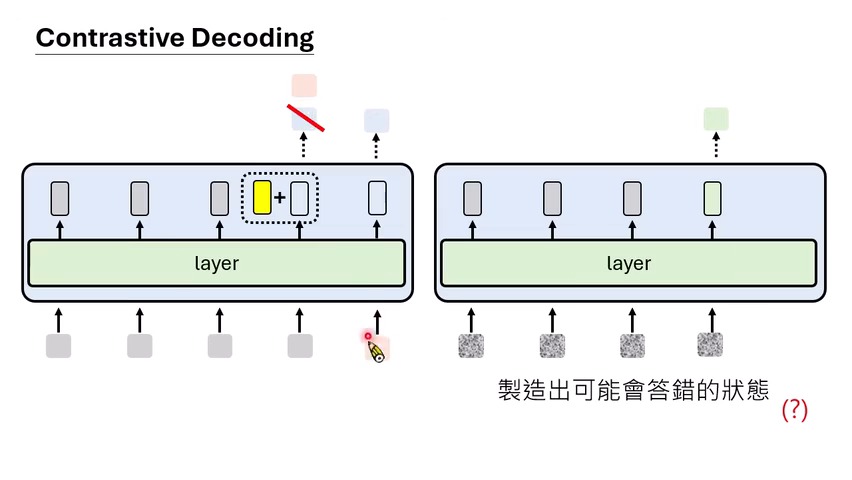
Expert vs Amateur:从大模型和小模型的差异开始
课程提到,最早的 contrastive decoding 直觉可以理解为“expert model 减 amateur model”。大模型和小模型都可能会给某些常见词高概率,但小模型更容易走向低质量或幻觉答案。把小模型分布作为负项减掉,就能凸显大模型特有的、更可靠的偏好。
DoLa:用不同层的分布做对比
DoLa(Decoding by Contrasting Layers)的思路是,不一定要用两个模型做对比,也可以在同一个模型的不同层之间做对比。浅层或中间层可能还没有完整整合事实和语义,最终层则包含更成熟的判断。用最终层分布减去较浅层分布,就相当于把“不成熟的早期猜测”压低。
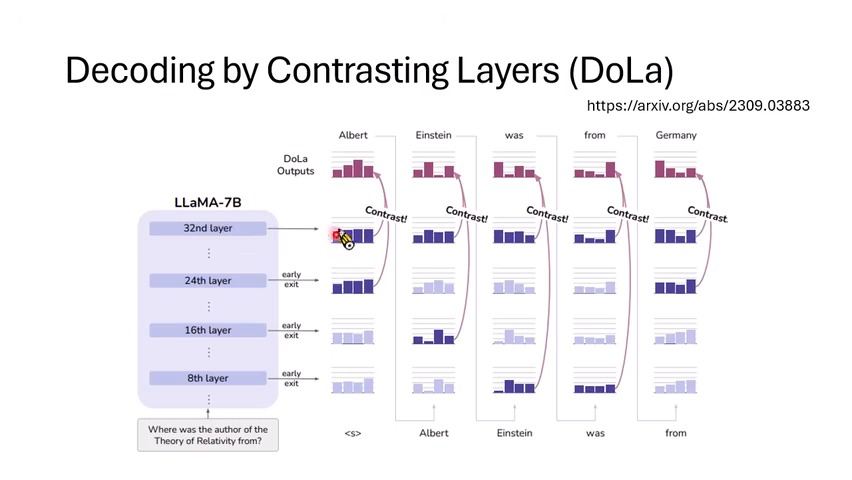
这类方法的价值在于它不依赖另一个外部模型,也不需要重新训练;但它也引出一个问题:到底哪一层是“坏来源”,哪一层是“好来源”,并没有对所有任务都稳定成立。
多模态与上下文版本:LayerCD、ICD、CAD、VCD、Audio-Aware Decoding
课程随后把这个范式扩展到更多场景:
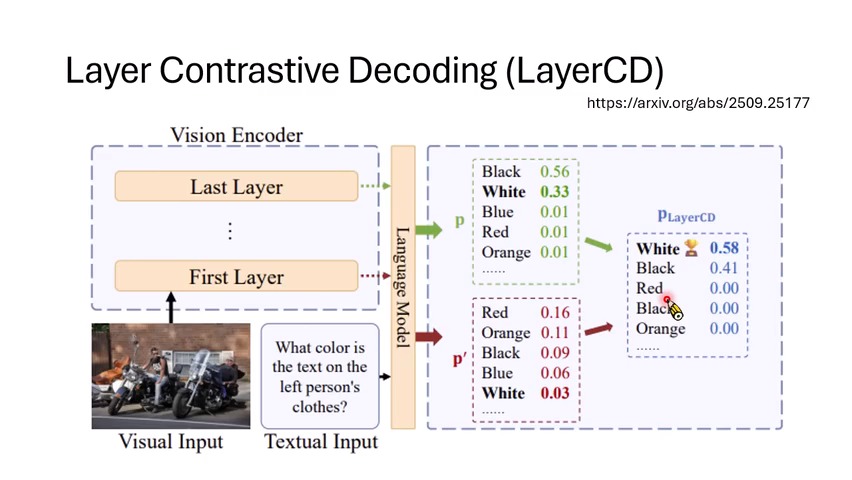
- Layer Contrastive Decoding:在视觉语言模型里,对比 vision encoder 不同层的表示,抑制由不充分视觉理解带来的错误 token。
- Instruction Contrastive Decoding:对比不同 instruction 条件下的输出,让模型避开不符合目标指令的模式。
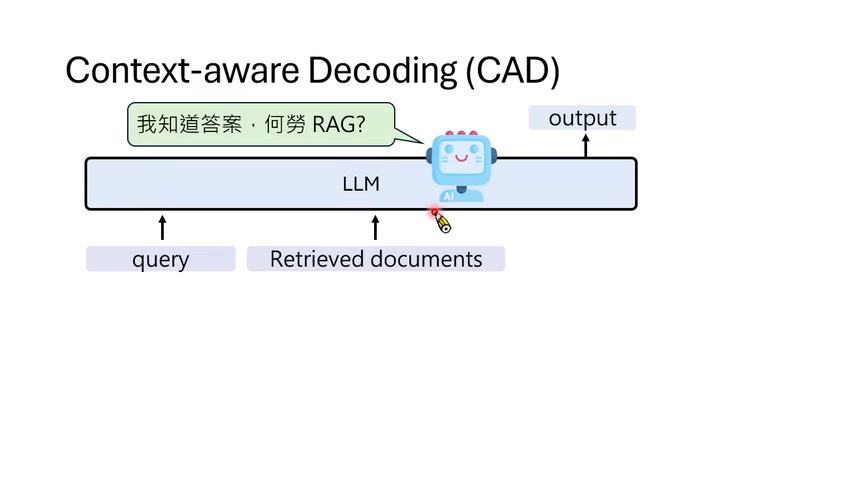
- Context-Aware Decoding:在 RAG 场景里,对比“有检索文档”和“没有检索文档”的分布,强调真正由上下文支持的 token。
- Visual Contrastive Decoding:在图像问答中,对比干净图像和被遮挡、加噪或弱化后的图像,减少视觉幻觉。
- Audio-Aware Decoding:在语音或音频理解里,对比有音频和静音/噪声条件下的分布。
MTI:只在关键 token 做干预
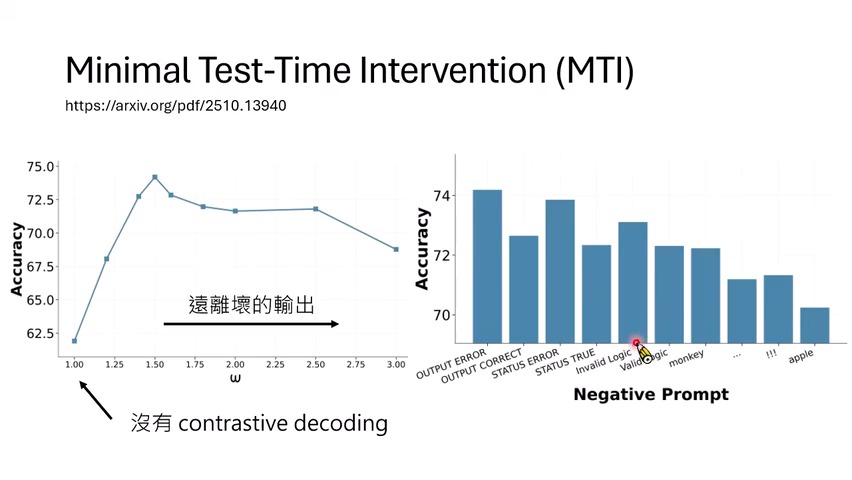
传统 Contrastive Decoding 需要在每一个生成步骤都跑一次好路径和坏路径,成本很高。Minimal Test-Time Intervention(MTI)提出:能不能只在关键位置启动对比?课程给了一个很直观的标准:当下一 token 分布 entropy 很高、模型很不确定时,这个位置可能就是关键岔路。
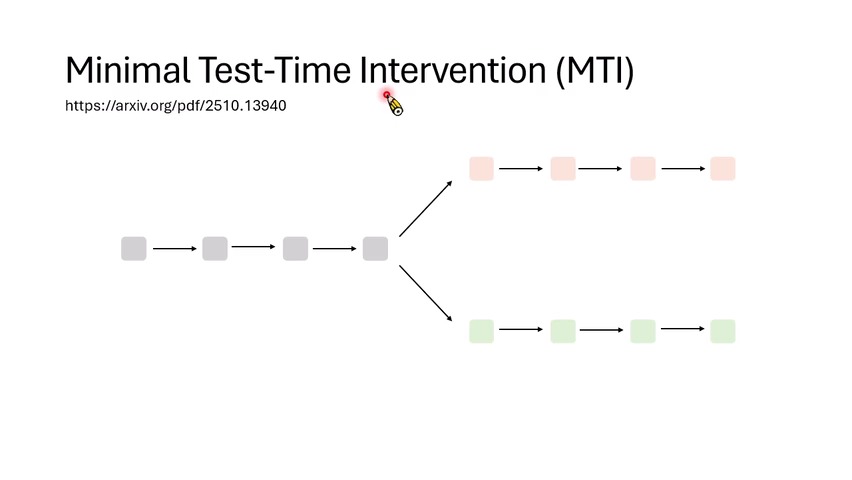
但课程马上指出一个陷阱:如果为了得到坏路径分布,仍然要从头跑完整个坏输入序列,那么只在少数
token 干预并不一定省算力。MTI 的关键工程点是利用 KV
cache。它不在输入前面大幅破坏内容,而是在当前生成位置后面追加很短的负向提示,例如
Output Error,这样前缀的 KV cache
可以复用,额外计算只发生在少数新增 token 上。
Decoding 家族的共同局限
课程在第一部分末尾用表格总结了不同方法:有的改 logits,有的改 representation,有的改 attention;有的负来源来自弱模型,有的来自浅层,有的来自缺失上下文或加噪输入。

这一类方法的优点是无需训练,试错成本低;缺点是它仍然是外部算法在替模型修正,而不是模型真正理解了何时该反思。对任务有效与否,很依赖坏来源构造是否合理、超参数是否合适、以及额外计算是否可接受。
本章小结
Contrastive Decoding 家族把自我修正问题转化为“从坏分布里减掉错误倾向”。它适合在不训练模型的情况下快速尝试,也适合解释很多多模态幻觉抑制方法。但它没有解决最深层的问题:模型是否真的知道自己错了?它更多是在利用分布差异做 test-time correction。
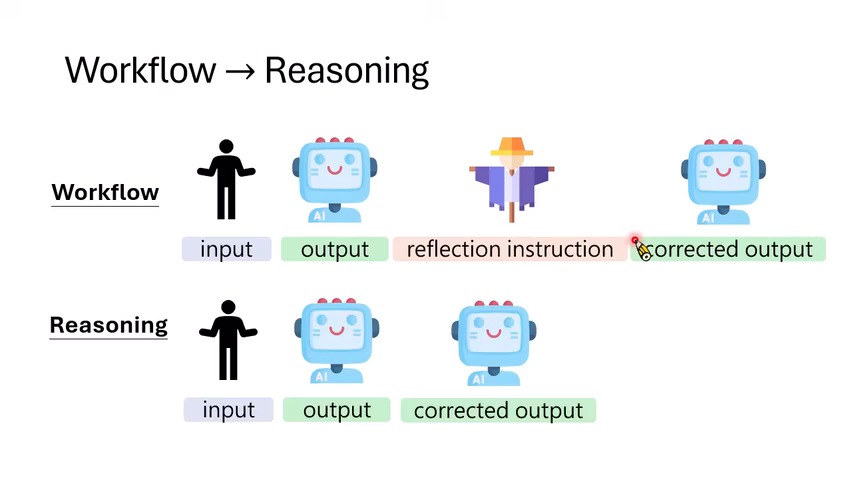
路线二:Workflow 中的 Generation \(\rightarrow\) Verification
第二条路线不直接改 logits,而是在流程上加一个自动检查步骤。模型先生成答案,然后系统自动插入一个泛用的 reflection instruction,例如“再检查一下”“你确定吗”“请修正你的答案”。因为这个指令可以由程序自动插入,不需要人类针对具体错误写反馈,所以课程仍然把它归入自动自我修正的范畴。

为什么 verification 可能有用?
课程给了两个直觉解释:
- 批判可能比生成容易:不会写小说的人仍可能判断小说好不好。类似地,模型第一次生成时没发现错误,但回头检查时可能更容易发现。
- 生成过程无法回头:一旦前面的 token 错了,后续生成常常会沿着错答案硬编下去。插入“再检查一下”相当于给模型一个语境切换点,让它有机会从原来的错误轨道跳出来。
但课程也提醒,这些只是人类直觉,不一定适用于语言模型。有些研究发现,模型做“选择哪个答案更好”的能力并不一定比生成能力强;反过来,这类实验本身也可能受选择题格式、模型指令遵循能力等因素影响。
实证结果:内部反思不稳定,外部反馈更可靠
大规模实验显示,纯 internal self-reflection 有时有用,但并不稳定。有些模型或任务在反思后变好,有些反而变差。External feedback,例如执行代码得到错误信息、联网检索、checklist、人工或外部系统反馈,通常更稳定。
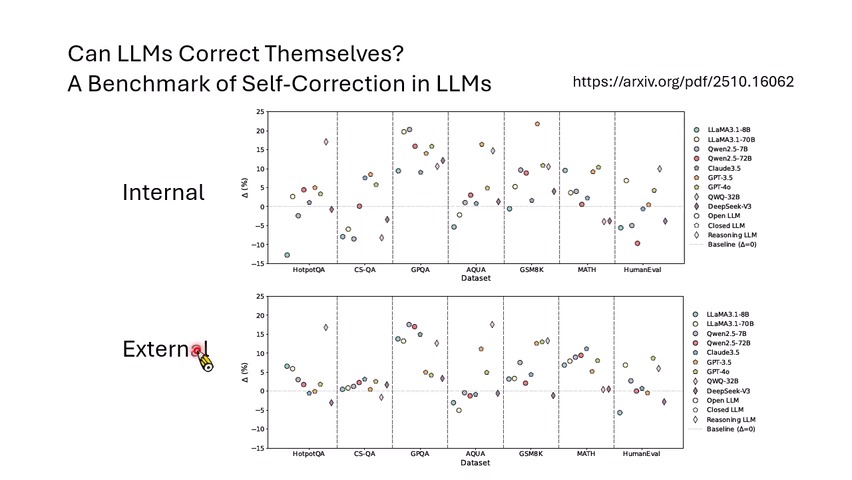
诊断自我修正:四种结果、CL 与 CS
课程介绍了一套分析模型修正行为的框架。一次反思前后有四种结果:
- 错 \(\rightarrow\) 对:最理想,说明模型接受批判并修正。
- 对 \(\rightarrow\) 对:不坏,但消耗算力。
- 错 \(\rightarrow\) 错:没有改善,也消耗算力。
- 对 \(\rightarrow\) 错:最糟,模型想太多把正确答案改坏。
论文中定义了两个指标:
- \(\mathrm{ACC}_1\):反思前准确率。
- \(\mathrm{ACC}_2\):反思后准确率。
- \(\mathrm{CL}\):Confidence Level,即本来答对时,反思后仍保持正确的概率。
- \(\mathrm{CS}\):Critic Score,即本来答错时,反思后改对的概率。

Reflection instruction 本身很关键
同一个模型,在不同反思指令下可能表现出不同性格。中性指令只是让它再做一次;肯定性指令会提高 CL、让模型更固执;批判性指令会提高 CS、让模型更愿意修改。不同论文使用的反思提示不同,可能是文献结论混杂的重要原因。
算力视角:verification 像奢侈品
课程随后引入一个更尖锐的问题:同样的额外算力,用来让模型反思旧答案,还是用来多 sample 几个新答案再 majority vote,哪个更划算?
实验证据显示,如果横轴只看 sample 数,加 reflection 看起来有提升;但如果横轴换成实际 inference compute budget,在预算有限时,多采样加投票往往更划算。只有当多采样已经接近饱和,继续增加样本不再有效时,额外 verification 才可能发挥作用。
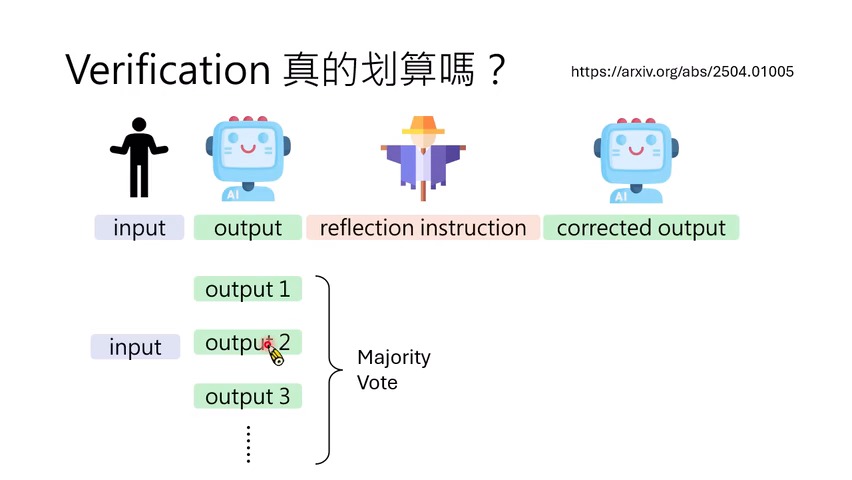
本章小结
Workflow 让模型看起来会自我反思,但它不是稳定魔法。内部反思有时有效,外部反馈更可靠;反思提示会改变模型行为;最重要的是,verification 必须和同等算力的多采样 baseline 比较。只有在多采样收益饱和后,verification 才更像值得追加的高级策略。
路线三:从 Workflow 走向 Reasoning 与训练
Workflow 的缺点是每次都要硬插一个反思指令。即使答案本来对,模型也要多生成一段检查内容,浪费 token。Reasoning 路线希望模型学会:该修时修,不该修时停。
知识不等于自我修正
课程用 Hillary Clinton 的例子说明:模型可能知道某个事实,却不能在另一个问题里利用这个事实纠正自己。自我修正不是知识量的直接函数,而可能是一种独立状态或能力。某些工作甚至把“自我修正状态”抽成 steering vector,加到模型中会让模型在不需要修正时也倾向于修正。
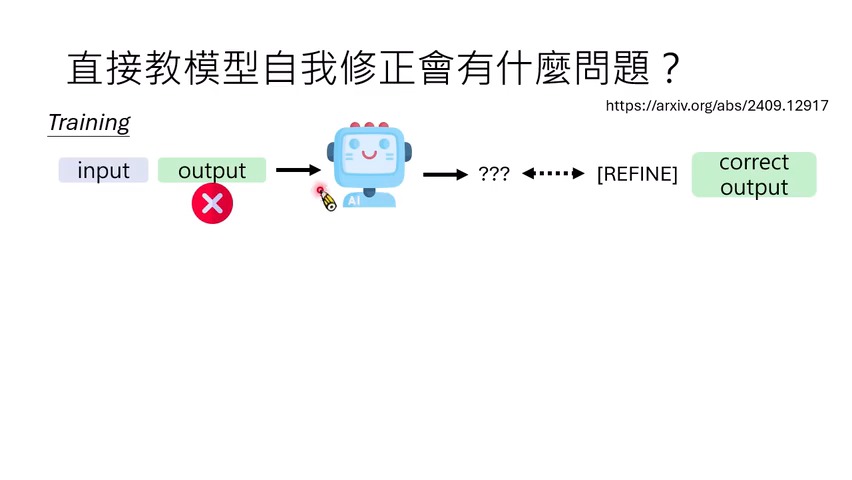
直接训练自我修正:先侦测,再修正
课程介绍的 refine 类方法把自我修正拆成两步训练:
-
错误侦测:模型看到自己的输出,如果发现错误,就输出一个
refinetoken;如果答案已经正确,就输出结束符号。 -
错误修正:当输入、原错误输出和
refinetoken 都出现时,模型学习输出正确答案。
这种分解比把“侦测+修正”一次性学起来更容易。但课程也指出一个关键问题:fine-tune 之后模型参数变了,它在 inference 时犯的错误也可能变了。训练时见过的“绿色错误”能修,参数改变后出现的“红色错误”未必能修。
RLVR:只奖励最终答案,让修正行为自然出现
因此更常见的路线是 Reinforcement Learning with Verifiable Reward(RLVR)。模型面对输入后可以生成一长串 reasoning tokens;过程不直接监督,只看最终答案是否正确。数学和编程任务特别适合这类训练,因为最终答案或程序运行结果可验证。
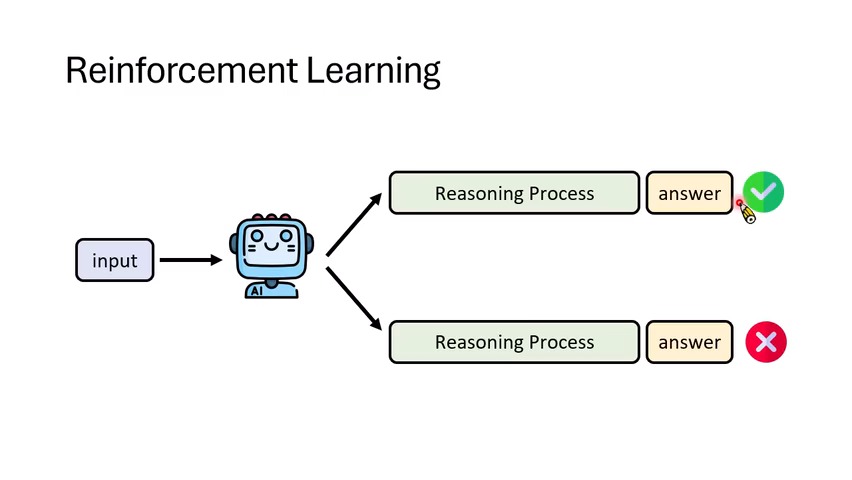
有趣的是,虽然训练只奖励最终答案,但模型在 reasoning 中会自然出现“先提出一个答案、再检查、发现不对、再修正”的行为。课程把这看成 self-correction 可能从 reasoning 过程中涌现的证据。
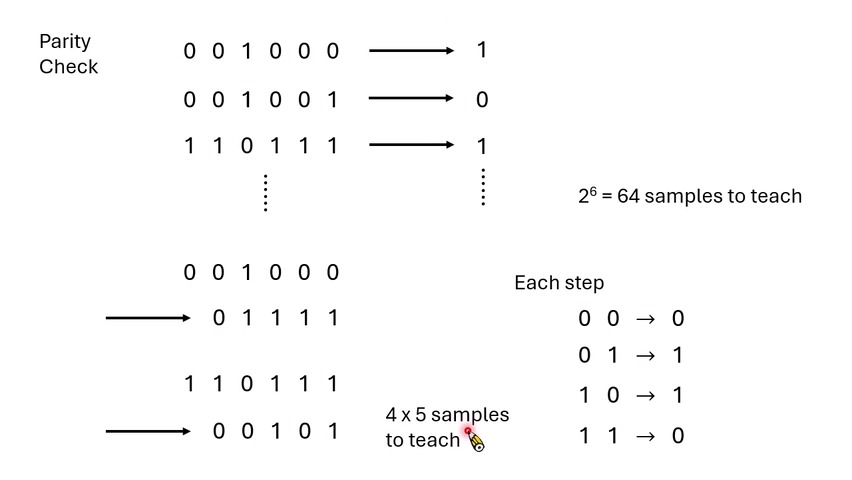
Reasoning 的样本效率:Parity Check 例子
课程给出一个 sample-complexity 直觉:如果要求模型一步从输入直接映射到答案,输入和输出的组合可能指数增长;如果把问题拆成多个步骤,每个步骤只需要学一个小操作,总数据需求可能大幅下降。
对 parity check,长度为 6 的二进制串有 \(2^6=64\) 种输入。如果模型只会死记硬背,必须看过 64 种情况。但如果把任务拆成逐步 XOR,每步只需要学会四种局部规则:
长度 6 的序列只需 5 步,每步 4 种局部变化,所以大约 \(4\times5=20\) 个局部样本就能教会这种过程。
本章小结
Reasoning 路线比 workflow 更强,因为它试图把“何时检查、何时修正”内化到模型生成过程中。直接训练 refine token 会遇到分布漂移问题,RLVR 则用最终可验证 reward 训练完整生成过程,让 verification/reflection 行为在 reasoning 中自然出现。
最终争论:RL 创造了新能力,还是只提高了旧路径概率?
课程最后把问题推向当前研究争论:RL 让模型学到了新的 reasoning 能力吗?还是 base model 本来就能走出正确路径,只是概率太低,RL 只是把这些路径的概率提高?
观点一:Base model 本来就可能 sample 到正确路径
一种证据来自 pass@k:如果同一道题让模型 sample 很多次,只要其中一次答对就算通过,那么没有做 RL 的 base model 在 \(k\) 很大时也可能接近 RL 模型。这支持一种解释:正确 reasoning path 早就存在,只是概率低;RL 主要是在重排路径概率。
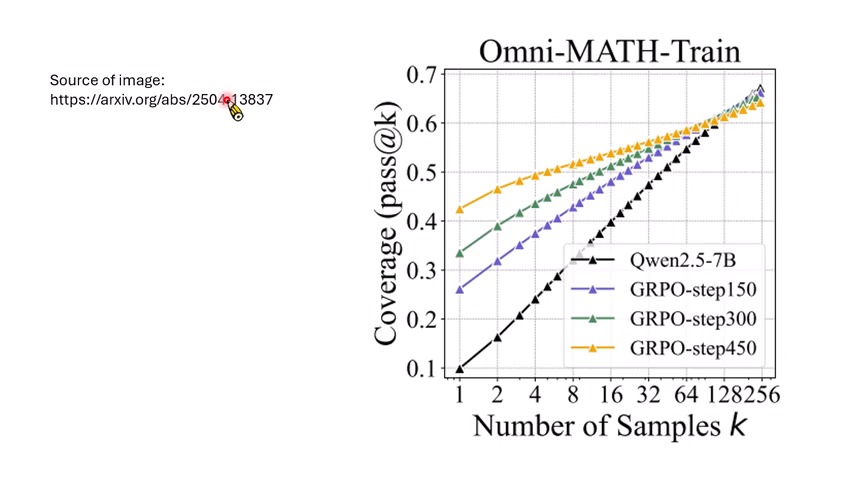
这一观点自然引出 training-free sampling:如果正确路径本来就在分布里,那么也许不训练,只改 sampling 策略,就能逼出模型已有的 reasoning 能力。课程提到有工作确实用更复杂的 sampling 方法逼近甚至部分超过 RL 结果。
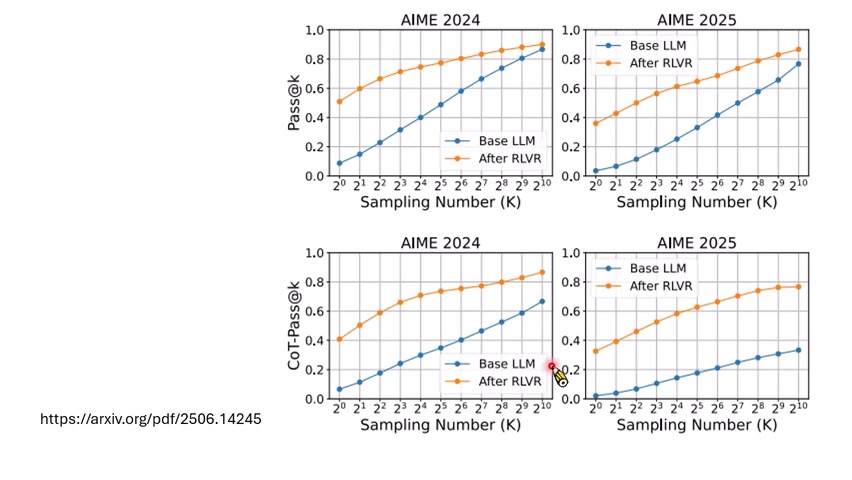
观点二:RL 可能确实教会了新的能力
另一派认为,只看最终答案是否正确不够。sample 很多次可能只是猜中答案,尤其当答案空间有限时。于是有研究提出不仅检查最终答案,还检查 chain-of-thought 计算过程,即类似 CoT-pass 的标准。如果计算过程也必须正确,那么没有 RL 的模型就明显落后于有 RL 的模型。
课程给出的保守结论
课程最后给出的结论不是简单站队,而是“两者都有可能”:
- 在 RL 训练初期,模型可能主要是在提高已有正确路径的概率。
- 在训练足够久、reward signal 合适时,模型也可能展现出新的能力。
- 真正关键的问题变成:什么样的 RL 算法和 reward signal 更容易激发新能力,而不是只重排旧路径。
本章小结
自我修正研究已经从“让模型再想一次”推进到更细的问题:正确路径是否已在 base model 分布中、RL 是否只改变概率、过程正确性如何评价、reward signal 如何设计。课程的价值在于把看似分散的 decoding、workflow、reasoning 文献,放进同一条技术发展线里。
学习路线与复习问题
一页复习图
| 层次 | 核心机制 | 主要风险 |
|---|---|---|
| Decoding | 构造好分布与坏分布,解码时做对比,代表方法包括 CD、DoLa、CAD、VCD、MTI。 | 负来源构造不当会无效;额外计算成本可能高;不代表模型真正理解错误。 |
| Workflow | 生成后自动插入 verification/reflection 指令,要求模型检查或修正。 | 内部反思不稳定;提示词会改变行为;同等算力下可能不如 majority vote。 |
| Reasoning/RL | 用可验证 reward 训练完整推理过程,让检查和修正在 reasoning 中自然出现。 | 训练成本高;过程是否真的正确难评价;RL 到底产生新能力还是重排旧能力仍有争议。 |
复习问题
- 为什么“模型知道正确事实”不等于“模型会自我修正”?
- Contrastive Decoding 中的“坏分布”可以从哪些来源构造?这些来源各有什么风险?
- MTI 为什么要考虑 KV cache?如果只在少数 token 做 contrastive decoding,为什么不一定省算力?
- CL 和 CS 分别衡量模型的什么行为?为什么二者可能存在 tradeoff?
- 为什么 workflow 方法必须和同等算力的 majority vote 比较?
- RLVR 为什么适合数学和编程?它为什么可能自然地产生 verification 行为?
- Pass@k 能说明 base model 有 reasoning 能力吗?为什么还需要检查过程正确性?
本章小结
学习这节课时,最重要的是不要把“自我修正”当成单一能力。它是一组机制的组合:错误可检测性、错误可修正性、何时触发修正、修正是否划算、以及训练是否让这些行为内化。把这几层拆开,才能看懂相关论文为什么经常得出看似矛盾的结论。
总结与延伸
这节课的主线可以压缩成一句话:AI 自我修正不是一个按钮,而是一条从 test-time decoding 到 agentic workflow,再到 RL-trained reasoning 的技术谱系。
课程的三个面向分别回答了三个问题:
- 如果不训练,能不能让输出更正确? Contrastive Decoding 家族回答“可以尝试”,前提是能构造有意义的对比分布。
- 如果让模型再检查一次,是否就能自我修正? Workflow 文献回答“有时可以,但不稳定,而且要和同等算力 baseline 比较”。
- 如果训练模型做 reasoning,会不会自然学会反思? RLVR 文献回答“可能会”,但现在仍在争论这是新能力还是旧路径概率提升。
对实践者来说,最稳妥的策略不是盲目相信“请你反思一下”,而是按成本和可靠性选择层次:
- 低成本尝试:用 contrastive decoding 或简单多采样检查是否有明显收益。
- 需要可靠性:优先引入外部反馈,例如工具执行、检索、unit test、checklist 或 verifier。
- 预算充足且任务可验证:考虑 RLVR 或专门训练,让模型把 verification/refinement 行为内化。
课程最后的开放问题也值得保留:什么样的 reward signal 能真正激发新能力?什么样的过程验证才可信?怎样区分“模型本来会,只是低概率”与“训练后真的学会了”?这些问题仍然是 self-correction 和 reasoning 研究的前沿。
Source / Evidence. 本页依据公开源视频整理为 HTML 讲义;正文保持讲义内容,不额外伪造视频中不存在的信息。源视频:https://b23.tv/3hOmntL
另有 PDF 讲义版本 可作为离线阅读参考。