材料边界与阅读路线
证据边界
这份讲义的目标是把 2026 智源大会"AI 自进化 / AI with
RSI"论坛整理成可独立阅读、可转发给他人的学习材料。它不是逐字稿,也不是只保留观点的短摘要,而是按"视频证据
-> 分段内容复原 -> 教学解释 -> 全局综合"的方式重建整场论坛。
本讲义使用四类证据:
视频证据 :source/replay.mp4,画面含现场幻灯片、嘉宾发言与烧录在画面底部的讯飞同传字幕。
ASR 底稿 :work/focus_asr/*_abs.txt,按章节切分并带绝对时间戳。ASR
负责保证覆盖率,但其中有术语误识别。
关键帧 :work/selected_frames/ 与
work/full_selected_frames/,用于保留现场幻灯片中的架构图、表格、公式、流程图和圆桌场景。
外部补充 :work/references/external_sources.md
中记录的官方页面、arXiv、作者主页等,用于校正论文名、方法名和背景,不替代现场内容。
烧录字幕不是外挂字幕
平台播放器没有暴露独立字幕轨。浏览器中没有可直接读取的
textTracks,也没有外挂 srt 或
vtt。所谓"讯飞同传字幕"是烧录在视频像素里的字幕。因此,讲义不能简单导入字幕文件,而是以
ASR 和关键帧为主,再用画面字幕抽样核对术语。
ASR 术语误识别的处理
ASR 中常见误识别包括:Cloud Code 应读作 Claude
Code,contacts 多数应读作 context,word knowledge
多数应读作 world knowledge,DeepSig/DeepSeq
多数应读作 DeepSeek,IAL 多数应读作
RL。人名也会有误识别,因此讲者姓名以官方议程和现场幻灯片为准。
整场议程
时间
讲者
主题
00:00:02--00:15:07
诸葛鸣晨
论坛与嘉宾介绍:Recursive Self-Improvement 的问题边界
00:15:07--00:49:32
刘泽春
Scaling Down: Optimizing Foundation Models for Edge
Deployment
00:49:32--01:19:14
张少坤
基于可扩展智能体经验的递归自学习
01:19:14--01:46:55
谷雨
The Illusion of Self-Improving Agents
01:46:55--02:11:22
林涛
面向自进化统一多模态模型:少步生成与智能体式理解
02:11:22--02:40:00
王琰
Empowering LLMs with More Agency: From Context Engineering
to Self-Engineering Architectures
02:40:00--03:08:12
杨梦月
开放场景下的因果世界理解:从表征学习到持续性自主优化
03:08:12--03:29:16
郑侠武
From Benchmarking to Self-Improvement: Building Verifiable
Feedback Loops for Abstract Reasoning
03:29:16--04:27:53
圆桌讨论
觉醒与进化:AI 如何自我迭代?
主线导图
这场论坛虽然讲者很多,但并不是松散拼盘。它围绕"AI
怎样从被动训练走向自我驱动的持续改进"展开,形成了八条互相咬合的主线。
整场论坛的八条主线
第一,RSI
需要从形式化自我改写降落到可实验、可评估的工程闭环。第二,闭环要跑得起来,需要压缩、量化、小模型和端侧部署。第三,agent
要从自己的经验学习,需要可扩展 rollout
基础设施。第四,学习不是写几条 markdown 记忆,而是稳定更新
memory。第五,多模态模型要自进化,需要理解、想象、行动和反馈共用一个状态。第六,LLM
要更有 agency,需要从 context engineering 走向
self-engineering。第七,开放世界中的自进化要有因果世界模型。第八,自进化是否真的发生,必须通过可验证、可持续、会随能力升级的反馈闭环来判断。
诸葛鸣晨开场:给 RSI 设定问题边界
为什么从 Recursive Self-Improvement 开始
开场不是普通主持串场,而是在给整场论坛定义共同语言。诸葛鸣晨把论坛主题定位为
AI 自进化,也就是 Recursive Self-Improvement,简称 RSI。他强调 RSI
很有潜力,但如果没有定义、历史脉络、工程边界和评估机制,讨论很容易滑向口号。
论坛主题页:AI 自进化与 Recursive Self-Improvement 00:00:03
论坛主席与主持人介绍页 00:00:30
他的个人背景也与论坛主题有关:他是 Recursive
公司的创始成员,博士毕业于 KAUST,导师是 Juergen
Schmidhuber。这个背景把讨论连接到 Gödel
Machine、神经计算机、代码智能体和递归自我改进这些长期线索。
开场最重要的概念区分,是 Formal RSI 与 Empirical RSI。Formal RSI
更接近 Schmidhuber 的 Gödel Machine
传统。严格版本要求系统能够访问自身描述,生成自我修改候选,用形式化证明说明新版本更优,把自身替换为被证明更好的版本,并持续重复这个闭环。
Empirical RSI
是现实工程中更可能先落地的版本。系统状态可以是代码仓库、智能体框架、训练流程、评估环境或一套基础设施。系统生成候选版本,再通过
benchmark、测试、真实环境反馈或人类评价筛选更好的候选,然后迭代。
Formal RSI 与 Empirical RSI 的对照 00:02:30
经验改进不是形式证明
Empirical RSI
的核心是"用实验选择更好的候选",不是"证明下一版一定更好"。后面关于
benchmark、reward hacking、closed-loop validation
的所有讨论,本质上都在补偿 Empirical RSI 缺少形式保证的问题。
为什么 2025 以后 RSI 重新变得可讨论
RSI 不是新概念。开场回顾了 Schmidhuber 对 self-improving AI
的长期目标,也说明 Gödel Machine
很早就给出过形式化表达。真正变化的是:模型代码能力、智能体工具链、评估平台和自动化实验基础设施在最近几年同时变强。
Schmidhuber 关于 self-improving AI 的长期目标 00:04:30
模型代码能力进入可讨论 RSI 的临界点 00:07:30
当代码智能体不仅能执行任务,还能修改工具链、工作流、测试和数据回流路径时,RSI
就不再只是哲学设想。它变成一个工程问题:系统到底能改哪一层?谁来评估改得好不好?如何防止系统学会操纵评估?
把智能体组织形式化为图
开场用图结构理解 agent 和 organization。单个 agent 不是一个
prompt,而是由多个 operation/function node 组成的图;多个 agent
协作时,本质上是多个图之间的信息流。所谓
orchestration,就是决定这些节点和边如何连接。
把 agent 与 organization 表示为 graph of nodes/edges 00:08:30
为什么图表示重要
如果 agent 只是一个黑盒 prompt,那么改进只能靠经验性的 prompt
rewrite。若 agent
被表示为节点和边的组织结构,优化就能落到具体位置:换哪个工具、改哪条信息流、调整哪个中间反馈、拆分哪个子任务、增加哪类验证。
RSI 中必须关注评估机制与 reward hacking 00:09:30
本节小结
开场给后续报告留下三个问题:第一,现实 RSI
大概率先是经验闭环,而不是形式证明闭环;第二,agent
的结构、工具、工作流、memory
和模型权重都可能成为被改进对象;第三,只要系统能自我修改,评估就不是尾部打分,而是防止系统自欺和
reward hacking 的核心机制。
刘泽春:Scaling Down 与端侧自进化的计算底座
为什么自进化首先需要高效模型
刘泽春的报告从一个很直接的判断开始:Recursive AI 需要很多
iteration。如果每次迭代都很贵,系统就无法进行足够多的试错、rollout、评估和再训练。因此,compression、efficient
algorithm、quantization、edge deployment
并不是论坛主题之外的工程优化,而是自进化能否发生的计算底座。
Recursive self-improvement requires massive iteration 00:15:10
他把目标说得很清楚:让模型跑得更快,在更小 model size
下激发更大潜力。边缘设备部署的例子包括眼镜、手机等。端侧运行有两个额外意义:其一是
personalization,模型可以更贴近用户偏好;其二是 privacy
preserving,很多个人数据不必离开设备。
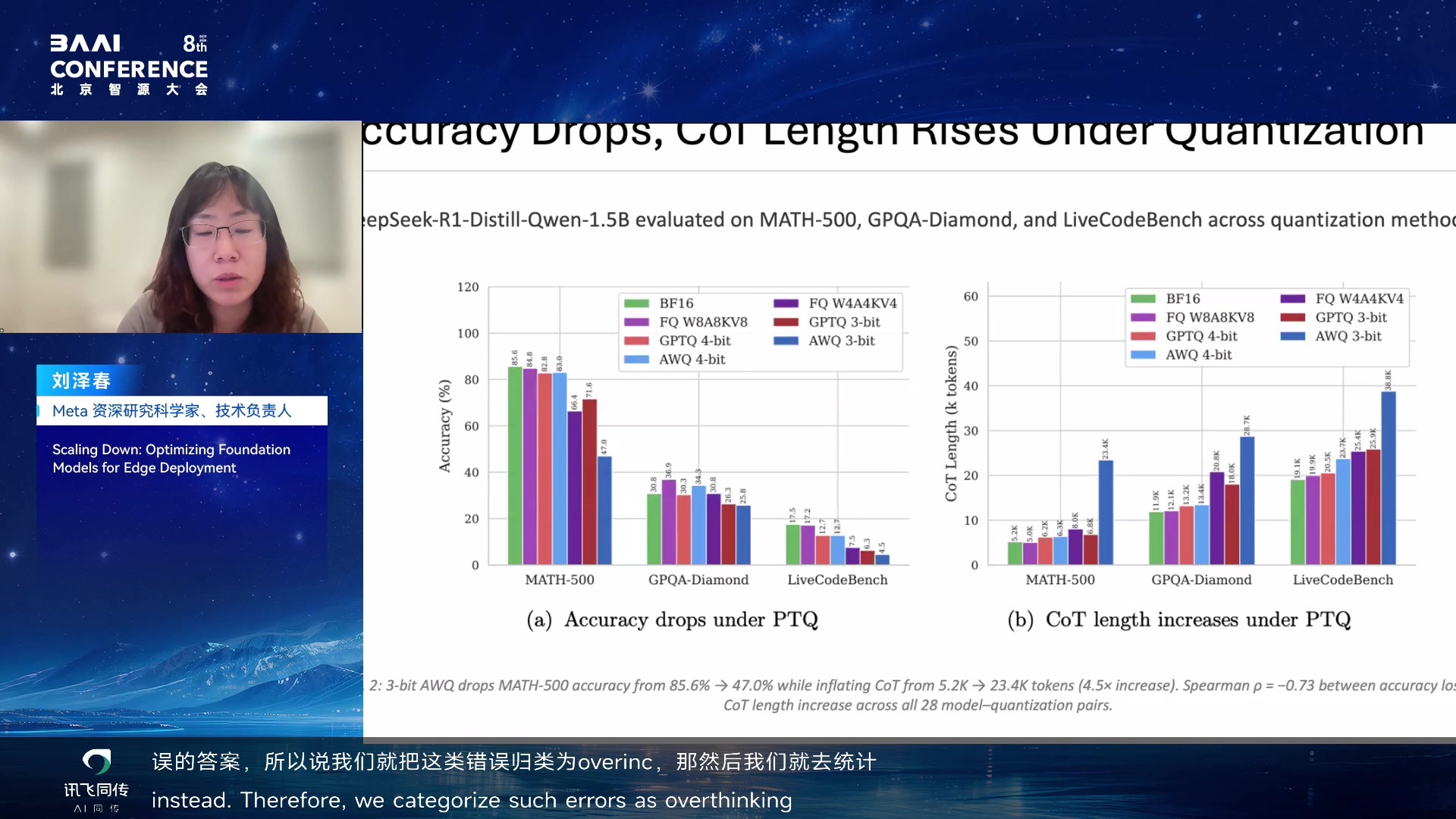
量化后的 reasoning model 为什么会 overthink
第一组工作关注量化 reasoning model
的一个反直觉现象:模型量化后不只是"能力下降",还会"想得更久但不更好"。核心例子是:模型在中途已经产生正确答案,但因为不确定,继续说
wait、but 之类转折词,反复检查,最后反而走到错误答案。
Quantized reasoning models overthink:中途正确但继续怀疑 00:16:40
这里的关键不是"长 CoT
一定不好",而是"量化改变了模型对自己答案的置信和继续思考的倾向"。统计结果显示,低比特量化会让
accuracy drop,同时 CoT length rise。进一步分类错误后,overthinking
error 在低比特模型中不成比例增加。
量化后 accuracy drops 且 CoT length rises 00:17:40
Overthinking errors inflate disproportionately 00:18:15
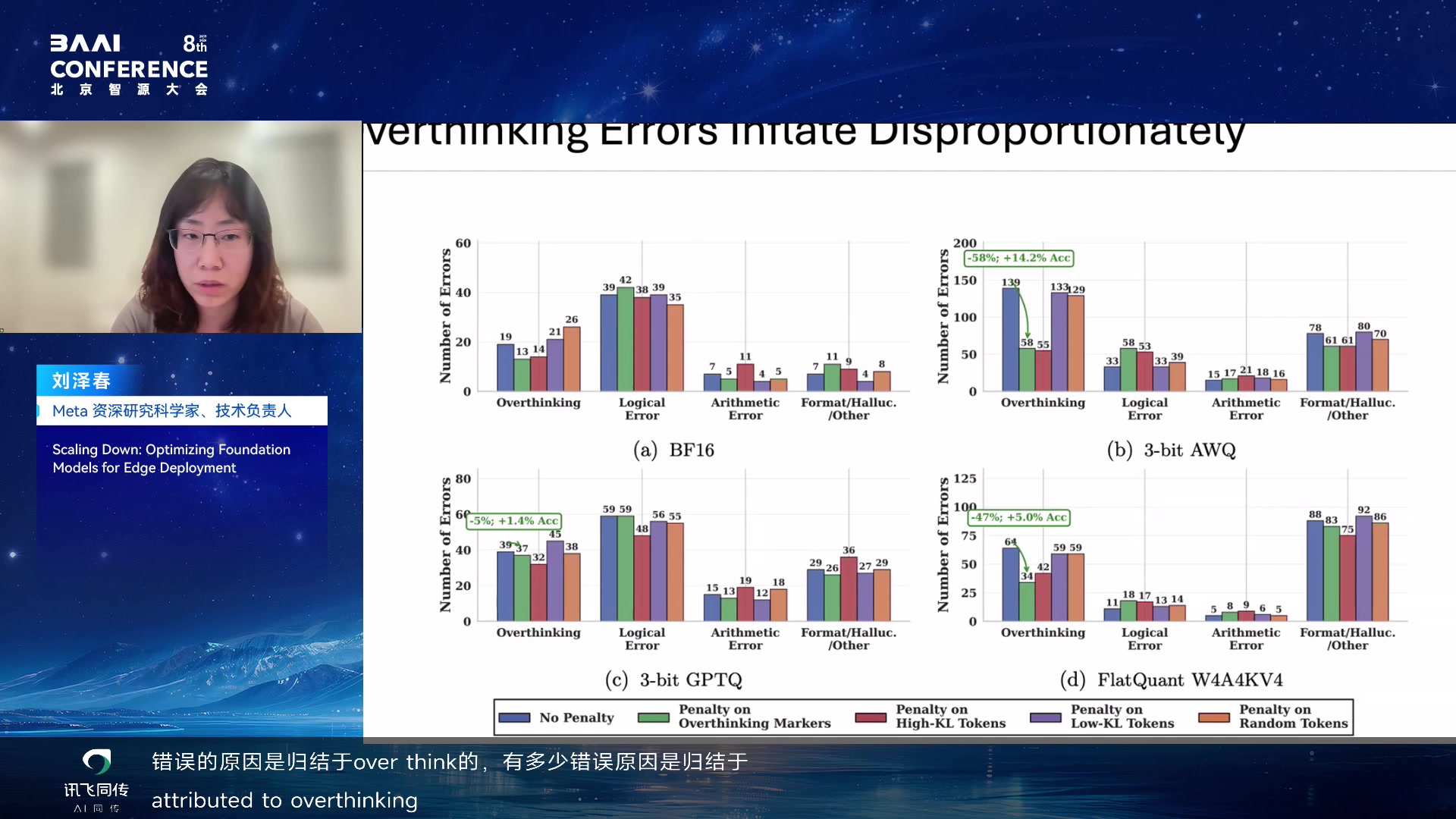
量化的行为学后果
量化不仅是数值精度变化。对于 reasoning
model,它可能改变模型的推理轨迹分布:模型更容易怀疑已经得到的候选答案,产生更多冗余反思
token,从而既花费更多 token,又更容易把正确路径推翻。
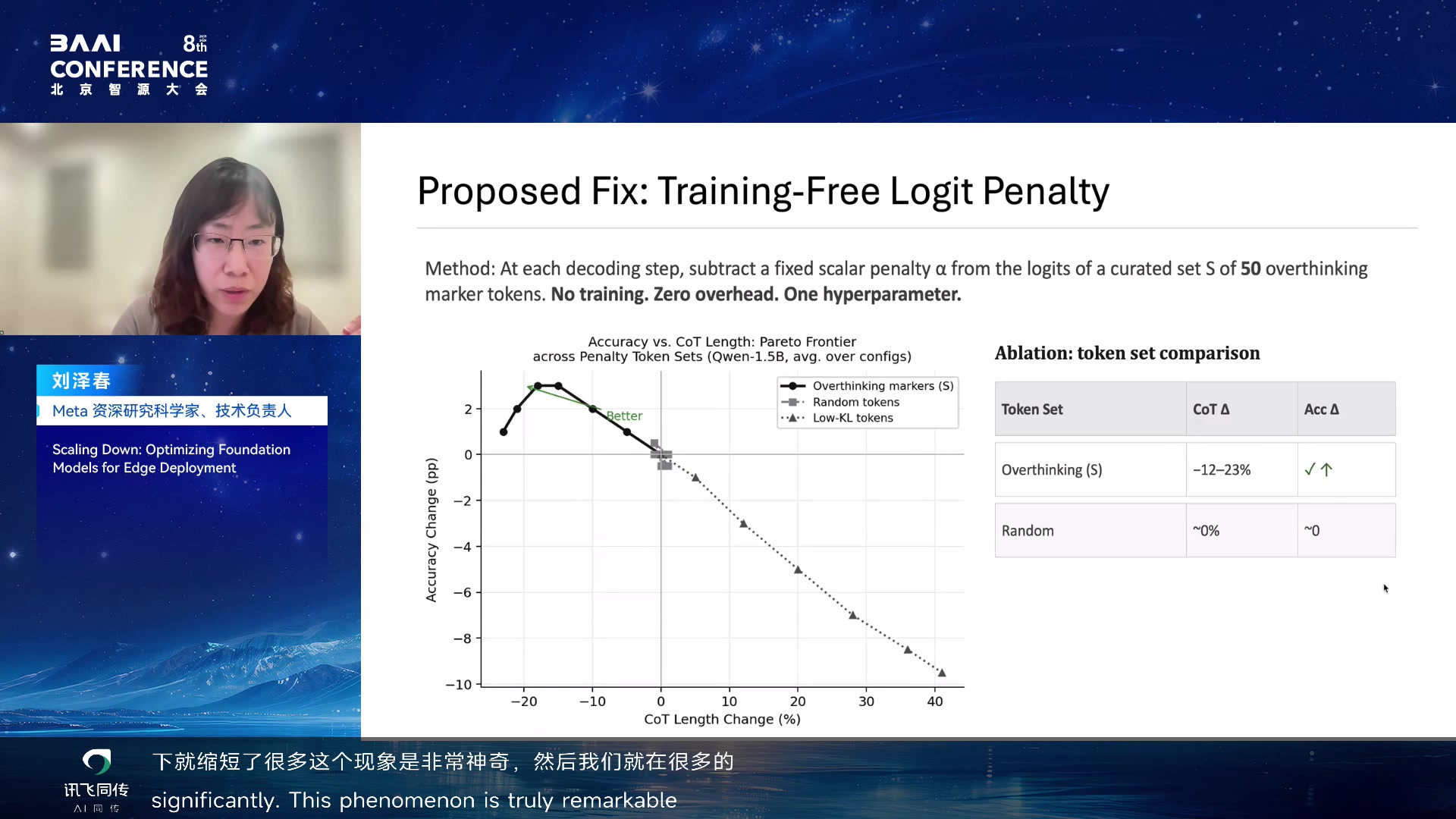
Training-Free Logit Penalty
解决方案非常朴素:整理一组容易触发过度反思的 token,例如 wait、but
等高熵转折词,在 decoding 时对这些 token 的 logit 施加 penalty。这是
training-free 的,不需要重新训练模型。实验上,它能缩短
CoT,并在很多设置中提高 accuracy。
Training-free logit penalty:压低过度反思 token 00:20:10
这个方法的意义不在于它是终极方案,而在于它说明:量化带来的损失有一部分不是"知识消失",而是"推理控制策略偏移"。如果问题来自推理轨迹的局部偏置,那么
decoding 层面的干预就可能有很大收益。
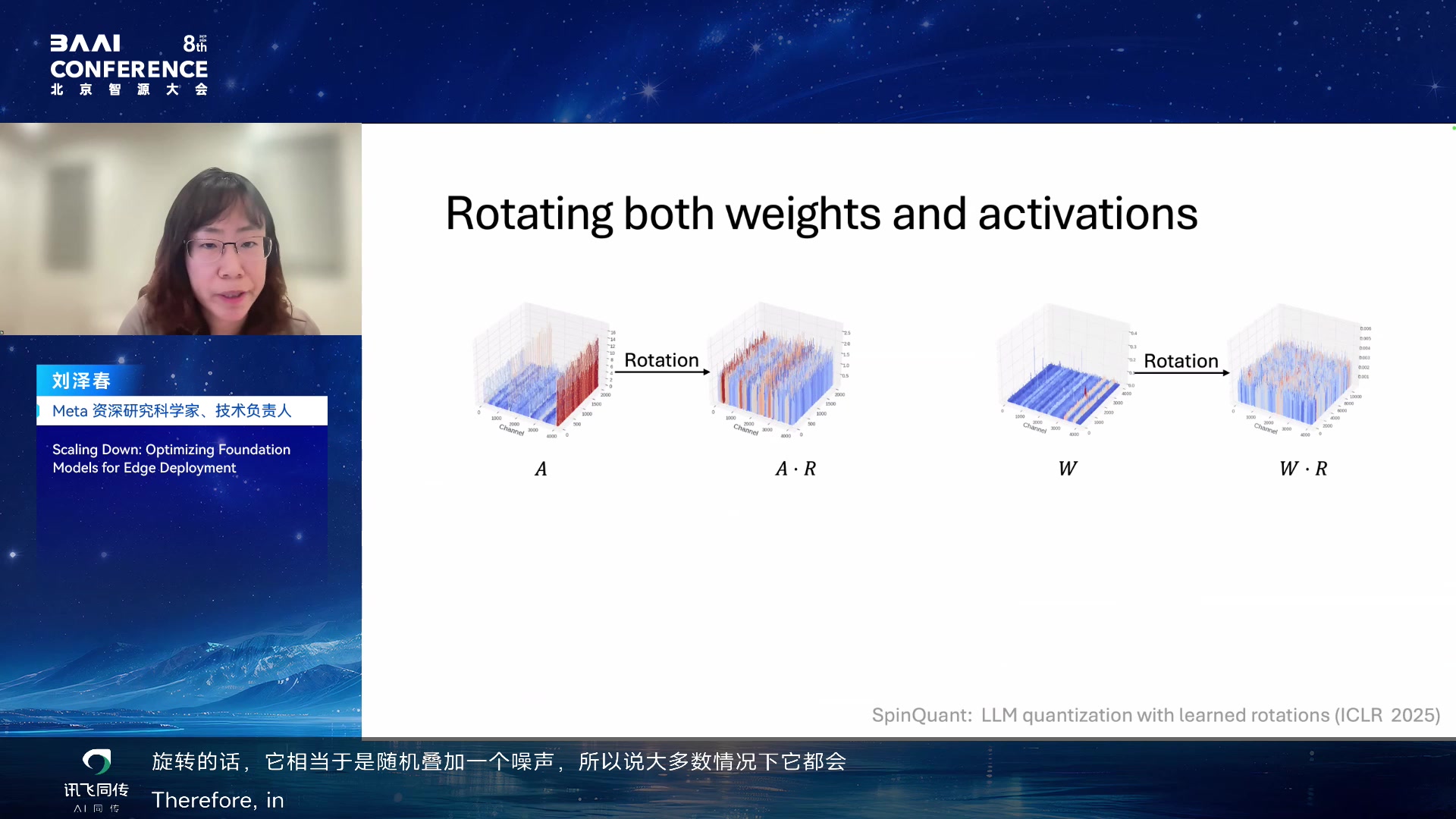
SpinQuant:用 learned rotations 降低 outlier
第二组工作是 SpinQuant。LLM 量化困难的一个来源是 activation 或
weight 中的
outlier。直观上,如果某些维度特别大,低比特表示就很难同时照顾这些极端值和普通值。SpinQuant
的思路是学习旋转矩阵,通过改变基底把 outlier
分散,从而让量化更平滑。
SpinQuant: LLM quantization with learned rotations 00:22:40
同时旋转 weights 和 activations 00:24:10
报告中强调,旋转不是随便加一个 trick。它要满足正交矩阵约束,既要旋转
weight,也要旋转
activation,并保持网络函数尽量不变。优化旋转矩阵时,用到 Stiefel
manifold 上的 Cayley SGD。
用 Cayley SGD 优化旋转矩阵 00:25:40
QAT 为什么慢,以及如何加速
第三组工作讨论 quantization-aware training。QAT
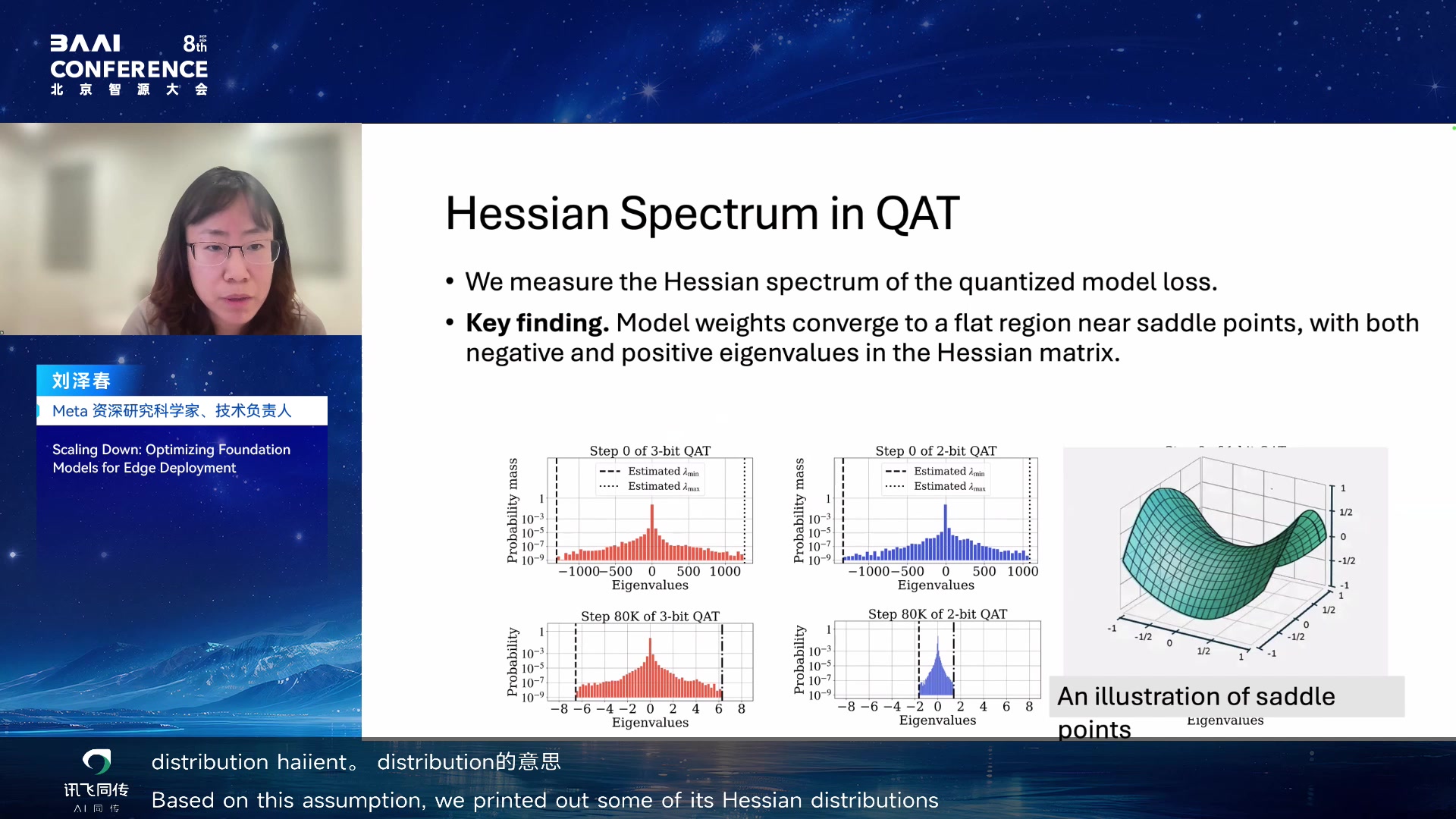
的目标是在训练过程中加入量化,从而让模型适应量化误差。问题是 QAT
收敛很慢,早期性能下降明显。报告用 Hessian spectrum 解释:量化模型的
loss surface 可能出现 saddle points 和 flat
regions,导致梯度更新效率低。
QAT 的 Hessian spectrum 与 saddle/flat region 00:28:40
为加速 QAT,报告提出 weight re-initialization
思路:周期性地把权重重置到 full-precision weight 与 quantized weight
的线性插值位置,从而减小二者距离,并放大 Hessian eigenvalues
的有效信号。实验结果显示,训练速度和最终性能都可以改善。
加速 QAT 的 weight re-initialization 算法 00:30:10
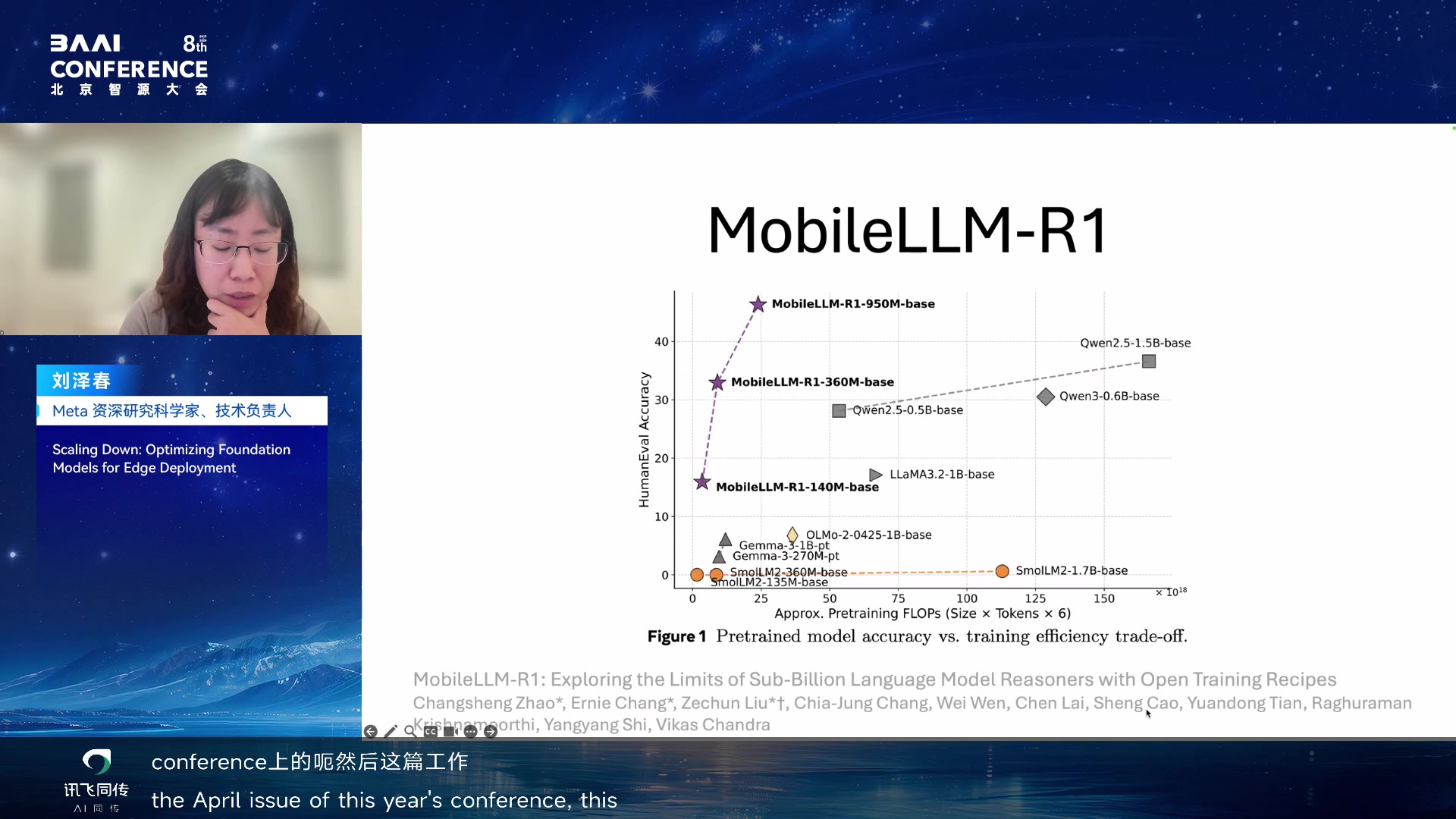
MobileLLM-R1:小模型 reasoning 的训练管线
报告后半转向 MobileLLM-R1。核心问题是:sub-billion
或小参数模型是否也能拥有 reasoning
能力?路线不是简单蒸馏,而是完整训练
recipe:pre-training、mid-training、post-training 分阶段推进。
MobileLLM-R1 标题页 00:31:40
MobileLLM-R1 训练管线 00:32:10
pre-training 阶段关注能力平衡。报告展示了 influence score
的思想:通过 leave-one-out ablation
识别哪些数据对目标能力有正向贡献,再聚合为数据集层面的权重。mid-training
阶段关注 knowledge
compression,即把更大模型或更复杂分布中的知识压缩进小模型。post-training
阶段再做 general SFT 与 math/code SFT。
Pre-training 中用 influence score 平衡能力 00:35:10
Mid-training: knowledge compression 00:37:40
Token efficiency:小模型训练效率对比 00:39:10
报告还从 RL 角度解释 on-policy KD。传统蒸馏容易是
off-policy:老师给出的轨迹不一定来自学生当前策略。on-policy KD
更接近让学生在自己的轨迹分布上接受老师反馈,这对 reasoning
小模型尤其重要。
RL perspective on on-policy KD 00:39:40
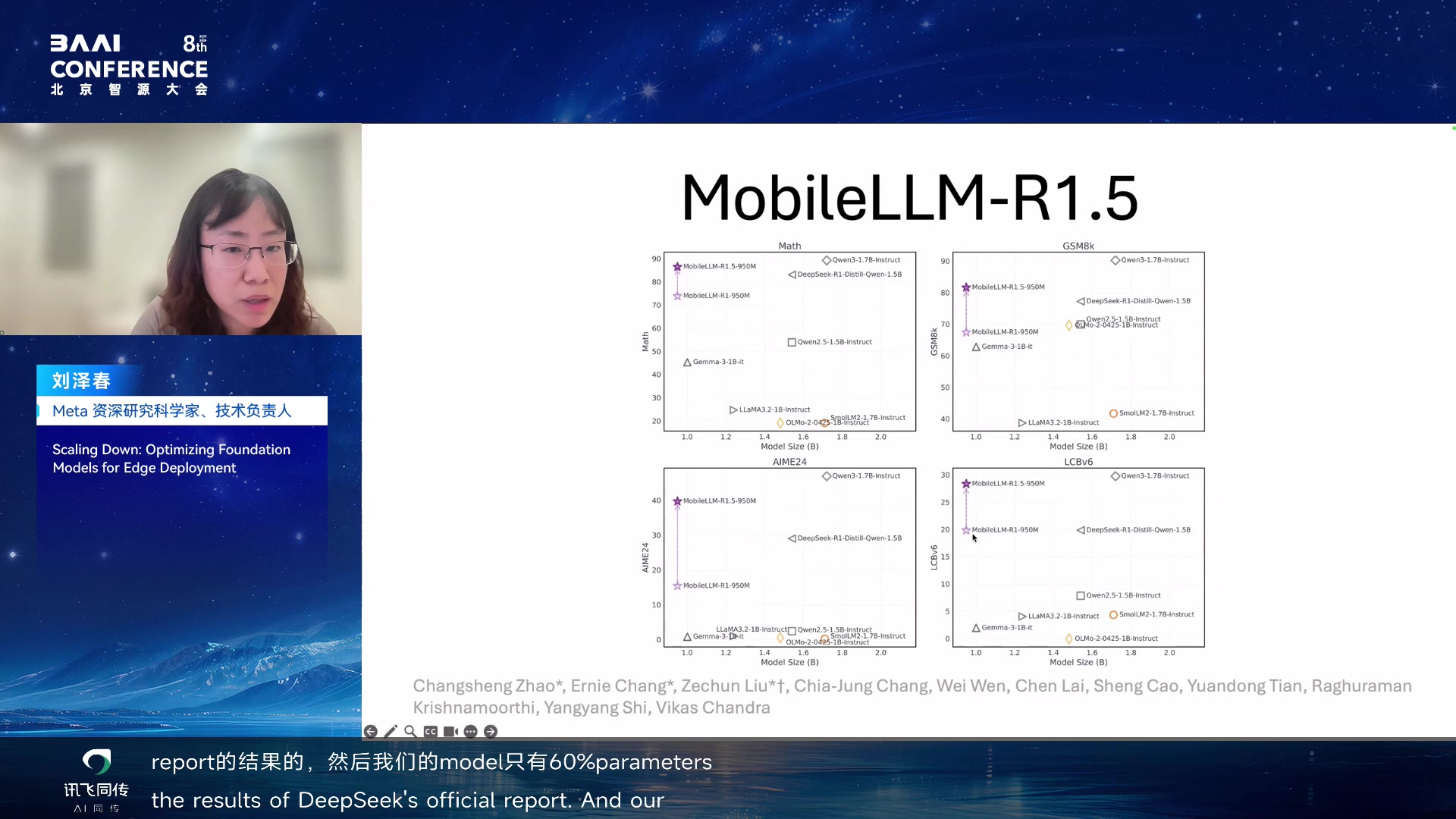
MobileLLM-R1.5 结果与延伸 00:40:40
Q&A:量化下界、稀疏与 scaling law
Q&A 中,有听众问:量化到 8-bit、4-bit
后能力上限在哪里?刘泽春回答,经验上 8-bit 和 4-bit
很多时候接近无损,尤其 QAT 做得好时 4-bit 可以接近 full
precision。但更低比特会更挑战,不同 use case 对精度要求不同。
另一个问题是稀疏和量化的关系。他认为量化通常比稀疏有更高压缩率:从
BF16 到 4-bit 可以有很大压缩且精度损失小,而稀疏做到 20%--30%
压缩已经很难无损。但两者不完全互斥,可以叠加。
最后他提到 ParetoQ 类 scaling law 问题:更大参数加更低
bit,与较小参数加更高 bit 之间存在 tradeoff。某些场景下 2-bit
可能优于 4-bit,长上下文或高精度场景下 4-bit 可能更稳。
本节小结
刘泽春的报告把 RSI
拉回计算成本:自进化不是只要有"反思"就能发生,它需要大量迭代。量化、小模型、端侧部署和训练加速共同决定了系统能否
afford
足够多的尝试。对学习讲义读者来说,本章最重要的收获是:高效模型不仅是部署优化,也是自进化闭环的基础设施。
拓展阅读
张少坤:从 AgentOptimizer 到 ProRL Agent Rollout Infrastructure
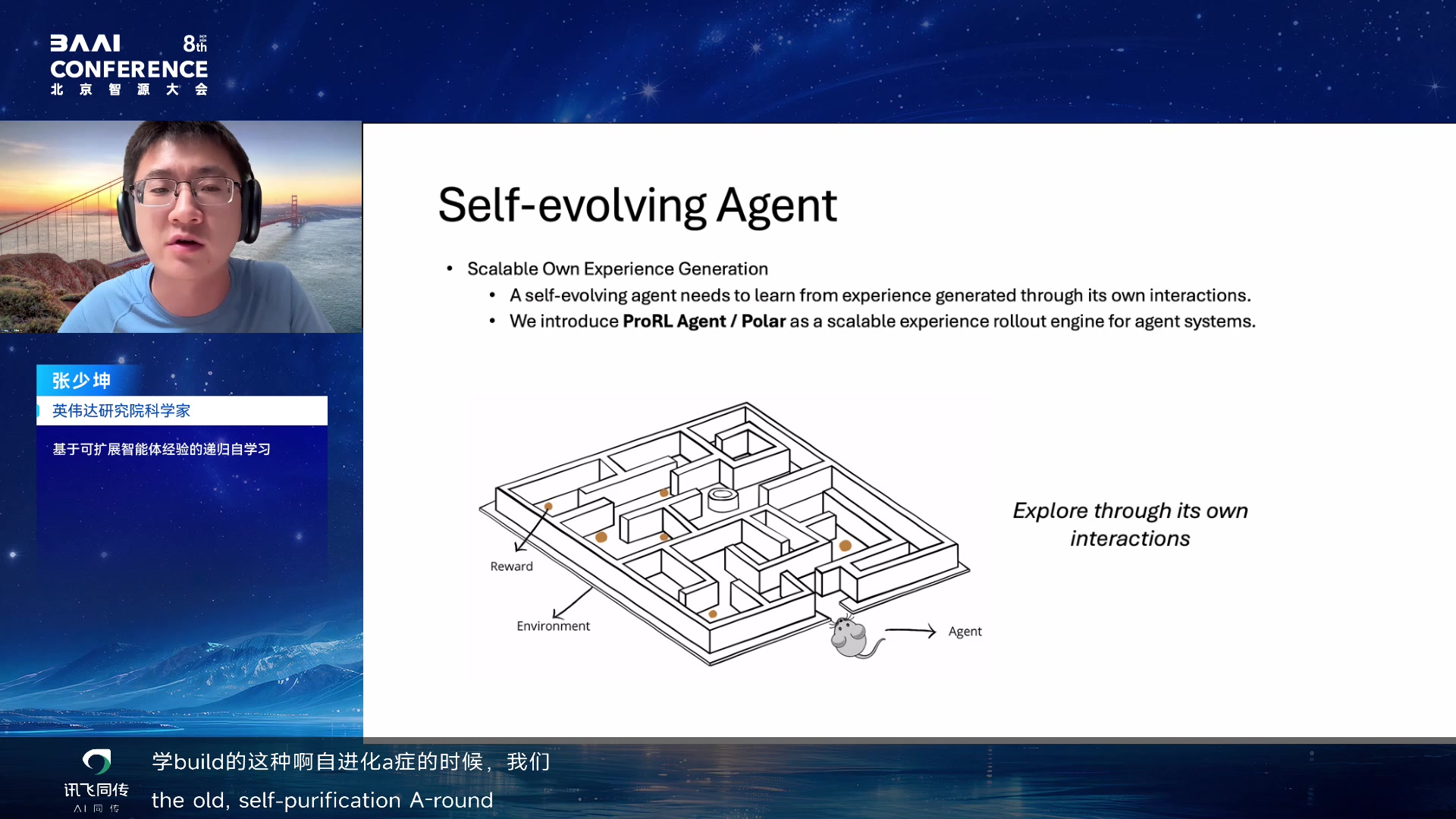
Self-evolving Agent 的两个条件
张少坤的报告围绕"基于可扩展智能体经验的递归自学习"。他给
self-evolving agent 的定义有两个条件:第一,agent
能递归地从自己的经验中学习;第二,它能修改自身的可学习组件,而不只是消耗外部数据。
Recursive Self-Learning through Scalable Agentic
Experience 00:49:35
Self-evolving Agent:从自己的经验学习并修改可学习组件 00:50:05
他用 von Neumann self-replicating machine
类比这种递归能力:一个系统不仅执行任务,还要能生成、评估、修改下一版系统。对
agent 来说,这里的"自身"不只是模型参数,也包括
prompts、tools、subagents、workflow、memory 和 policies。
self-replicating machine 类比 00:51:05
通过自身交互生成可扩展经验 00:51:35
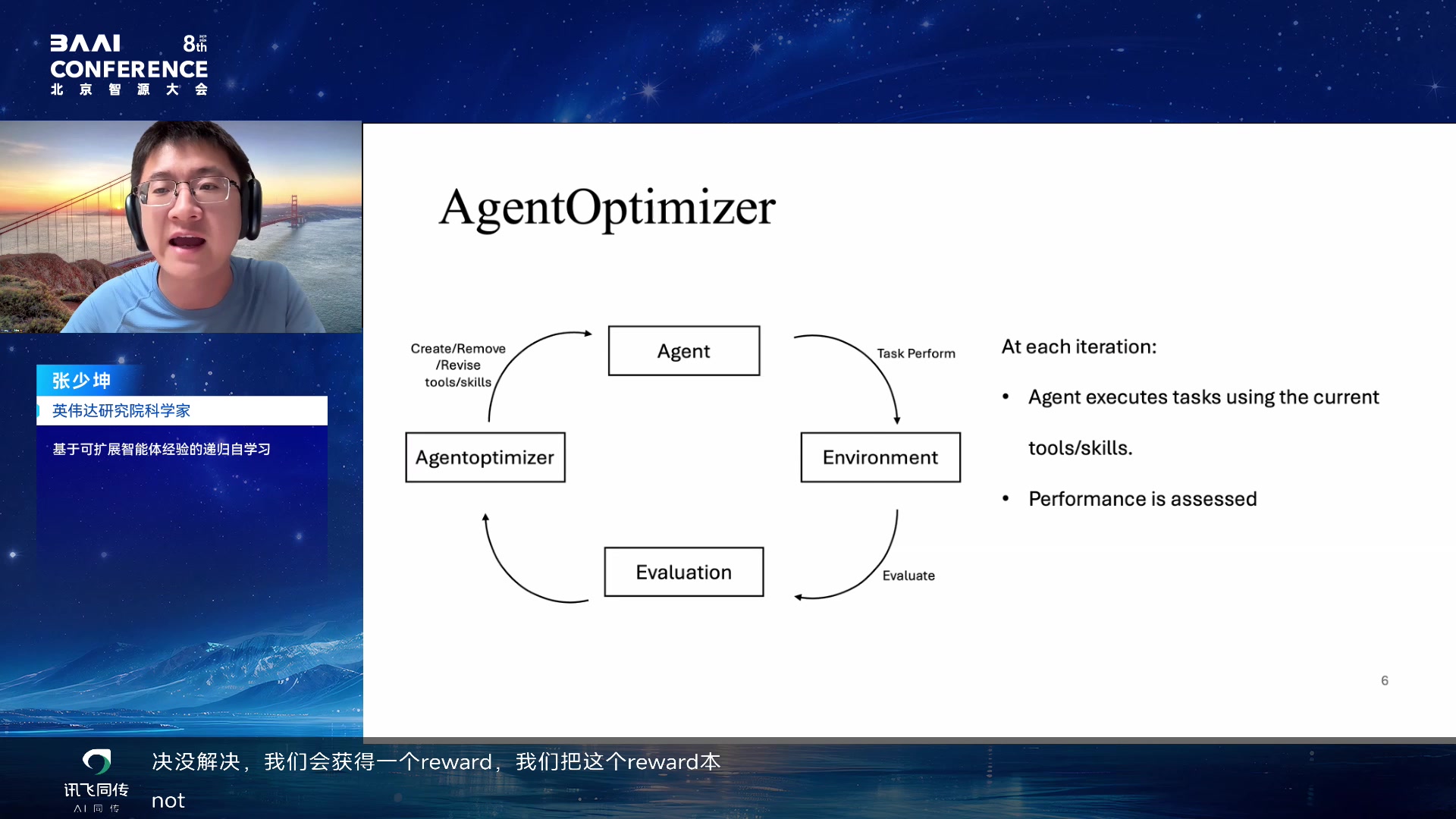
AgentOptimizer:把 model 和 harness 分开
AgentOptimizer 的关键抽象是:agent = model + harness。model
是底座语言模型;harness 是工具、prompt、workflow、subagent、policy
等外部组织结构。自进化可以先发生在 harness
上,因为它比模型权重更容易读写、修改和评估。
AgentOptimizer:agent = model + harness 00:52:35
AgentOptimizer 的递归 loop 00:54:35
具体循环是:agent 在 environment 中完成任务,evaluation
给出反馈,AgentOptimizer 根据反馈对 harness 做
add/delete/modify/check
等操作,然后进入下一轮。这个框架证明了:即使不改模型权重,修改工具链和工作流也能带来性能提升。
Self-evolving learning curve 00:57:05
为什么需要 ProRL Agent Server
报告第二部分转向 ProRL Agent Server。原因是 agentic RL 的 rollout
比普通 RL 更复杂:它是多轮、多工具、多环境、多仓库、多资源、多
reward 的系统问题。RL trainer 与 inference engine
之间如果强耦合,会让每个任务都需要专门 glue code。
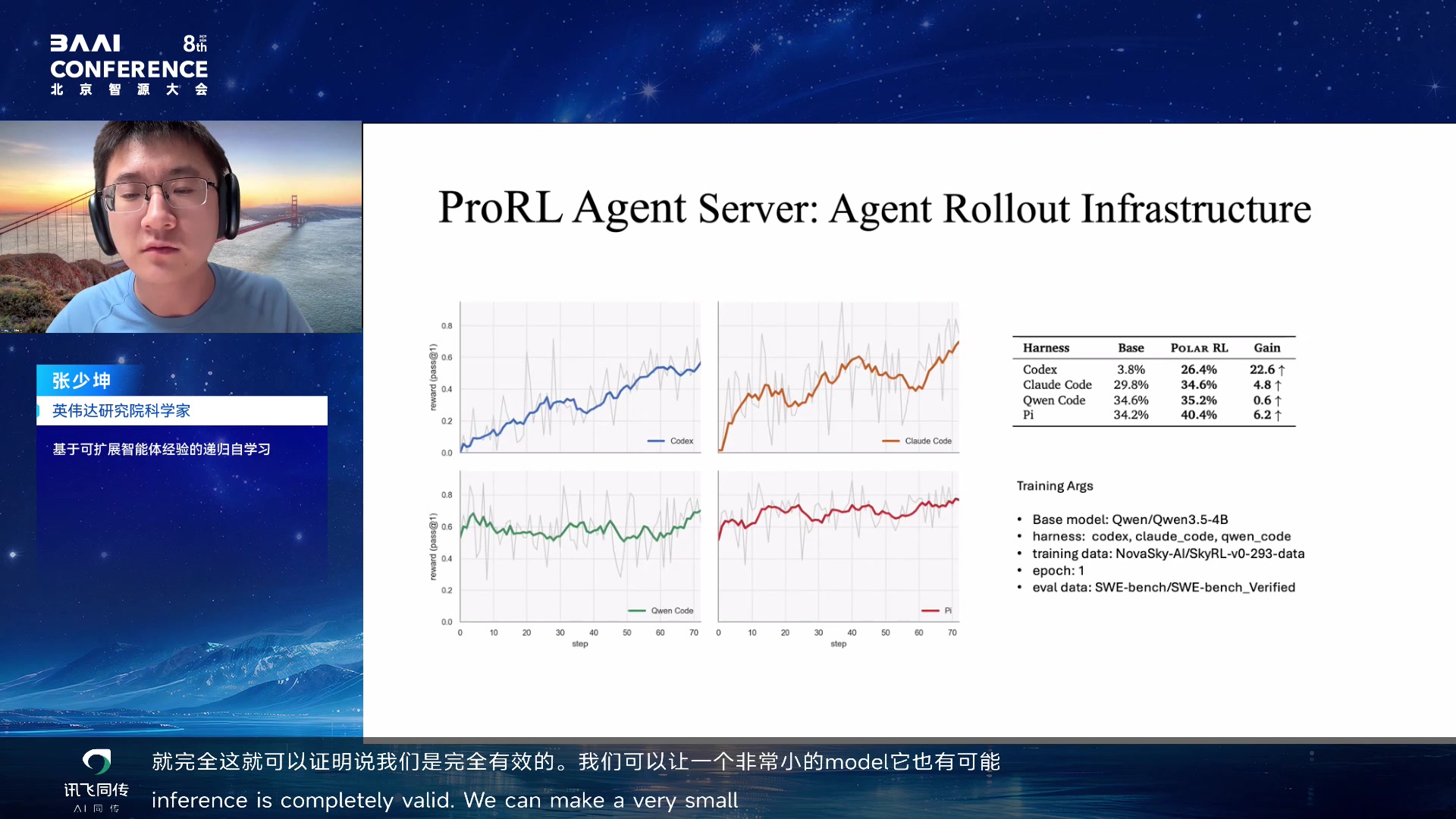
ProRL Agent Server: Agent Rollout Infrastructure 00:57:35
coupled design 与 decoupled design 对比 01:01:05
ProRL Agent Server 的思想是把 rollout 做成服务。RL trainer
不需要了解每个 agent harness 的细节,只需要请求 rollout;server 负责
sandbox、repo、resource、tool、environment、reward、model proxy
等基础设施。
ProRL Agent Rollout Server 架构 01:03:35
异步 worker rollout 时间线 01:05:05
这个架构的工程价值在于:它允许多种 harness、多种任务共享一套 rollout
基础设施,并支持 asynchronous worker 调度。报告还展示了 prefix
merging、token routing、GPU utilization 等优化点。
Prefix merging 与 token routing 01:06:35
多 harness rollout 指标 01:08:35
Q&A:overfitting、机器人与 off-policy
Q&A 中,一个问题问 agent 自进化是否会
overfit。张少坤的回答很务实:computer-use agent
和软件工程任务中确实会遇到 overfitting。缓解思路主要在数据层面扩大
diversity,例如预先定义 rollout 轮次、工具种类、工具频率等 diversity
metrics,再据此选数据。
另一个问题追问能不能在 rollout 阶段扰动
agent、过滤路径来增加多样性。他提醒:RL 阶段如果在 rollout 中干预
agent,可能导致 off-policy 问题。更稳妥的做法是让 agent
自己探索,rollout 结束后再决定如何利用数据、如何增加 diversity。
关于机器人场景,他认为 VLA 和 diffusion action decoder 中也存在
failure mode,关键是大规模 rollout 收集真实失败,再用 critical data
训练。也就是说,ProRL 的基础设施思想不只适用于软件
agent,也可迁移到更复杂的 embodied agent。
本节小结
张少坤的报告补上了"自进化经验如何规模化产生"的基础设施层。AgentOptimizer
说明 harness 可以成为可学习对象;ProRL Agent Server 说明 agentic RL
需要 rollout-as-a-service。没有这样的基础设施,自进化只能停留在单次
demo;有了它,系统才可能积累足够多、足够多样、可用于训练的经验。
拓展阅读
ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn
LLM Agents:
arXiv 2603.18815
谷雨:Self-Improving Agents 的幻觉与真正学习的条件
为什么说有一种"幻觉"
谷雨的报告是全场最重要的反思性报告之一。他没有直接展示一个新系统,而是追问:今天很多号称
self-improving 的 agents,究竟是在学习,还是只是在堆积数据、改写
prompt、追加 memory?
谷雨报告标题页:The Illusion of Self-Improving Agents 01:19:16
Self-improving agents are having a moment 01:19:46
他的出发点是:大模型训练仍然是高度被动的。人类决定数据、训练流程、RL
environment 和 post-training recipe。模型上线后生成的大量
interaction
没有被及时消化成学习信号。如果未来模型参数规模继续上升,单靠互联网数据和人工标注数据很可能无法饱和。
为什么需要 self-improving:被动训练与数据瓶颈 01:21:14
谷雨把 self-improve 拆成两个词:self 与 improve。self 对应
proactiveness:agent 要自己判断学什么、什么时候学;improve 对应
learning:agent 要真的改变自身能力,而不是只留下日志。
Self Improve = Proactiveness + Learning 01:22:44
他本场主要讲 learning。一个核心定义是:learning 可以看成 memory
的更新。memory 不只是 markdown
文件或向量数据库,也包括模型权重、skill、workflow、harness、tools
等所有会影响未来 inference 的长期状态。
Learning 的三个
desiderata:representation、update、execution 01:24:44
Memory 不只是 markdown/vector DB,也包括 model weights 01:25:44
结构化表示:为什么 markdown rewrite 不够
representation 的关键是 abstraction 与 structure。没有结构的 memory
很难可靠泛化。谷雨用猫狗/颜色概念的例子说明:若只是把经验写成自然语言规则,模型可能无法稳定形成概念边界;结构化
memory,例如决策树,更容易支持可靠更新和后续执行。
没有结构时概念化不可靠:猫狗/颜色例子 01:28:14
结构化 memory 与 markdown rewrite 的 77% vs 28% 对比 01:29:14
这也是对许多"self-improving skill"的批评:它们把经验追加到 markdown
文件里,或者把笔记写进向量库,但没有稳定的抽象结构,也没有保证新经验能以正确方式合并进旧知识。
文本、向量库与权重:现有 memory 方案的利弊
报告回顾了几类现有方案。文本 memory
可读、易编辑,但结构弱、更新不稳定。向量数据库检索方便,但更像
episodic memory,难以保证抽象规则被学到。模型权重是最强的 long-term
memory,但更新成本高、可解释性差,也难以在线可靠更新。
Revisit existing solutions:文本、向量库、权重的利弊 01:31:14
因此,真正的 self-improving agent
不能只问"把记忆存在哪里",还要问"这个记忆的结构是什么、更新算法是什么、执行时如何验证它真的有用"。
Execution with Memory:prompt 注入不是闭环执行
第三个条件是 execution。很多系统把 memory 检索出来塞进
prompt,然后希望模型照做。谷雨认为这不足以构成可靠执行,因为 prompt
injection 只是把信息放到上下文里,并没有保证 agent
会正确使用,也没有闭环验证执行结果。
Execution with memory:prompt 注入缺少执行保障 01:34:44
Quick summary:结构化抽象、可靠更新、闭环执行、meta
control 01:39:14
这里需要 meta control:agent
要知道什么经验值得学,什么时候需要更新,更新后如何测试,失败时是否回滚。也就是说,proactiveness
不是额外装饰,而是 learning 系统的一部分。
Q&A:领域专门化与 expert-free 学习
Q&A 中,谷雨强调长期 memory 和 self-improvement
在专业领域尤其重要,因为很多长尾知识、组织内部知识、产品知识无法完全依赖公开互联网数据。他也指出,不一定每次都需要领域专家显式写规则;如果系统有足够强的结构化学习和
metacognition 层,它可以从交互中抽象出可验证规则。
但他也保持谨慎:如果只是在任务后追加文本,或者把错误经验也一并写入
memory,就很可能形成"越学越乱"的系统。真正的学习需要可靠的结构、更新和验证。
本节小结
谷雨报告提供了整场论坛的判别标准:不是所有"有记忆"的 agent 都是
self-improving
agent。只有当经验能被结构化表示、可靠更新、闭环验证,并由 agent
主动决定何时学、学什么时,才接近真正的 self-improvement。
细节层:诸葛鸣晨开场
本节覆盖 00:00:00--00:15:06,来自分章 ASR 与视频画面校验。
本节不是官方逐字稿
本节来自分章 ASR
与视频画面校验。它保留了更多细节,但仍可能存在烧录字幕/ASR
引入的人名、论文名、英文术语误差;关键论文名、讲者姓名和方法名应优先参考前文已校正的章节标题、关键帧说明和外部资料索引。
01|00:00:00--00:03:00
诸葛鸣晨开场先介绍论坛背景:AI 自进化论坛,主题是 Recursive
Self-Improvement,他认为这是一个非常 promising
的方向。他介绍自己是 Recursive 公司创始成员,博士毕业于
KAUST,导师是 Juergen
Schmidhuber——被西方媒体称为"现代人工智能之父",被中方很多媒体称为"LSTM
之父"。博士期间主要研究方向是 Coding Agent、Recursive
Self-Improvement 和 Neural Computer,引用超过 7000 次,70%
来自第一作者论文。
他随后介绍了联合主持人:华东师范大学助理教授熊宇轩,从事
AI+教育、计算机视觉、数据工程等研究,获 MLMI 2019
最佳论文奖;以及智源社区主编李梦佳,也是本次智源大会的主要组织者之一。
接着他切入正题:什么是 Recursive
Self-Improvement?从数学严格证明的角度,Schmidhuber 在 2003
年的论文中提出了 Gödel
Machine——一个递归程序必须能读取自身状态和逻辑,能改变自己(self-modification),然后通过严格数学证明说明下一次改进版本比上一个版本更好,再进行
self-rewrite,形成不断迭代的闭环。
但在真正实操中发现,用严格数学表达和证明"下一版更优"非常难建模。所以现实中退化为
Empirical RSI:P 可能就是一个代码 repo,有自己的 commit
和状态,是一个偏工程的 infra,整个 loop 中的 self-modification
仍然是让系统能够改变自己。
02|00:03:00--00:06:02
诸葛鸣晨继续解释 Empirical RSI
的核心:从严格的"数学证明下一版更好"退化为"用实验选择更好的候选"。具体做法是生成大量
candidate,在 benchmark 上测试哪个表现更好,选 best performance
的那个进行迭代。
他提到今年 4 月底在 ICLR 举办了第一届 RSI workshop,请到了世界上做
Recursive Self-Improvement 最顶流的一批人:Julian
Schrittwieser(AlphaGo/AlphaZero 作者,现 Anthropic);Recursive
公司创始人 Jeff Klonsky、Richard Socher、袁栋;DeepMind AlphaEvo
的 lead Marta;以及他导师 Schmidhuber 作为 panel
主持人。讲者还包括 Chelsea Finn、Sergey Levine
等强化学习和机器人领域强人。
RSI 这件事已经存在几十年了,只是最近才火。Schmidhuber
的个人主页第一句话就是:从 15 岁开始,他的主要目标是建立一个
self-improving
的人工智能,能比他更聪明,然后他就可以退休了。虽然他最被熟知的是
LSTM,但他在 1987 年的博士论文就已经在强调这些方向。2003 年提出了
Gödel Machine 的形式化框架。RSI 真正在 2025
年有了雏形,因为模型的代码能力到达了这个阶段。整个湾区不同的
CEO——Sam Altman、Dario、Demis、Elon——都在谈 Recursive
Self-Improvement,都觉得是时候再考虑这件事了。
03|00:06:02--00:09:05
诸葛鸣晨分享了自己 2023 年的一篇早期 coding agent
工作,这是让他第一次增长 reputation 的
paper。他在附录中就写了:coding agent
少了积累经验的机制。他的原话是,一个 software development team
需要积累学习经验,每次 coding task
需要积累性的经验来提升自己——this is somewhat related to the idea
of recursive self-improvement。
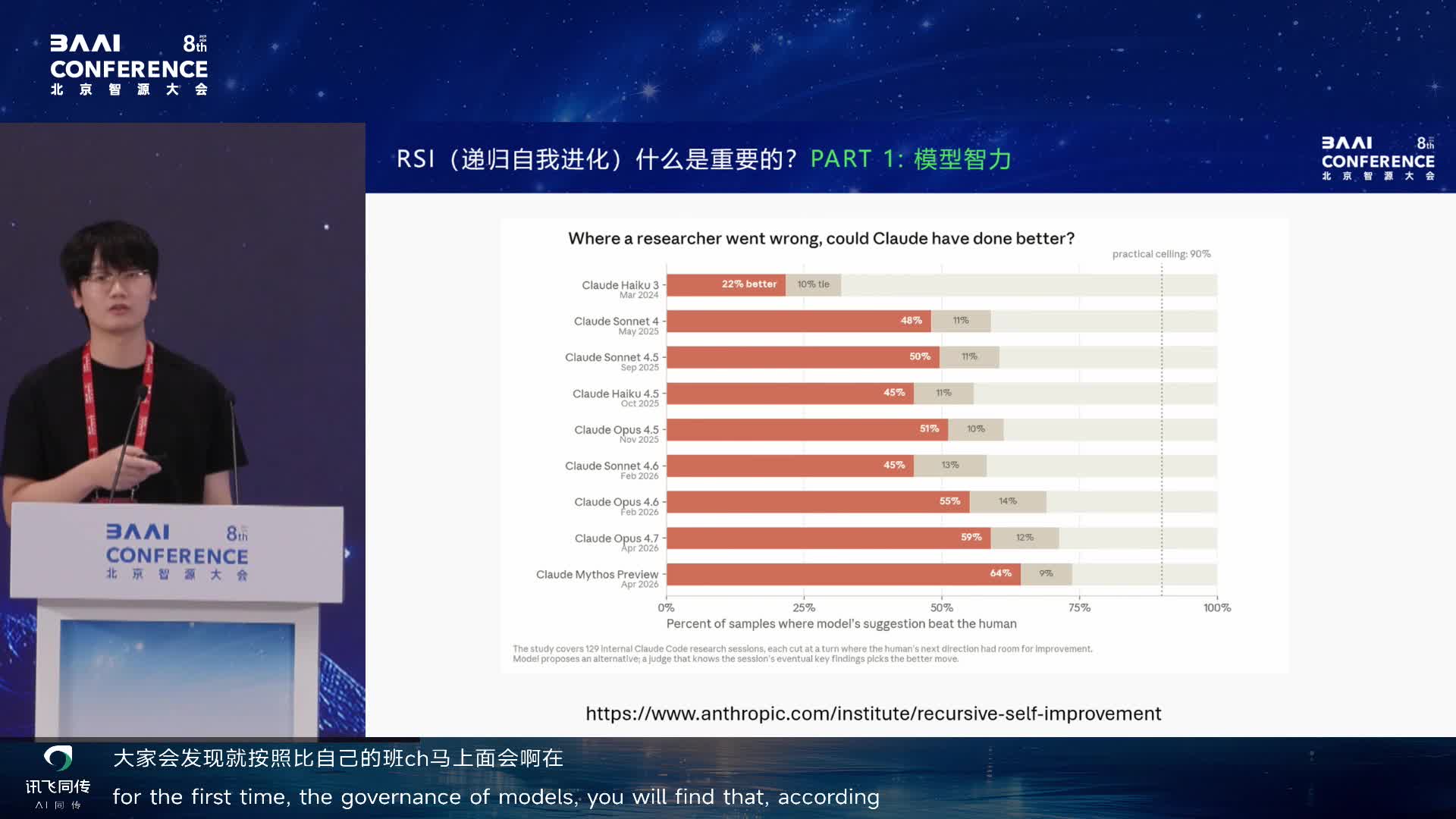
他解释为什么这件事最近能被疯狂讨论:Anthropic 前几天的 blog
显示,在 2025 年 November,模型代码能力在 51%
的情况下能打败人类。从 2025
年底开始,模型代码能力正式领先于普通甚至专业
engineer,所以到了该谈论 RSI 的时候了。
关于形式化框架和进化算法:2023 年底的一篇工作(2024 年投
ICLR)把所有 agent 建模为图——每个 function/operation
是一个节点,一个 agent 就是一个 graph of nodes,多个 agent
组成的大图仍然是一个图,orchestration 就是图里面 edge
的连接。这样,优化智能体就等价于优化图里面的 node 或 edge。
04|00:09:05--00:12:07
诸葛鸣晨强调当前 RSI 的完整 context 包括整个 training loop、底层
kernel、infra、neural architecture 设计,一直到 coding agent 积累
trigger 再反馈到训练——已经到了一个非常强烈的阶段。
第三点他认为重要的是评估。他提到 2024 年底的一篇 ICLR 工作,认为
agency charge 是非常重要的东西,能在长时程任务中提供 intermediate
feedback。他特别强调 recursive 系统最害怕的是 reward
hacking——系统其实没有提升,但它修改了 evaluation
让自己看起来提升了。
他分享了自己的梦想:做完 RSI 之后,下一步要用 RSI 去造出
Completely Neural Computer。Andrej Karpathy
在最近的采访中也提到了非常相似的 idea——未来 computer 就是由 model
承载的。
他介绍了当前做 RSI 的主要公司:Anthropic 和 OpenAI
完全强调已经到了做 RSI 的阶段(Sam Altman
前天说可以稍微推迟上市,前提是 RSI 要做得好);Recursive 专门做
RSI;Sakana AI 建立了 RSI Lab(David Ha 是主要人物,他在 2018 年和
Schmidhuber 发了那篇著名的 World Models paper);还有一家叫
Recursion(做芯片 self-improving),以及他师兄创立的
Inherent(英国,做 recursive self-improving)。他认为 DeepMind 的
AlphaEvolve 和 David Silver 的 Ineffable 也在做类似事情,虽然没用
RSI 这个术语,但最终 target 可能相同,只是解决路径不同——David
Silver 更强调 RL。
05|00:12:07--00:15:06
诸葛鸣晨介绍了 Recursive 公司前一天的
blog:他们打通了底层实验,证明了 recursive 算法现在还行。在
NanoClaude AutoResearch 上取得了 SOTA——在给定 budget
下达到最好性能;在 NanoGP Speedrun 上拿到 77.5
秒的成绩(从之前四十多分钟优化下来);在 Speed of Light 的
ExecutableBench(英伟达的 GPU kernel benchmark)上也拿到远超社区的
SOTA。值得注意的是,公司暂时没有任何 kernel expert,但 recursive
算法能把东西优化到 SOTA。
他介绍今天大会议程:刘泽春(Meta,前两年合作者);张少坤(英伟达
research scientist);林涛(西湖大学 AI
系特别研究员);谷雨(NeoCognition 联合创始人);王琰(前腾讯
Frontier 专家研究员);杨梦月(UCL
博士,布里斯托副教授);郑侠武(厦门大学 AI
研究院副教授)。最后是圆桌讨论。
他正式介绍第一位讲者刘泽春:Meta Reality Lab
资深研究科学家,小模型训练技术负责人,非常强的女性科学家,超过
9000 citation,在 small model 领域有非常多代表工作。演讲题目是
Scaling Down: Optimizing Foundation Models for Edge Deployment。
细节层:刘泽春
本节覆盖 00:15:07--00:49:28。
01|00:15:07--00:18:09
相关关键帧: 00:15:10 Recursive self-improvement
requires massive iteration;00:16:40 Quantized reasoning models
overthink;00:17:40 accuracy drops 且 CoT length rises
刘泽春开场解释为什么 Recursive AI 需要压缩和高效算法:因为 RSI
本身需要很多 iteration,算法更高效就能 iterate
更多。她的工作帮助模型跑得更快,在更小 model size
下激发更大潜力。一部分是
Quantization——把模型量化到低比特就能跑更快,iterate 更多。Edge
Deployment 包括眼镜、手机,好处是
personalization(记住用户喜好)和 privacy
preserving(数据不离开设备)。
接着她介绍第一篇工作:为什么 quantized model 会
overthink。标题意思是"Quantized model
觉得它需要想更久,但它其实不需要"。在 quantized reasoning model
里面,大家会认为它想得更久、accuracy
更低是因为能力不够,但实际上很多时候它在中途已经发现了答案,但不确定,就会说
wait、but 这种转折词,重复
check,反而给了错误答案。这类错误被归类为
overthinking。统计结果显示,量化比特数越低,CoT length 增加越多。
02|00:18:09--00:21:11
相关关键帧: 00:18:15 Overthinking errors
inflate;00:20:10 Training-free logit penalty
刘泽春进一步分析错误分类:在 BF16 全精度模型中,overthinking
占比相对较少,更多是逻辑错误。但量化到 3-bit 或 W4A4
时,overthinking 占比大大增加(用 GPT 分类错误类型)。
解决方案非常简单:把导致 overthinking 的 token(wait、but
等高熵转折词)列举出来,变成一个 50 个单词的 vocabulary,在
decoding 时直接压低这些 token 的
probability。实验结果很神奇:accuracy 一下子升高了,CoT length
大大缩短。在大多数 benchmark 和不同 model、不同 context 方法下,加
penalty 都能获得 2-3 个百分点的提升,同时 length 大大减少。
03|00:21:11--00:24:13
相关关键帧: 00:22:40 SpinQuant 标题页;00:24:10
同时旋转 weights 和 activations
第二篇工作 SpinQuant(ICLR
2025),是刘泽春个人非常喜欢的一篇。它是帮助量化算法达到更优精度的方法,用于
post-training 量化——已有模型,通过不训练、用少量 calibration data
帮它 calibrate 到适合量化的位置。
Motivation:LLM 中有很多 outlier,困扰了大家很多年。Outlier 会
dominate,占据所有量化精度,导致正常值分配的量化步长很大,精度损失更多。但
outlier 又很重要,不能直接 clip。
SpinQuant 的做法是旋转 matrix。直觉:如果一个 vector 中 X1 和 X2
的 magnitude 不一样,X1 会占据整个量化范围,X2
只获得很小精度。旋转后,X1 和 X2 在坐标轴上的投影 magnitude
均匀了,同时被量化时都能获得较好精度。随机旋转等价于叠加高斯噪声,大多数情况下能把
outlier 抹平。
04|00:24:13--00:27:14
相关关键帧: 00:25:40 Cayley SGD 优化旋转矩阵
旋转有一个非常奇妙的好处:如果既旋转 activation 又旋转
weight,中间的旋转可以互相抵消,并且 activation 和 weight
都变得容易 quantize。Transformer
里面有很多设计细节(旋转矩阵如何互相抵消、哪些地方需要特殊处理),这里不展开。
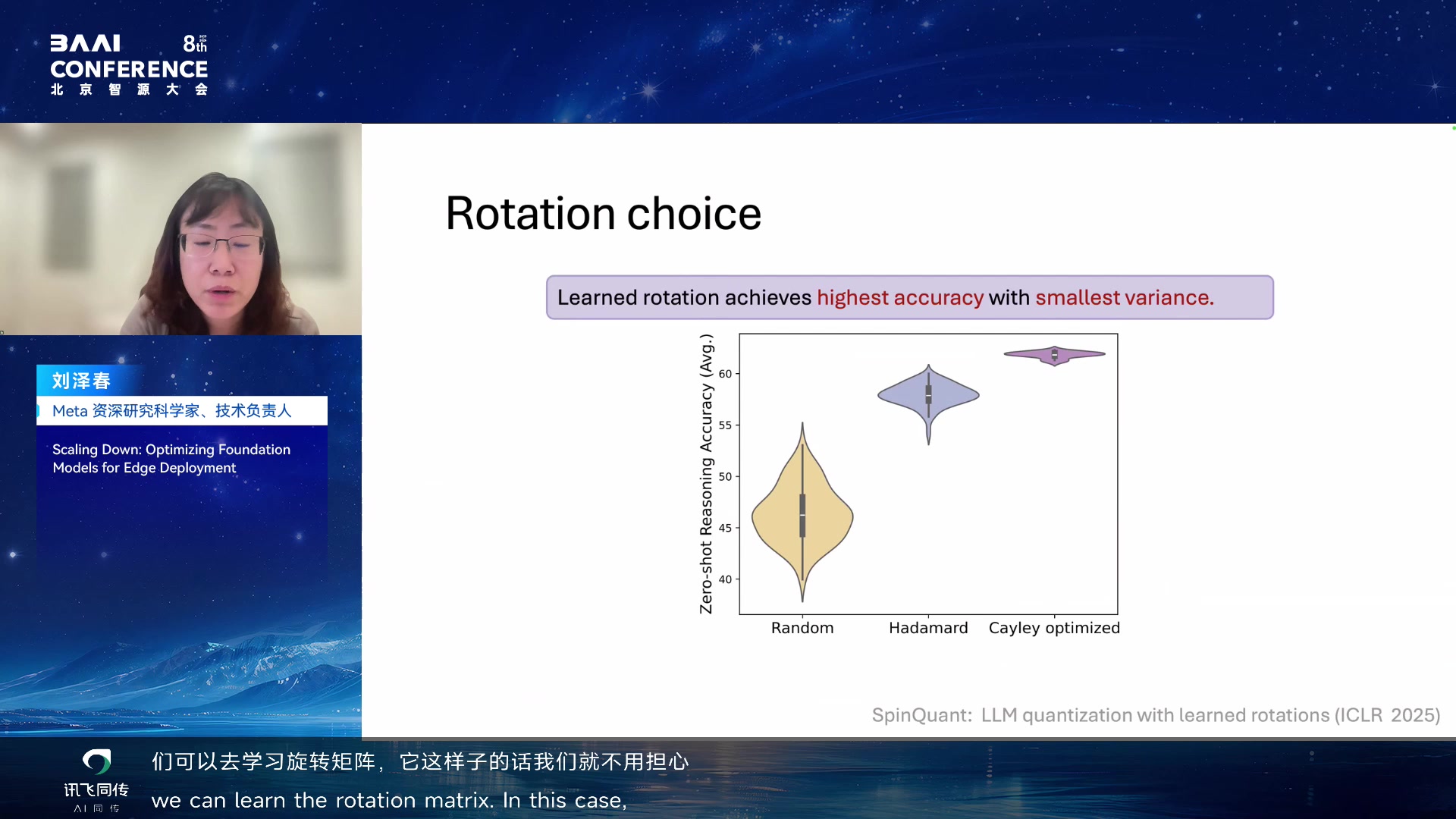
进一步发现:旋转矩阵有不同类别——随机全精度旋转矩阵(range
非常大,可能好也可能差);Hadamard 旋转矩阵(每个 element 是 -1 或
1 除以行列长度的根号,更受限,范围更小,精度更高);以及 learned
旋转矩阵(不用担心随机到不好的矩阵,variance 更小,accuracy
更高)。
优化用 Cayley SGD,速度大约是普通 SGD
的两倍以内,可以在正交空间里优化旋转矩阵。结果远优于之前没有旋转矩阵的量化方法,也比
concurrent 工作 QuaRot 更好(QuaRot 也用了旋转矩阵,但没加
learning)。
第三篇工作还是量化算法,但不同:前两篇是 post-training
量化,这篇是 training 过程中边训练边量化(QAT)。Forward pass
把全精度 weight 变成离散化的 weight,backward pass 把离散 weight
的 gradient 算出来加到全精度 weight 上。
05|00:27:14--00:30:32
相关关键帧: 00:28:40 QAT Hessian
spectrum;00:30:10 加速 QAT 的 weight re-initialization
QAT 有一个问题:loss
下降很快,但到了很早期就停止下降了,全精度会一直 continue
下降,量化网络在很早期就 plateau。越低比特这个问题越严重。
假设:量化网络是离散的,有很多 flat region,gradient
趋近于零,导致难以继续下降。打印 Hessian distribution 发现:如果
Hessian matrix 有很多接近零的成分,说明是鞍点形状——有正 eigenvalue
也有负 eigenvalue,最终滞留在鞍点而不是往能量最小方向走。需要给
weight 一些扰动让它继续更新。
算法:在 QAT 中,全精度 weight(W)和量化
weight(QW)之间有距离,这个距离导致 gradient
计算不准和滞留鞍点。做法是把全精度 weight 往量化 weight
方向拉一点(interpolate),给扰动让它继续
update,同时缩小全精度和量化之间的 discrepancy。Empirically
插值系数 0.4 效果较好。原来 loss 下降很慢,一插值就又降很多;再
plateau 时再插值,又降很多——训练变快了,最终 loss 更低。
06|00:30:32--00:33:33
相关关键帧: 00:31:40 MobileLLM-R1
标题页;00:32:10 MobileLLM-R1 训练管线
最后一篇工作(ICLR 2026,今年 4 月
conference),关于自进化算法中数据如何选择。DeepSeek R1
出来后大家关注 post-training 中如何激发 reasoning 能力,但
pre-training 阶段因为训练量大,很少有工作设计如何 curate data
来帮助后训练激发 reasoning 能力。
三个阶段:pre-training、mid-training、post-training。Pre-training
阶段先找哪些 data 对训练有帮助——用 leave-one-out
ablation:训练多个 trial,一个用全部 7 个 dataset,另外 7 个每次
remove 一个,看每个 dataset 对结果的影响。
07|00:33:33--00:36:33
相关关键帧: 00:35:10 Pre-training 中用 influence
score 平衡能力
发现所有 dataset 都有正贡献,但 FineWebEDU 贡献最大。FineWebEDU 是
web-credited 数据,有各种
knowledge,像把各种能力粘连起来的桥梁——没有它,模型在不同数据间容易
out of distribution。但这只是定性判断,下面需要定量 mix 不同
dataset。
Computing influence score:给 validation set 和每个 incoming
data,计算 data 对 test set loss 是帮助下降还是上升,算一个
H-matrix(用 approximation 方法),得到 sample level 的 influence
score——每个 sample 对 model training 是正作用还是反作用。Aggregate
起来作为 dataset level 的 joint influence score(取不同 checkpoint
的加权平均),就可以 close-form 算出 weight mixing ratio(与 joint
influence score 成正比)。加了 weighting 后 perplexity 降了不少。
08|00:36:33--00:39:36
相关关键帧: 00:37:40 Mid-training knowledge
compression;00:39:10 Token efficiency
Mid-training 阶段:dataset 数量更少,更集中到想要激发的
capability(如 reasoning、math、coding、knowledge)。会算每个 data
的 influence score,只保留有正帮助的。训练完得到新 model,替换
influence score 计算用的 model,根据当前 model status
再筛选——iterate 两遍后发现 stage 2 时大部分 data
已经只有副作用了,说明进化过程收敛。筛选完 data 后 accuracy
稳步上升,不会抖动,最终 accuracy 更高。
亮点:别人说千万级 model 要训练 36 万亿 token 才能激发
reasoning,MobileLLM-R1 只需 4.2 万亿 token,且 data 都是 open
source、3rd party dataset(不是 in-house),training efficiency
大大高于之前工作。
MobileLLM-R1.5 用 on-policy KD:让 student 生成
trajectory,teacher 基于 student 的 trajectory 给
guidance——context 是 student 的,attention 算在 student context
上,训练和 inference gap 更小。Student 每一步基于自己生成的 data
做判断,inference 时更容易得到正确答案。
09|00:39:36--00:42:36
相关关键帧: 00:39:40 RL perspective on on-policy
KD;00:40:40 MobileLLM-R1.5 结果
MobileLLM-R1.5 能极大提升 accuracy。R1.5 的 950M 参数在 public
benchmark 上已经比 DeepSeek R1 的 1.5B 参数 accuracy
更高——这些都是 reproduce 并 fully match 官方 report 的结果。而且
model 只有 60% 的 parameters,比 DeepSeek R1 1.5B 还要更高的结果。
进入 Q&A。第一个问题:量化这一块,小参数 agent
在端侧是否有很大前景?回答:前景毋庸置疑。苹果、Samsung 都关心端侧
model 如何 integrate 到 Siri,revolutionize 接口,让 LM 变成 app
调度中心。未来人打开手机是一个界面,跟端侧 model 对话,model
去调用
applications。端侧应用包括手机、眼镜、机器人、无人车等。量化也不只是端侧——大家想在有限资源下跑更大
model,更高效降低成本。量化到 4-bit 基本上 for
free(四倍节省空间)。
10|00:42:36--00:45:36
关于 RSI 的关系:自进化需要更低的成本,量化能降低成本、更多
iteration;端侧还能做 personalization,让 model 更符合用户预期去
update 自己。
第二个问题:量化到 8-bit 或 4-bit 后,能力上界在哪里?不同 bit
的能力上界有没有一条曲线?以及除了量化,稀疏模型等其他低成本方案的潜力能否和量化比较?
回答:8-bit、4-bit 基本上是无损的。QAT 做得好时 4-bit 能接近 full
precision。更低比特更挑战,不同 use case
对精度要求不同。关于稀疏和量化:公认量化比稀疏压缩程度更高——BF16
压缩到 4-bit 精度损失很小,稀疏做到 20%-30%
压缩已经很极限,不太可能无损。但两者不完全互斥,可以叠加。
11|00:45:36--00:48:40
追问:是否有类似 Kolmogorov 复杂度限制的理论?回答:ParetoQ(ICML
工作)做了 scaling law——更大 parameter 加更低 bit vs. 较小
parameter 加更高 bit,有没有 tradeoff?结论是 4-bit 比 8-bit
好,2-bit 比 4-bit 好(但 2-bit 和 4-bit
之间有些场景不同:某些场景 2-bit 更好,高精度或 long context 场景
4-bit 更稳)。
联合主持人熊宇轩介绍下一位讲者张少坤:英伟达研究院
scientist,从事智能体训练与强化学习,2026
年在宾夕法尼亚州立大学获博士学位,博士期间在 NVIDIA
和微软雷蒙德研究院工作,研究兴趣集中在智能体 RL 和 computer use
agent,20 多篇顶会论文(大多在 ML 三大旗舰会议),多篇一作获
Oral/Spotlight,Google Scholar 引用超 5000 次,ICLR 2023 Agent
Workshop 最佳论文奖,AgentOptimizer 第一作者,相关工作被 Forbes
报道。
细节层:张少坤
本节覆盖 00:49:44--01:19:14。
01|00:49:44--00:52:45
相关关键帧: 00:50:05 Self-evolving
Agent;00:51:05 self-replicating machine 类比;00:51:35 experience
generation 迷宫;00:52:35 AgentOptimizer: agent = model + harness
张少坤开场分享对 self-evolving agent 的理解:两个主要特性——第一是
recursive
learn(递归式自迭代学习);第二是通过自己的探索从自身经验中学习,而不是依赖外部
data。
他提到 von Neumann 的 self-replicating machine 概念:通向 AI
的必要条件是机器能自己看到自己的组成部件并更换它们来更好服务。就像机械臂可以自己给自己找零件把自己拼得更好。早在
2023 年他们就研究了 AgentOptimizer,相关工作集成到了微软产品,2024
年发表。
第二个探索点:让 agent 在不同环境里大规模 rollout
采集经验来学习——这是 agent RL 的新范式,也是通向 self-evolving
agent
的必要路径。就像小老鼠在迷宫里需要大规模不停试错才能走出迷宫——这也启发了最早期的强化学习。
02|00:52:47--00:55:47
相关关键帧: 00:54:35 AgentOptimizer loop
张少坤解释 AgentOptimizer 的核心:agent = model + harness,harness
里面有 prompt、tool、workflow、subagent。在 Claude Code 这类复杂
harness 中,tool/prompt 可能包括 subagent,系统变得更复杂。如何让
agent self-improve?按照 von Neumann 的思路,让 agent
自己看到自身结构——model 对 agent 来说很难理解,但 harness
层面(tool、prompt)大部分以自然语言方式存在,容易被 agent
理解。所以 idea 是让 agent 去看自身的 tool 和
prompt,根据在环境中的表现修改 harness。
具体做法:先让 agent 在不同 environment
里做任务(像小老鼠放进迷宫),然后 evaluate 得到 reward,把 reward
喂给 agent 让它自己看 tool、prompt、workflow,做增删改查更新
harness,变成新 agent 再放进环境下一轮迭代。这个实验在 ChatGPT 3.5
上做的,早在 2023 年就已经能看到 agent 有 self-improve 的潜力。
03|00:55:47--00:58:47
相关关键帧: 00:57:05 Self-evolving learning
curve;00:57:35 ProRL Agent Server
展示实验结果:test performance 和 training performance
都提升了,在 out-of-domain 环境中也确实提升——agent 拥有了更好的
harness/tool/skill,而且这些都是 agent
自己根据经验探索得到的,不是人设计的。还展示了 agent
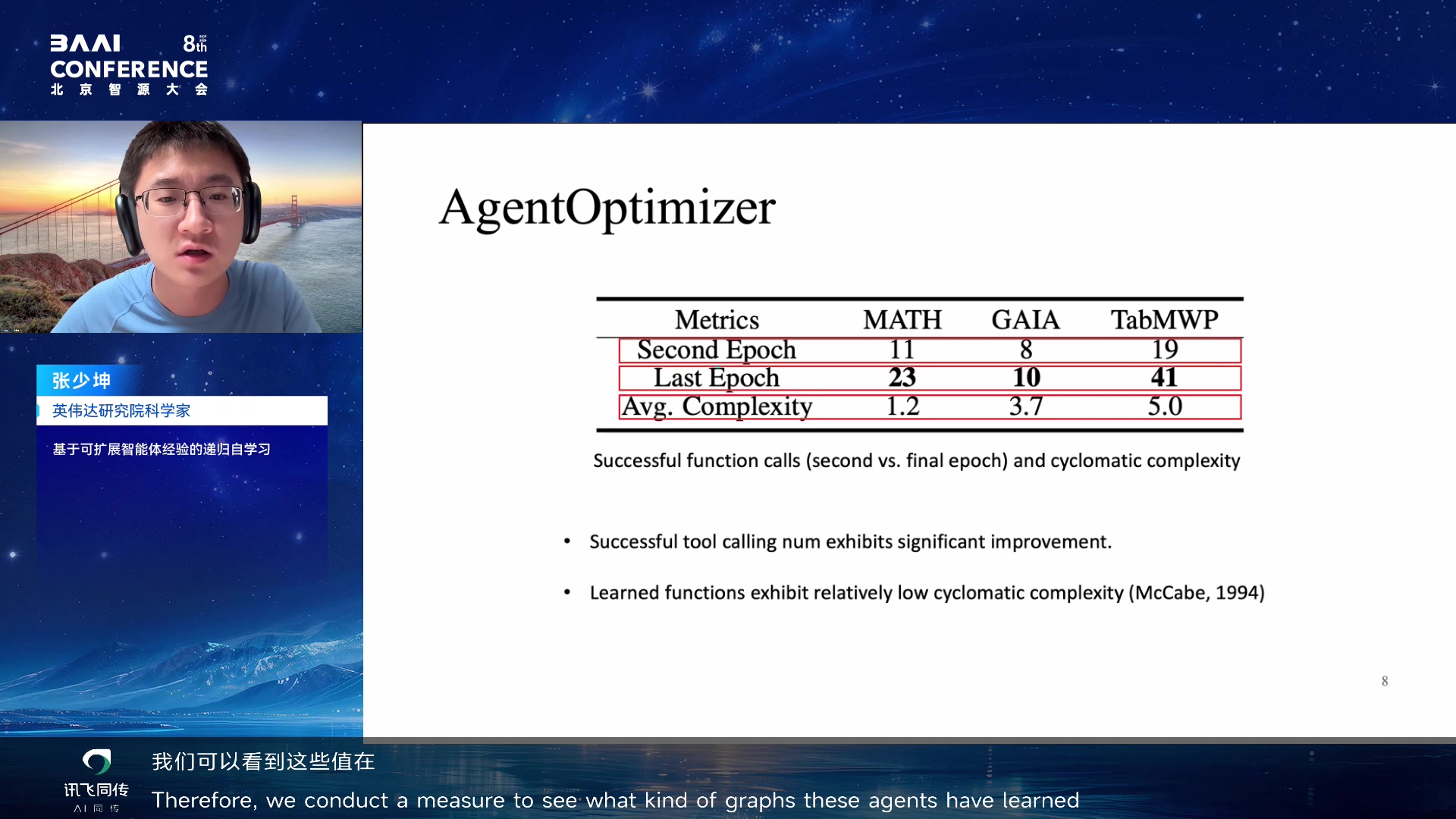
在自我优化不同 epoch 中使用自己生成的 tool 的频率明显提升。第三个
metric 是 cyclomatic
complexity(软件工程中衡量代码质量的指标,小于 10
算高质量)——agent 生成的 skills/tools 大部分都小于
10,说明学到了又好又简洁的 tool。
AgentOptimizer 是一个早期 effort,证明在不是那么强的 model
上也能看到 recursive 的潜力。随着 model skill up
能力越来越强,self-improving 的能力也会越来越强。
接下来介绍 ProRL Agent Server——让 agent 能够在不同场景里大规模
rollout,从自身和环境交互的 experience 中学习。Agent 的 rollout
和普通 LM rollout 不同:是 multi-turn,需要 sandbox、docker,RL
训练时可能要同时起成百上千个 sandbox。
04|00:58:47--01:01:47
相关关键帧: 01:01:05 coupled 与 decoupled design
对比
当前 RL Trainer 的做法:有一个 RL Trainer infra 和 Inference
Engine,Trainer 和 Engine 交互来训练 model。但换到 agent
场景就非常复杂,因此开发了 ProRL Agent Server 在中间。它支持任何
Trainer(VeRL、SRL 等)和不同 Inference Engine,完全 decouple 了
Training 和 Agent rollout。
当前做法的问题:RL training loop 里要加入 agent rollout loop(启动
sandbox、docker、tool execution、获取 reward),这部分代码
hardcode 到 RL training loop 里。做 agent harness 研究的人必须
touch RL 部分,做 RL 的人必须 touch agent harness 部分——非常复杂。
ProRL Agent Server 把 Training Loop 和 Agent Rollout Loop
分隔开,建立 Proxy HTTP Service。RL Trainer 发送 Agent Rollout
Request,ProRL Agent Server handle 所有 agent
相关的执行,Inference Engine 完成 rollout 后把 trajectory 返回给
RL Trainer。
05|01:01:48--01:04:50
相关关键帧: 01:03:35 ProRL architecture
核心 design:agent 每次 call LM 之前,中间加一个 proxy,捕捉 agent
到底 call 了什么,把 trajectory 收集起来返回给 RL
Trainer。这样大家不需要关心 agent harness 是什么——Codex、Claude
Code 还是其他复杂 harness 都没关系。
ProRL Agent Server 有 Gateway Nodes,负责接收 RL
request。四个阶段:Init(准备 sandbox、装包、准备
data)、Run(agent 真正工作)、Build 和 Evolve(merge
trajectory、计算 reward、发送给 Trainer)。Trainer 训练完后和
Inference Server 做 weight sync。Repository 已经开源到 GitHub。
06|01:04:50--01:07:51
相关关键帧: 01:05:05 async worker
timeline;01:06:35 prefix merging
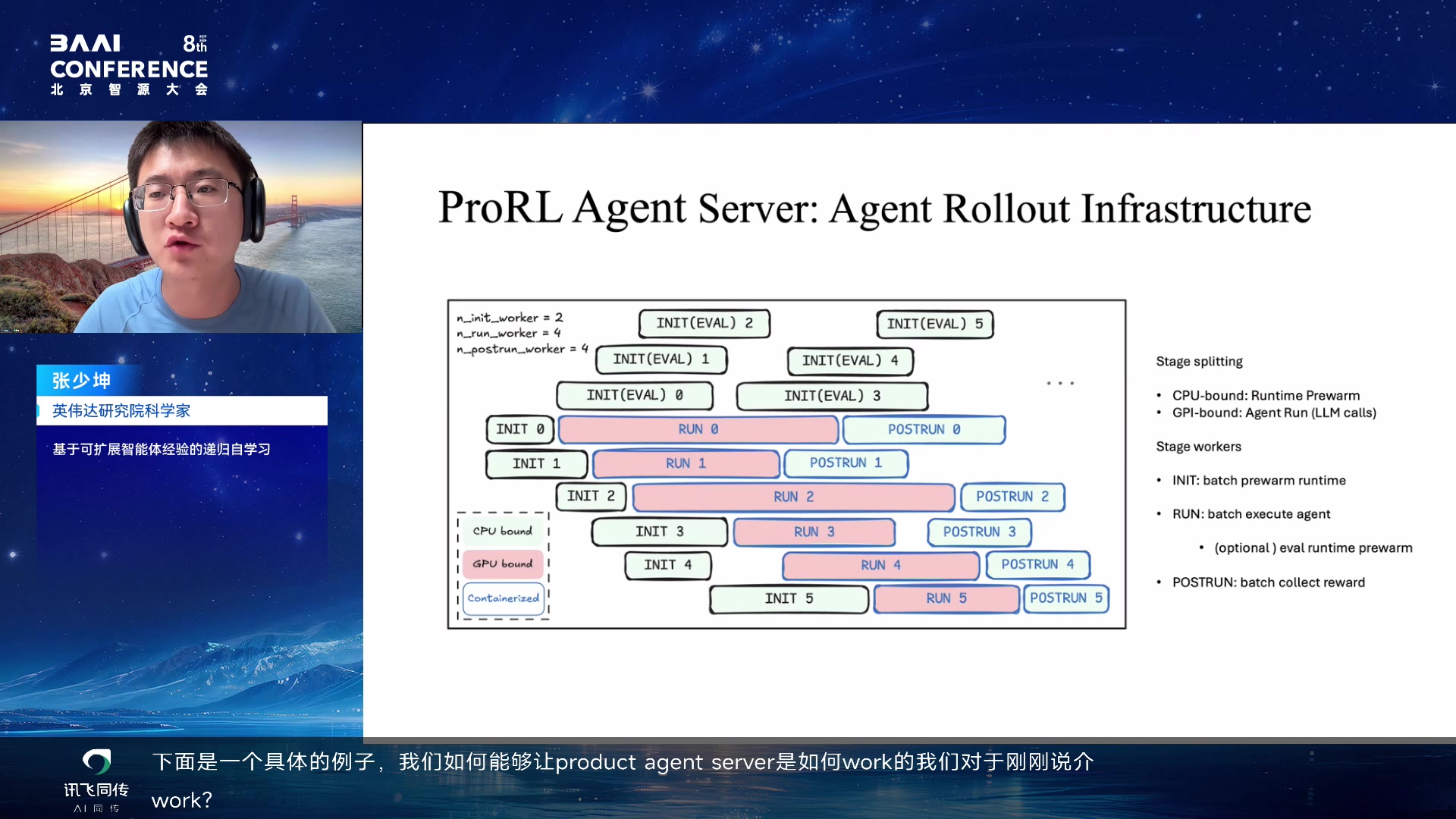
具体例子:Gateway Node 里面不同 stage 有并行多个 worker(Init 2
个、Run 4 个、Post-Run 4
个),像流水线一样,谁闲置谁开始工作,完成后传给下一阶段——大幅增加
rollout 效率,就像小鼠同时在几百个迷宫里探索。Init 阶段依赖
CPU(装包、准备 sandbox),Run 阶段依赖 GPU,可以根据硬件合理分配
worker。
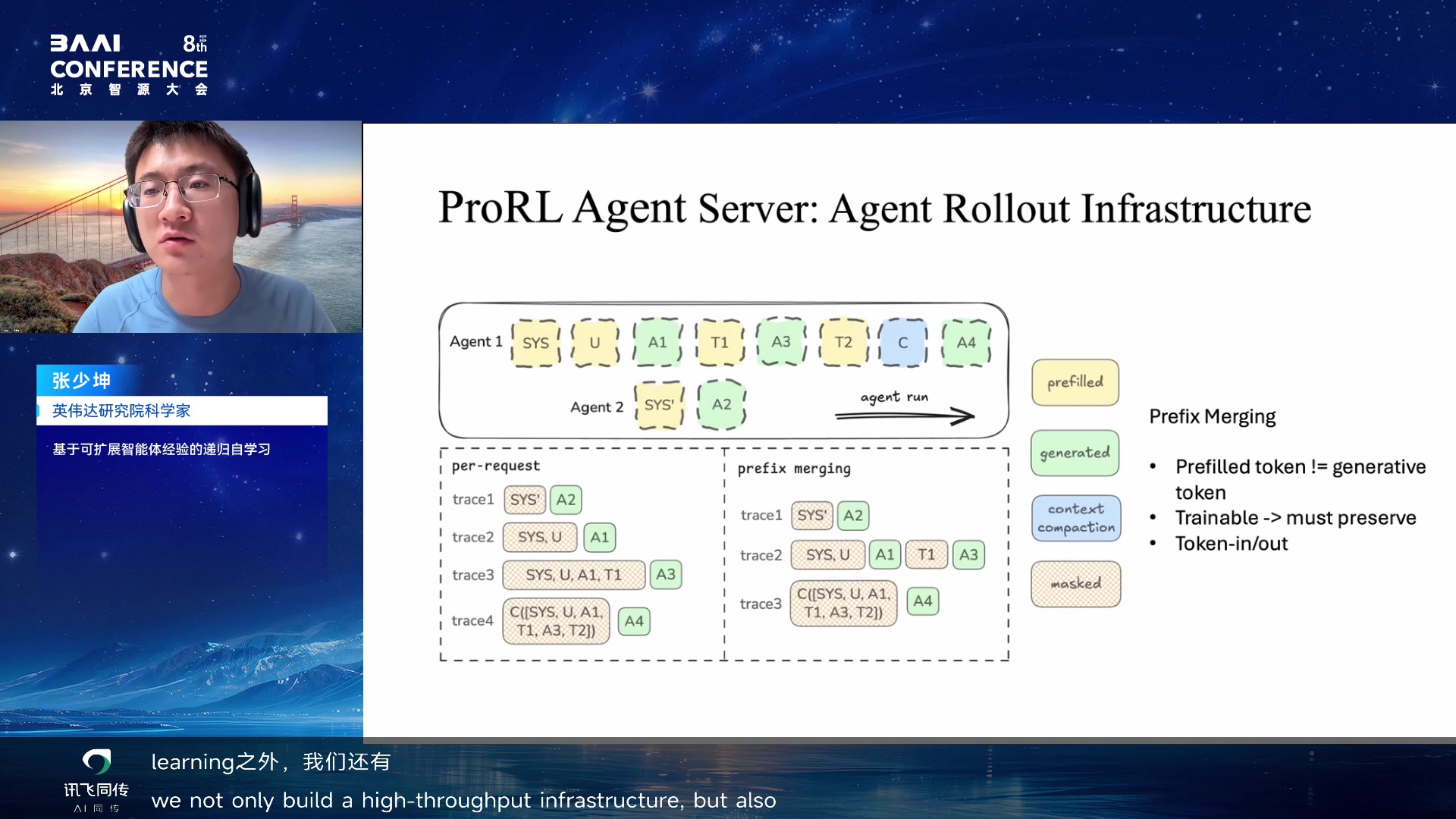
Prefix Merging 特性:训练复杂 harness(如 Claude Code,内部有
subagent)时,trajectory 非常凌乱。如果 trace2 和 trace3 share
相同前缀,可以 merge 成一个 trace,梯度只加到 LM 吐出的 token
上,不是 LM 生成的 token 加 mask。这样 4 个 trace merge 成 3
个,保留了 trainable 信号传给 RL Trainer。
07|01:07:51--01:10:54
相关关键帧: 01:08:35 多 harness rollout 指标
实验:训练了 4 种最常用的 harness(Codex、Claude Code、Qwen
Code、PyAgent),base model 用 Qwen 3.5 4B。在 SWE-Bench 上只用了
293 个训练 example,一个 epoch 后 Codex 有 22.6% 提升——证明 infra
有效,4B model 也能掌握复杂 harness。
GPU utilization:异步设计使 ProRL Agent Server GPU 利用率一直
100%,Trainer 大部分时间闲置(只有得到全部 rollout 才能
training)。Prefix Merging 也能增加吞吐。ProRL Agent Server 给
Trainer 传递 rollout ID、response ID、loss mask 等所有 RL Trainer
需要的信息和 metadata。
ProRL Agent Server 已开源,pip install 即可安装,支持不同
inference engine(VLLM、SGLang),提供 SWE-Bench 训练 example
可一键部署。Welcome contribute。
08|01:10:54--01:13:56
张少坤总结:相信 recursive 和大规模 agent rollout 是实现
self-evolving agent 的必要路径。ProRL Agent Server 目前在 RL
场景下验证,但相信未来可以 move 到让 agent 自己给 reward 信号进行
self-evolve。
Q&A
开始。北京工业大学张老师提问:做工业机器人的智能体协作,从机械流水线改造成机器人。遇到困难:智能体自学习效率不高,想改机械结构但一旦改了所有数据全废;数字孪生建模数据跟现实对不上,物理因素有缺失。问机械结构上智能体和大脑思考智能体的自学习如何加快。
张少坤回答:机器人自由度更多,VLA 中用 diffusion model decode
action 而不是 autoregressive。Failure mode
来自物理因素,建议大规模 rollout 收集 failure mode,拿 critical
data 训练。
09|01:13:56--01:16:57
第二个问题:agent 自进化也会有 overfitting 倾向,如何避免让 agent
更 generalization?
张少坤回答:确实 overfitting 问题很多,做 SWE-Bench 和 computer
use agent 也会遇到。解决方式主要从训练数据层面增大
diversity——提前决定 diversity metrics(agent
轮次、工具种类、工具频率等),再通过这些 criteria 选数据。
追问:能不能在 rollout 时增加密度,做一些判断,用 loss 等方法
filter 好的路径,像 gradient 一样进化出好的方式来克服
overfitting?
10|01:16:57--01:19:14
张少坤提醒:在 RL 阶段,如果在 rollout 中扰动 agent,可能导致
off-policy 问题。建议不要在 rollout 阶段动 agent,让 agent
自己探索、发现薄弱点。过滤和增加 diversity 应该在 rollout
结束之后做。
主持人介绍谷雨:NeoCognition 联合创始人兼 Head of
Research,近期完成 4000 万美元种子轮融资。毕业于 Ohio State
University,获 ACL 2023 和 COLING 2022 杰出论文奖,长期担任
ACL/NAACL/EMNLP/NeurIPS 领域主席,发起深度谈话节目
Ungrounded。谷雨开始演讲。
细节层:谷雨
本节覆盖 01:19:14--01:46:54。
01|01:19:14--01:22:16
谷雨开场表示不会讲太具体的工作,而是唱反调,讲偏原理性的东西。标题
The Illusion of Self-Improving Agents,对近期 self-improving
agents 热潮的反思和第一性原理思考。
Self-improving agents
最近非常火热(截图可能两个月前就过时了):OpenClaude、Ermine
等都在 claim 通过长期记忆实现 self-improving;OpenSpace、ClaudeHub
等开源项目也关注这个方向。OpenClaude 官方 scale
平台下载量榜单前四名中至少两个和 self-improvement 相关。
为什么 self-improvement 在这个阶段变得重要?逻辑很清晰:当下 LM
训练仍然是被动 setting——人类专家控制训练流程、数据制造、RL
环境制造,从预训练到
post-training(SFT/RL)都由人定。但很快发现数据是最大瓶颈——几乎所有
frontier lab,不管中国还是美国,数据都是最大问题。模型上线后产生的
interaction 没有被及时消化成学习信号——模型上线就 frozen
了。如果未来要 saturate 10T 甚至 100T
的模型,光消耗人标数据或互联网数据大概率无法饱和这种参数量级。
02|01:22:16--01:25:16
谷雨把 self-improve 拆成两个维度:self 对应 proactiveness(agent
自己决定学什么、什么时候学),improve 对应
learning(具体怎么实现学习——训练、收集数据等)。今天更多讲
learning。
关于 learning 的核心指导原则:learning 可以看成对 memory
的更新。Learning 和 memory 是硬币的两面——learning 的本质就是更新
memory,更新后基于新 memory 做新 inference。Memory 包括 markdown
files、RAG 的 vector database、模型权重本身(最大的 long-term
memory)。
Learning 涉及三个层面:representation(怎么表示
memory)、update(怎么更新 memory)、execution(更新完后怎么基于
memory 做新 inference)。对这三个层面的预期性质:representation
需要抽象和结构;update 需要可靠更新算法(保证见到 1000 个 case
一定比 100 个好,而不是重写十次还不如一次生成);execution
需要闭环验证。
03|01:25:16--01:28:16
谷雨进一步展开 representation 和 update 的关系。Abstraction
的本质是从具体 case 提炼出更 high-level 的共性,有了共性就能
reuse(就像形成了"人"这个概念后可以指代所有人,不需要为每个人发明新概念)。压缩算法(如
GZIP)的核心就是 reuse common pattern,compression intelligence 也
related——更好的压缩意味着更好的理解。
用猫狗/颜色例子说明:小孩一开始可能把棕色动物都当猫、白色都当狗,见到白色猫就不知道怎么更新。但如果有树/图的结构,新信息可以很容易
compress 进 structure,完成 reliable
update。当然这是简化例子,人实际学猫狗时基因里有大量 prior。
更真实的例子:公司内部业务逻辑——处理商单/发票,根据金额和类型分配给不同员工。规则是
latent 的,也不是一成不变的。用决策树表示,大约 100 token
就能学到内部结构;而 markdown 方式每次来新 case 就更新 skill
file,几十次后变成 2000+ token 的复杂文件。结果:决策树 77%
准确率,markdown 只有 28%(比随机 20% 好一点)。
04|01:28:16--01:31:16
谷雨展示学习过程:根据树的结构可以 incrementally
expand,不会破坏之前的内容——看到新 conflict 就增加一个
branch,非常有针对性的结构更新。而无结构文本每次重写就可能带来破坏,很难保证
reliable update。
Revisit 现有 solutions 的 Pros and Cons:文本表示有一定
abstraction 和 compression(语言本身是基于概念的),但几乎没
structure,更新完全依赖 LM 本身改写,很难保证 reliable
self-improving。Vector database 更新方式基本是 append,不做
abstraction/compression,不断往里面 paint——违反了 representation
需要 compress structure 的
desiderata。模型权重(分布式表示)有很好的 compression rate
和几何结构(为梯度下降算法提供了前提),但持续学习和 online
learning 面临 catastrophic forgetting 问题。
他提到可以从传统 Symbolic AI 学习:虽然十几年前大家觉得 Symbolic
AI 已死,但在 LM 时代反而可能有新机会。比如处理知识冲突时需要
priority、confidence、保留 evidence、multi-context
management(冲突命题在各自 context 下是对的)。
05|01:31:16--01:34:39
继续讨论 Symbolic AI 的启示:当人的 preference
前后不一致时,怎么表示?需要为每个命题同时提供
context,但这个例子本身不是重点——关键是传统 symbolic AI
研究过的很多问题今天又重新出现了。
关于 execution:今天 self-improvement agent 最大问题是把更新完的
memory/skill 放进
prompt/context,这是最主要的使用方式。问题:第一,把 memory 放进
context 没有任何
guarantee,模型可能忽略、误解、使用错;第二,没有直接执行的闭环——不是真的在执行
memory,只是在 prompting 模型。Feedback 通常让 LM self-reflect,但
failure 不是直接 ground 到真正执行上,而是基于 LM
自己的分析。更根本的问题:所有更新如果都基于 LM 本身,就等于用 LM
完全代替 Optimizer(related to TextGrad 类工作)。
关键观点:Memory 需要真的能够被执行。有了真正的执行闭环后,执行
failure 和信号可以传回去,更好地 inform
memory。这也是他一直说的"learning at inference +
memory"——人的学习从来不分"先 learning 完了再纯
inference",而是解决问题的同时不断提升理解,这是 unified 的过程。
06|01:34:40--01:37:40
关于 proactiveness(what and when)层面,谷雨简单带过,主要引用
LeCun 两个月前的 position paper:当前 AI 缺乏
metacognition——比模型能力更元层次的能力。要做到模型自己判断学什么,前提是模型要知道自己什么地方有不足。这篇
position paper 提出需要 System M(M =
Meta-Cognition),有了之后模型可以自己判断缺什么、针对什么目标学习、做什么类型的学习(监督学习还是
RL)。Proactiveness 也 related to Loop Engineering——agent
不需要人唤醒,自己不断跑、不断学。
总结真正 self-improving
系统需要三个东西:表示层面——结构化抽象;更新层面——基于结构化表示的可靠更新算法(保证数据越多确实越提升,能处理好冲突而不破坏之前的表示);闭环执行。加上
what and when 层面:what 层面需要 meta
control(知道自己需要学什么),when 层面需要
proactiveness(不需要等人唤醒,自己有 loop 不断验证、提升)。
07|01:37:40--01:40:42
回看今天大部分 self-improving 系统:缺乏结构(更多只是 markdown
非结构或半结构表示,本质还是改写,导致 unreliable
update);同时缺乏执行闭环(memory 作为 prompt injection 只是
conditional generation,不是真的 execution)。总结:现在大部分
self-improving 系统只是在 accumulate data,不一定真的在学习。
这也是 NeoCognition 的使命——做真正的、truly learning 的
self-improvement agent。
进入 Q&A。第一个问题:不少做 agent
自进化的还是在做局部优化,怎么看这个问题?有没有对全局优化的思考?
谷雨回答:不太相信一个模型做所有事。基础能力可以从零分到八十分(现在
LM 可能是 general model),但真正部署时(比如 AI
去公司上班),每个 specific domain
都有非常长尾的知识。针对长尾知识的学习必然需要
specialization——包括针对每个用户的偏好优化。所以比较相信
specialization 而非一个 general model 做所有事。
08|01:40:42--01:43:42
追问:specialized knowledge
形成后,可能可以基于这些结构再生成数据(比如基于决策树生成分类数据,或基于
workflow knowledge 生成更多)。但 structure
需要专家总结吗?如果到了没有专家或超出专家能力的阶段,AI
如何形成自己的学习路径?
谷雨澄清:展示的所有实验相关的东西(包括 structure)并没有人类专家
involve。树的结构是模型自己选择的——模型基于任务性质自己觉得用树来表示比较好。内部系统实现了
meta-cognition
layer,会自己决定针对什么任务构建什么结构。所以不存在人类专家提供先验的说法——如果有人类专家在,可能就不太能被称为
self-improving。
09|01:43:42--01:46:42
谷雨进一步解释:有了 specialized knowledge
后可以有后续步骤——基于决策树生成大量分类数据,或基于 workflow
knowledge 生成更多训练数据。关键是没有人类专家
involve,是模型自己基于 meta-cognition layer 决定结构。
主持人介绍下一位讲者林涛:西湖大学工学院 AI
系特聘研究员、博士生导师、独立 PI、国家级青年人才计划入选者,2022
年博士毕业于 EPFL,ECCV 2024 最佳论文提名,2024-2025
连续入选斯坦福全球前 2% 顶尖科学家。
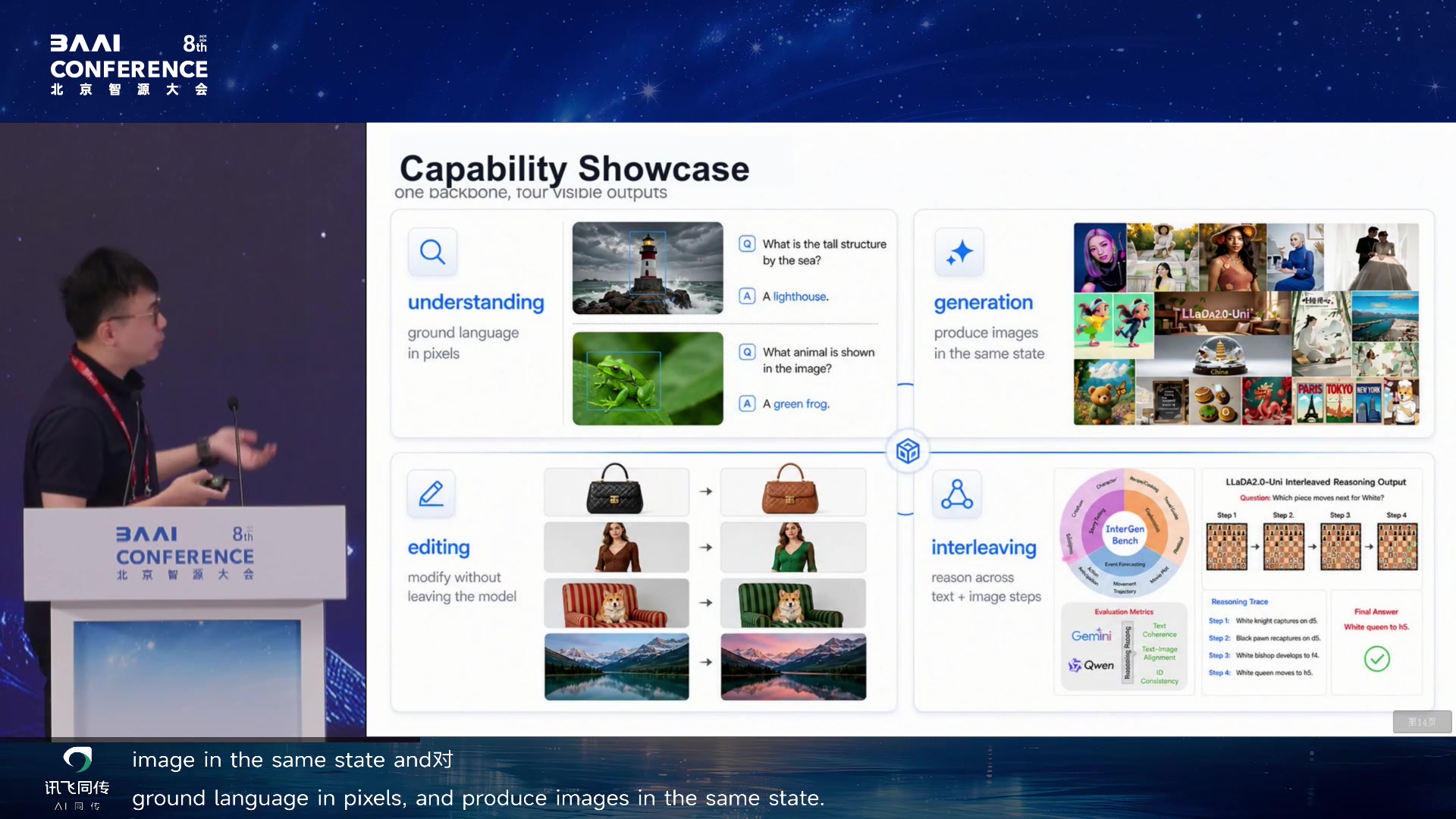
林涛:统一多模态模型中的想象、行动与反馈闭环
多模态生成与理解:缺失的闭环
林涛的开场问题很直接:现在多模态模型已经能看、能画、能编辑、能做简单的
tool
use,但看、画、行动这三件事之间没有闭环。模型的理解不会自动变成更好的生成,生成也不会反过来帮助理解,更不会指导行动并从反馈中学习。
林涛报告标题页:Towards Self-Improving UMMs / WAM 01:46:58
多模态生成与理解应用墙 01:48:25
The Missing Loop:能否用生成、行动、反馈互相学习 01:49:25
他展示了团队训练的统一多模态模型,可以做
VQA、图像编辑、图像生成和简单的 tool use,甚至支持文本与图像模态的
interleaved
generation。但关键问题不是这些能力够不够炫,而是它们能不能帮助
backbone 自我提升。
Generation as Imagination:想象要 grounded
报告中有一个重要转向:generation
不只是输出图片或视频,它也可以被看成 imagination,即模型在内部做
imagined rollout。问题是,想象如果不被 grounded,就会漂亮但错误。
Semantic generation failures:漂亮但不理解约束 01:49:55
Generation as imagination 01:50:25
因此,imagination is not
enough。想象必须接触真实环境,必须能被检查、修正、再生成。否则它只是
demo,而不是学习闭环的一部分。
Grounded Imagination:grounded、constrained、revisable 01:55:55
Unified World-Action Model 与共享状态
林涛提出的统一视角是 World-Action
Model。模型要理解世界、想象世界、采取行动,并从环境反馈中学习。这要求模型内部有共享状态,而不是理解模块、生成模块、行动模块各自为政。
A Unified World-Action Model 01:51:25
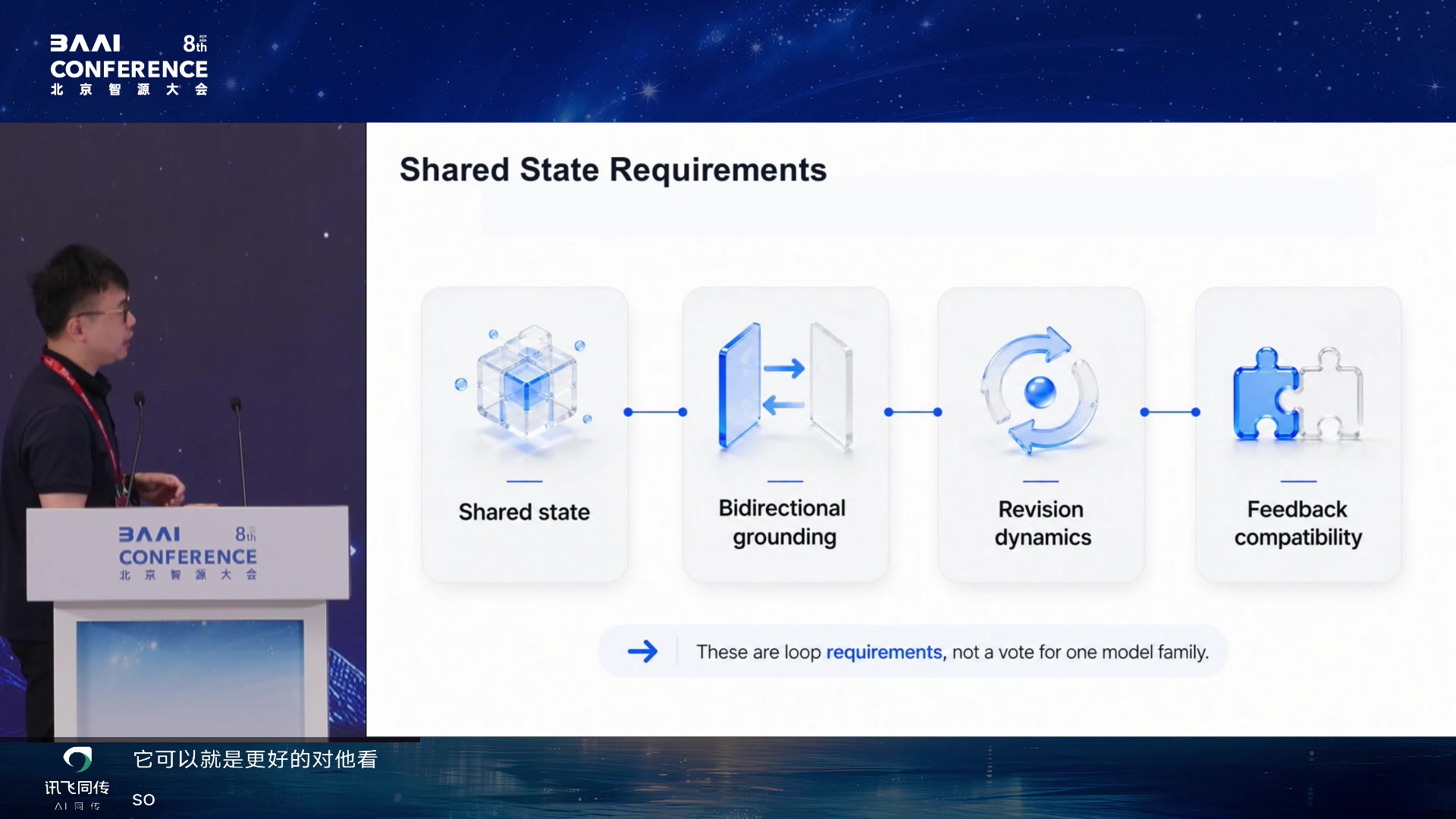
Shared State Requirements 01:52:25
共享状态至少要满足几件事:能双向 grounding,能 revision
dynamics,能兼容 feedback。报告还强调 one token
space:如果理解和生成不在同一 token/state
空间里,反馈很难穿过模块边界进入真正的学习。
One Token Space:统一多模态 token/state 01:54:25
Understanding as Grounding 01:54:55
Interleaved Self-Inspection:plan/generate/inspect/revise 01:55:25
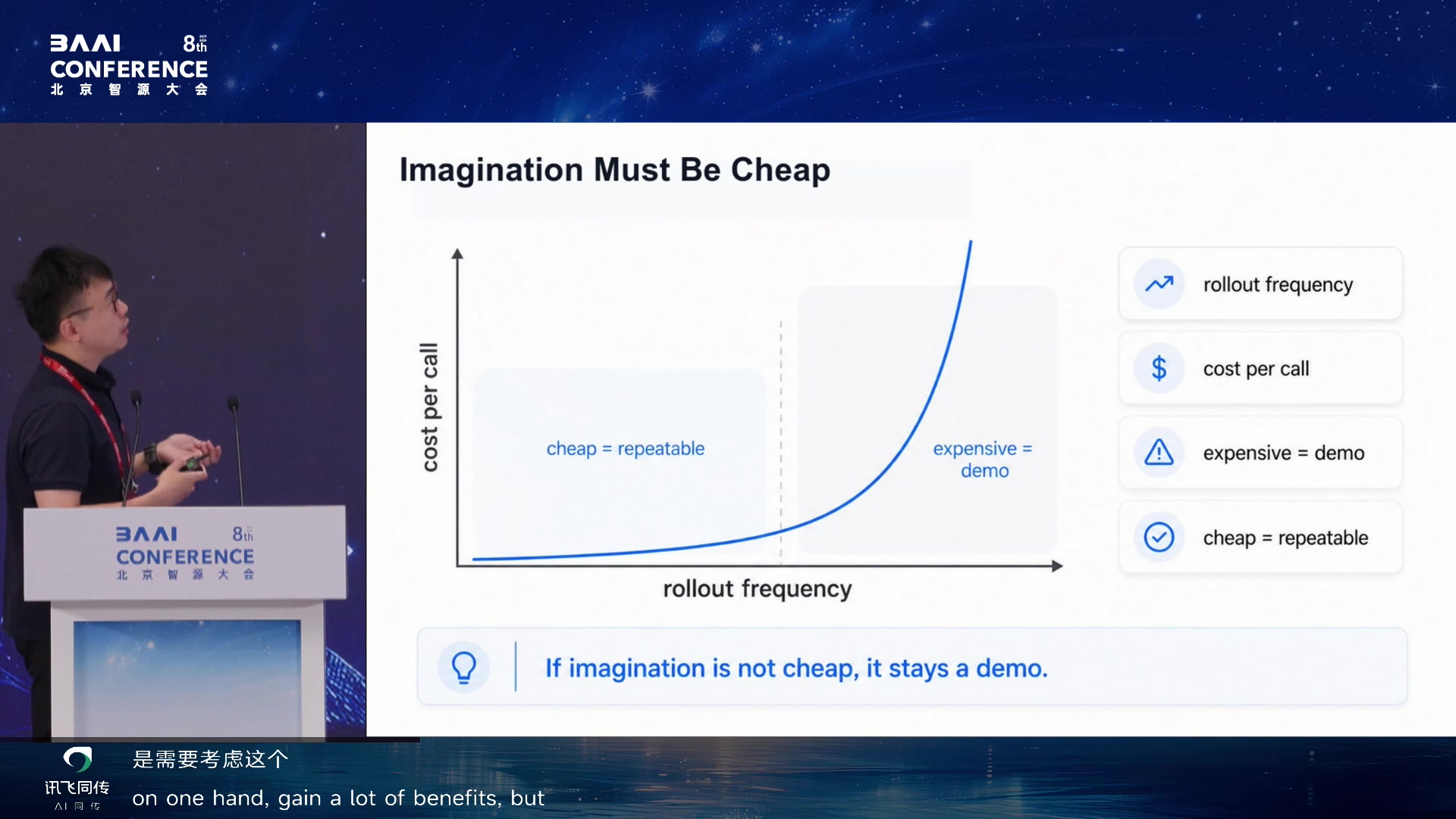
想象必须便宜:少步生成技术的角色
如果 imagined rollout 很贵,就只能做
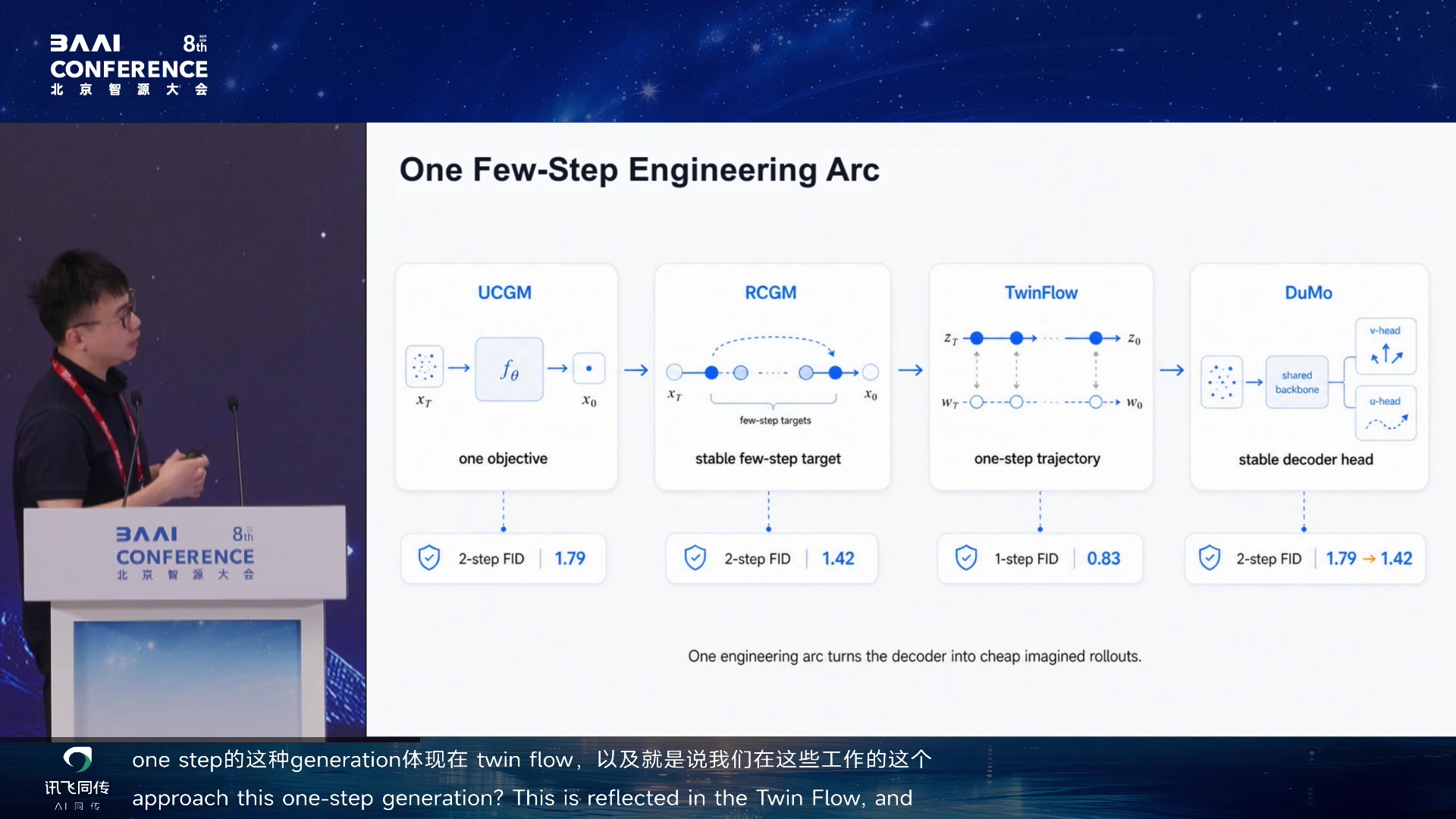
demo,无法形成大量循环。因此少步生成是 WAM 的基础工程条件。报告串起
UCGM、RCGM、TwinFlow、DuMo
等工作,说明如何让生成从昂贵多步扩散走向更便宜、更稳定的少步甚至一步生成。
Imagination Must Be Cheap 01:56:25
Backbone Imagination Engine 01:57:25
One Few-Step Engineering Arc:UCGM/RCGM/TwinFlow/DuMo 01:58:25
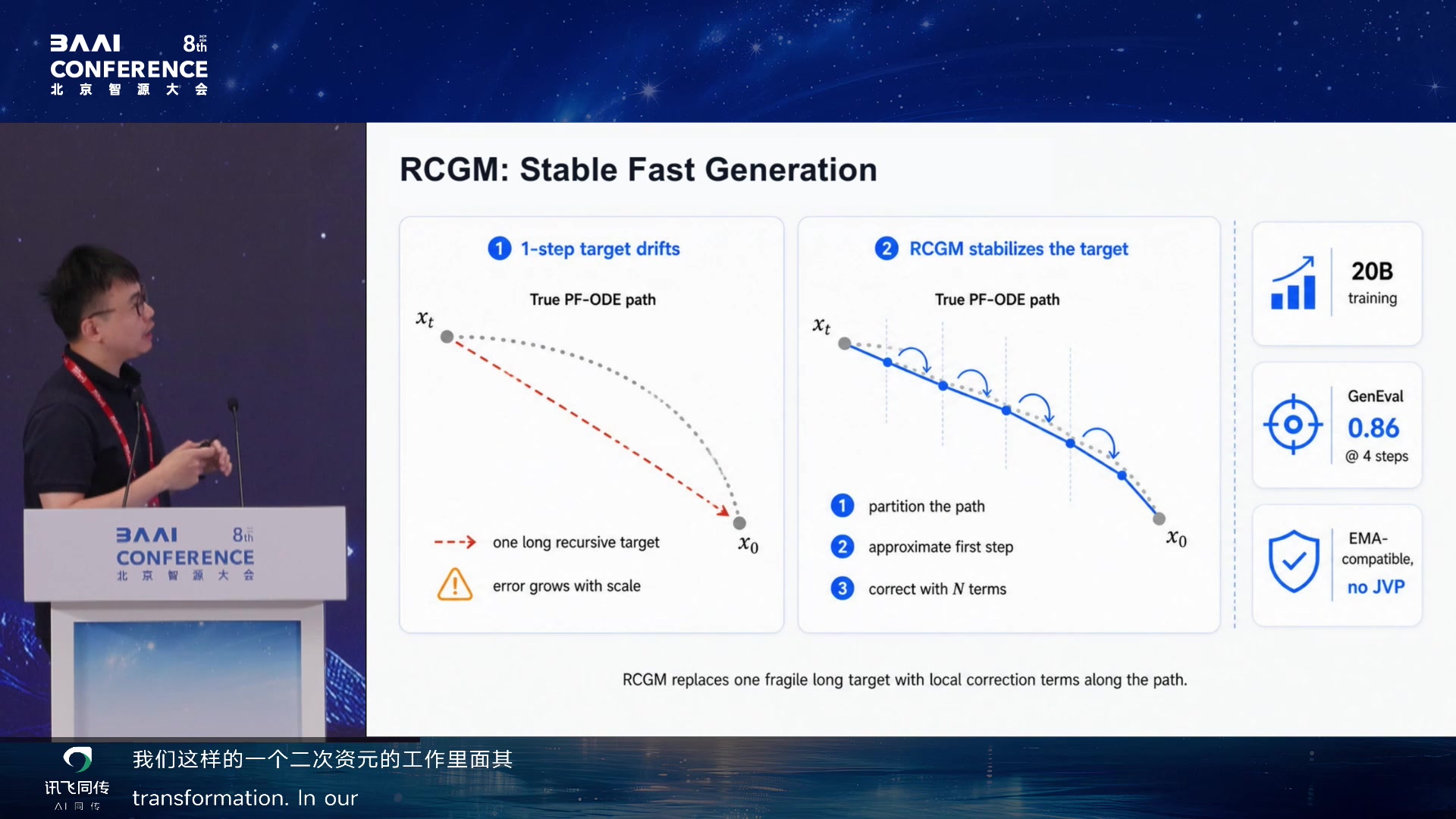
RCGM: Stable Fast Generation 02:00:25
TwinFlow: One-Step Generation 02:02:25
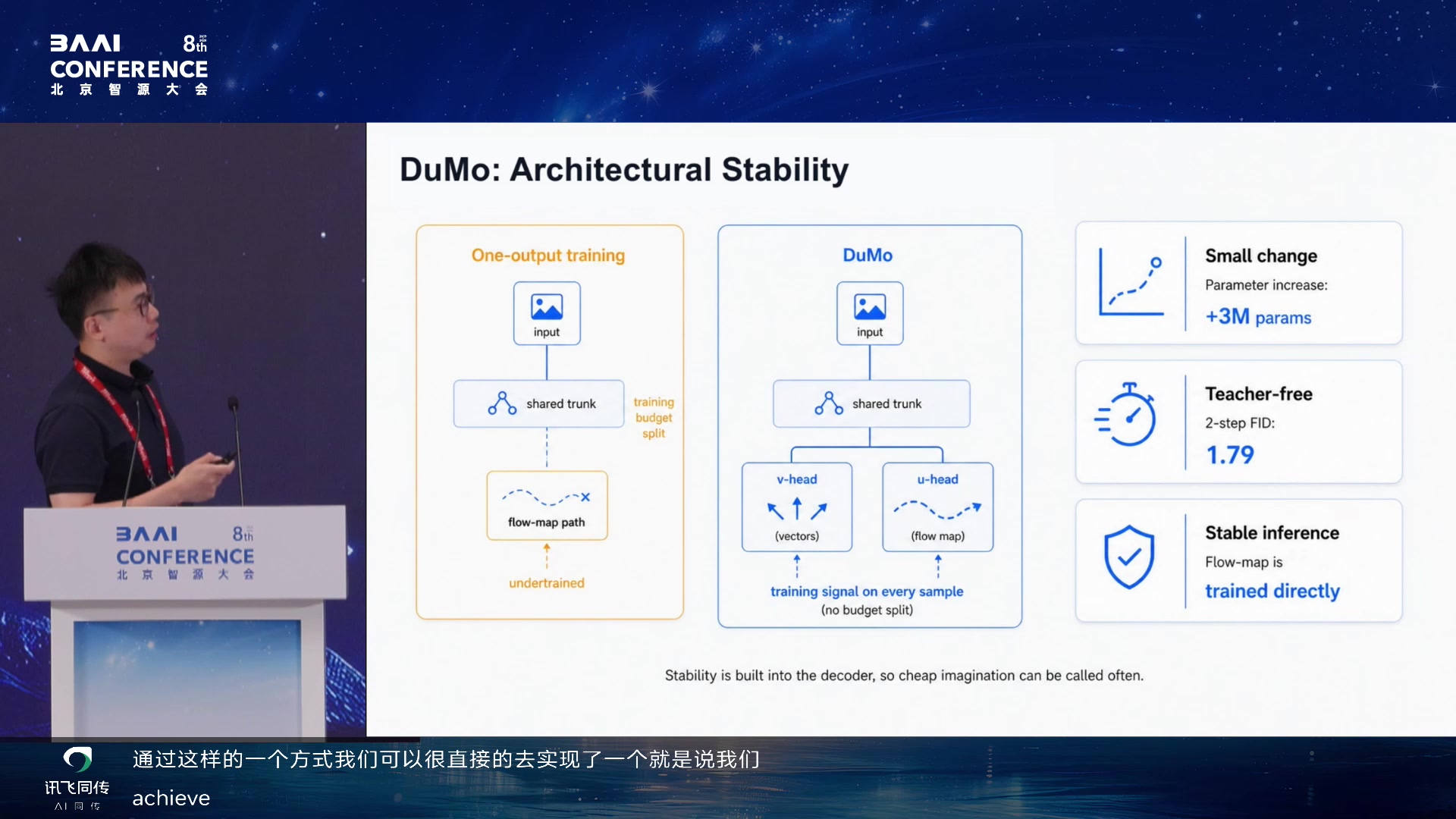
DuMo: Architectural Stability 02:02:55
这些技术在讲义中的学习意义是:生成模型效率不是孤立追求速度,而是在为"便宜
rollout"创造条件。自进化系统需要大量 imagined/real rollout;rollout
越便宜,反馈闭环越可能规模化。
为什么行动进入闭环
行动进入闭环,是因为生成必须可检查。模型不能只生成一个视觉未来,还要能在环境中试探、执行、获取反馈。报告列出几条条件:generation
must be checkable,模型需要
self-check,信号要在模型外部被验证,并能回流到共享状态。
Why Action Enters the Loop 02:04:55
Cheap Rollouts Build Loops 02:05:25
Feedback Lessons We Can Use 02:06:25
最后的 roadmap 把问题拆成四个开放接口:从 understanding 到
imagination,从 imagination 到 action,从 action 到 feedback,再从
feedback 回到
backbone。这些接口决定了多模态模型能否从"能力集合"变成"自进化系统"。
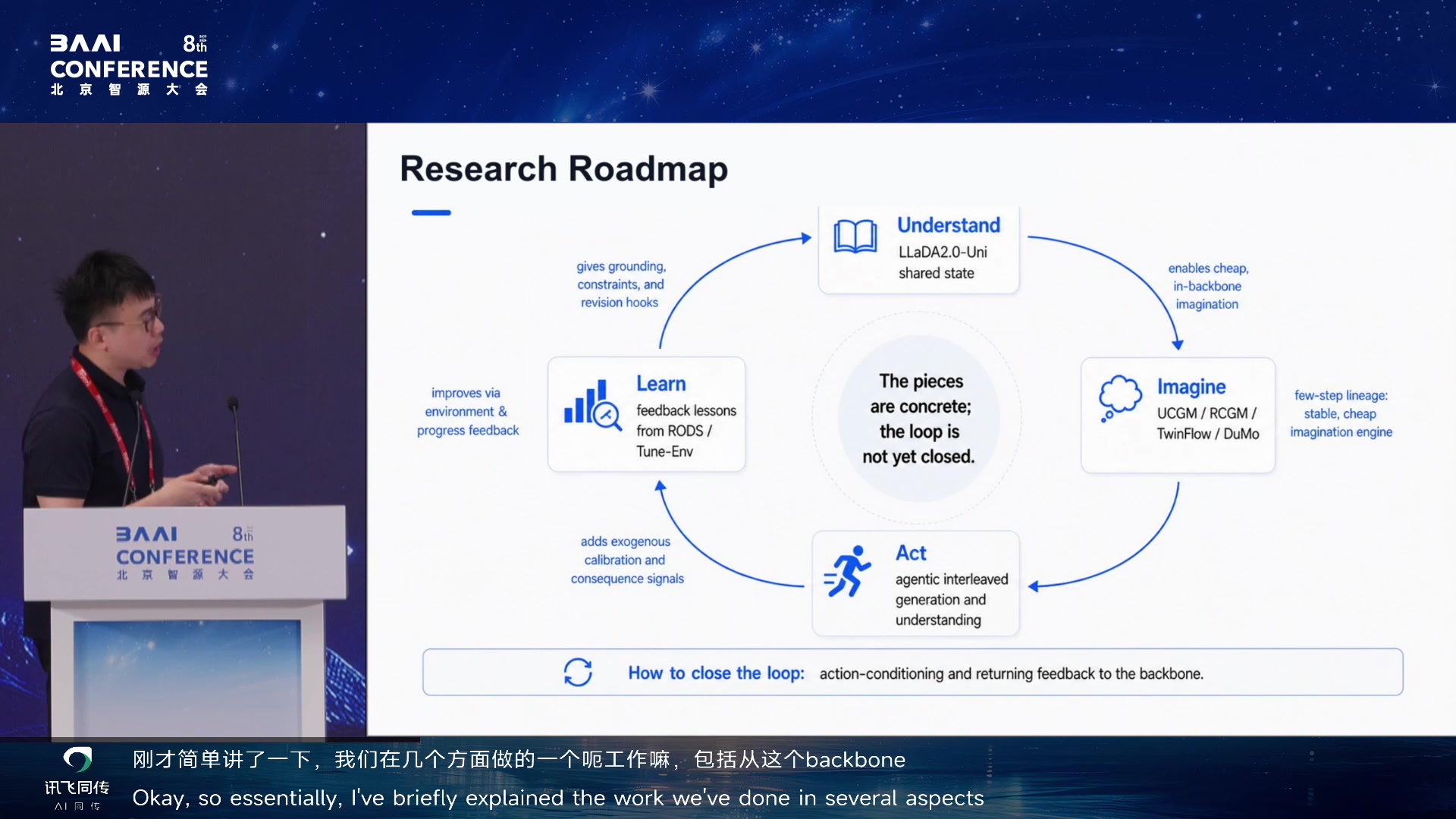
Research Roadmap 02:07:25
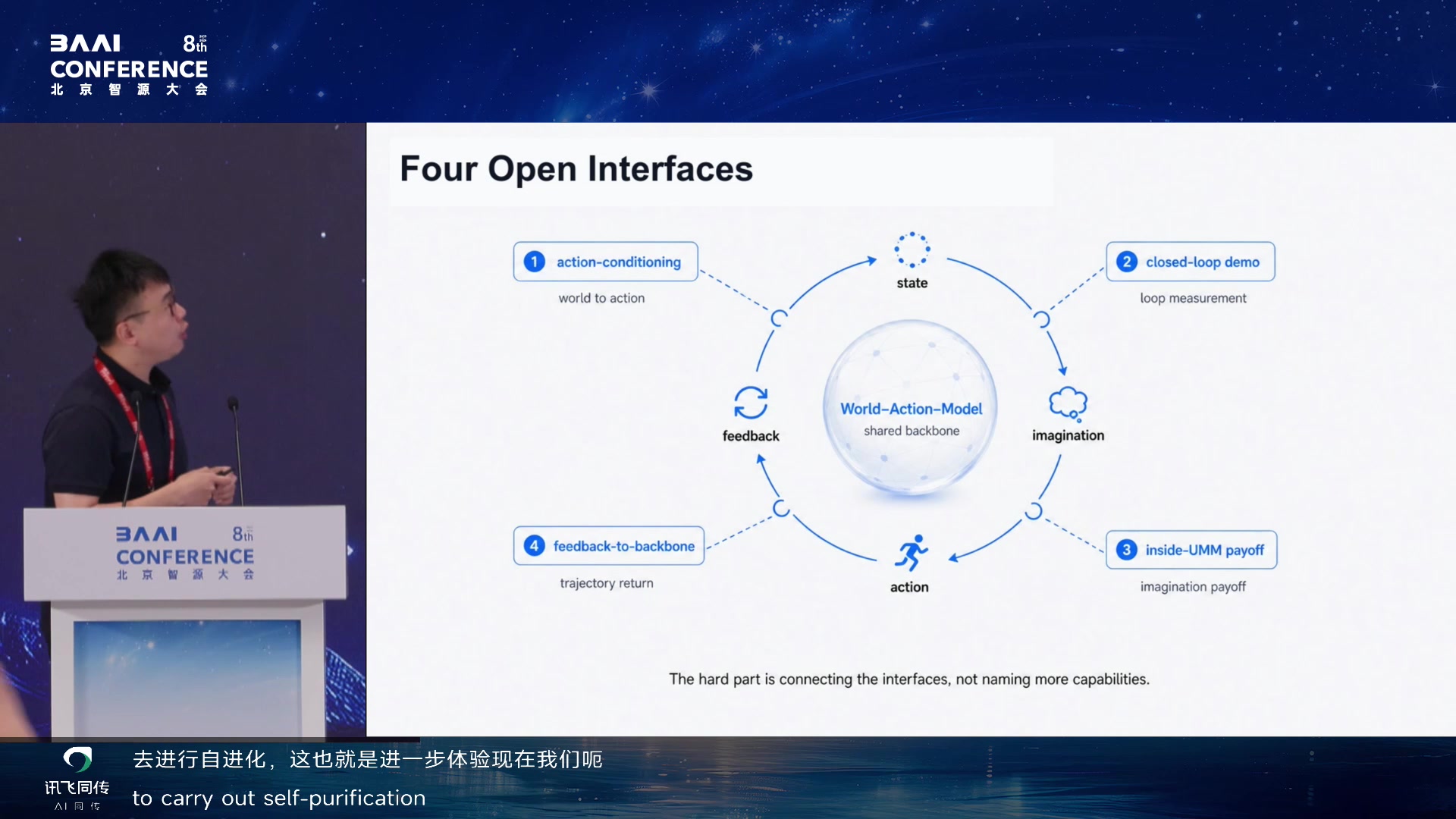
Four Open Interfaces 02:07:55
Q&A:self-improvement 与 active learning 的区别
Q&A 中,听众问 self-improvement learning 与 active learning
的关键区别。林涛回答,关键在 self-awareness:模型要知道自己的
knowledge boundary,并能构建适合自己进化的环境。传统 active learning
更多是选择样本;self-improvement
则要求系统认识自身局限并沿着目标改变环境和训练方式。
另一个问题涉及 data scaling、environment scaling 和 model scaling
的规律。林涛认为这是值得探索的 scaling law
问题:不同规模模型使用数据和环境反馈的能力不同,未来需要把数据、环境和模型协同进化地理解。
本章小结
林涛把"自进化"扩展到统一多模态系统:生成是想象,想象要
grounded,grounding
要行动,行动要反馈,反馈要能改共享状态。少步生成技术在这里不只是图像生成优化,而是让
imagined rollout 便宜到足以进入学习循环。
拓展阅读
王琰:从 Context Engineering 到 Self-Engineering Architecture
模型很聪明,但通用性和灵活性还不够
王琰的报告风格很鲜明,但核心问题非常清楚:当下模型在数学、代码等场景已经很强,Claude
Code
一类系统甚至改变了研究和工程工作方式;但模型的通用性和灵活性仍然不如人。它会陷入死循环,不会自己清
context,不会自己调整 decoding 参数,也不会自然把环境知识沉淀下来。
王琰报告标题页 02:11:35
Central Problems to AGI:智能性与通用性差距 02:12:50
他的判断是:很多早期帮助模型的工程手段,在模型能力变强后反而变成枷锁。prompt
engineering、context engineering、decoding heuristics、harness
都曾经帮助弱模型工作,但当模型足够强时,人类硬写的框架可能限制模型自己管理环境的能力。
Active Context Manager:让模型自己管理上下文
第一组工作是从 context engineering 到 active context
manager。目标是让模型主动编辑自己的
context,而不是被动堆满上下文窗口后等待人类清理。模型在 context
增长到一定程度后,自己压缩、重排、删改,再继续推理,从而接近无限上下文。
从 context engineering 到模型主动管理 context 02:14:30
报告展示了一个有趣结果:模型没有在 agent 数据上训练,却能在
BrowseComp-Plus 一类深度研究 benchmark
上显著提升。这说明模型学到的是一种较通用的 context
管理能力,而不是一个固定 workflow。他还提到同期有个 Recursive
Language Model 的工作,用 480B 模型在 BrowseComp 上的效果只跟他们 8B
模型差不多,8B 版本更是只有三分之一。
Task-dependent memory 是反 AGI 的
王琰随后指出 task-dependent memory
的问题。若每个任务都要重新读完整上下文、重新建立 KV
cache,那么同一环境下的问题无法复用前一次探索得到的世界知识。以哈利波特为例,人不会为每个角色介绍重新读全书;模型也不应如此。
Pensive Paradigm 的问题:task-dependent memory 02:17:10
真正更接近 AGI 的 memory 应该是:模型先在环境中充分探索,形成可复用
world
knowledge;未来不同任务都能共享这份知识,而不是每个任务从零开始消耗
token。而且 KV cache 命中与不命中时的 API
账单差距巨大——这不仅仅是学术问题。
Reward-free self-evolution 与 World Knowledge Reward
第二组工作是 Spontaneous and Reward-Free
Self-Evolution。核心想法是:在下游任务出现之前,agent
先探索环境,生成 world knowledge。训练时仍然需要 reward 来判断 world
knowledge 是否有用,但推理时不需要
reward;推理阶段只是调用已经探索出的世界知识。
Spontaneous and Reward-Free Self-Evolution 02:20:30
Native self-evolution:环境探索并形成 world knowledge 02:22:20
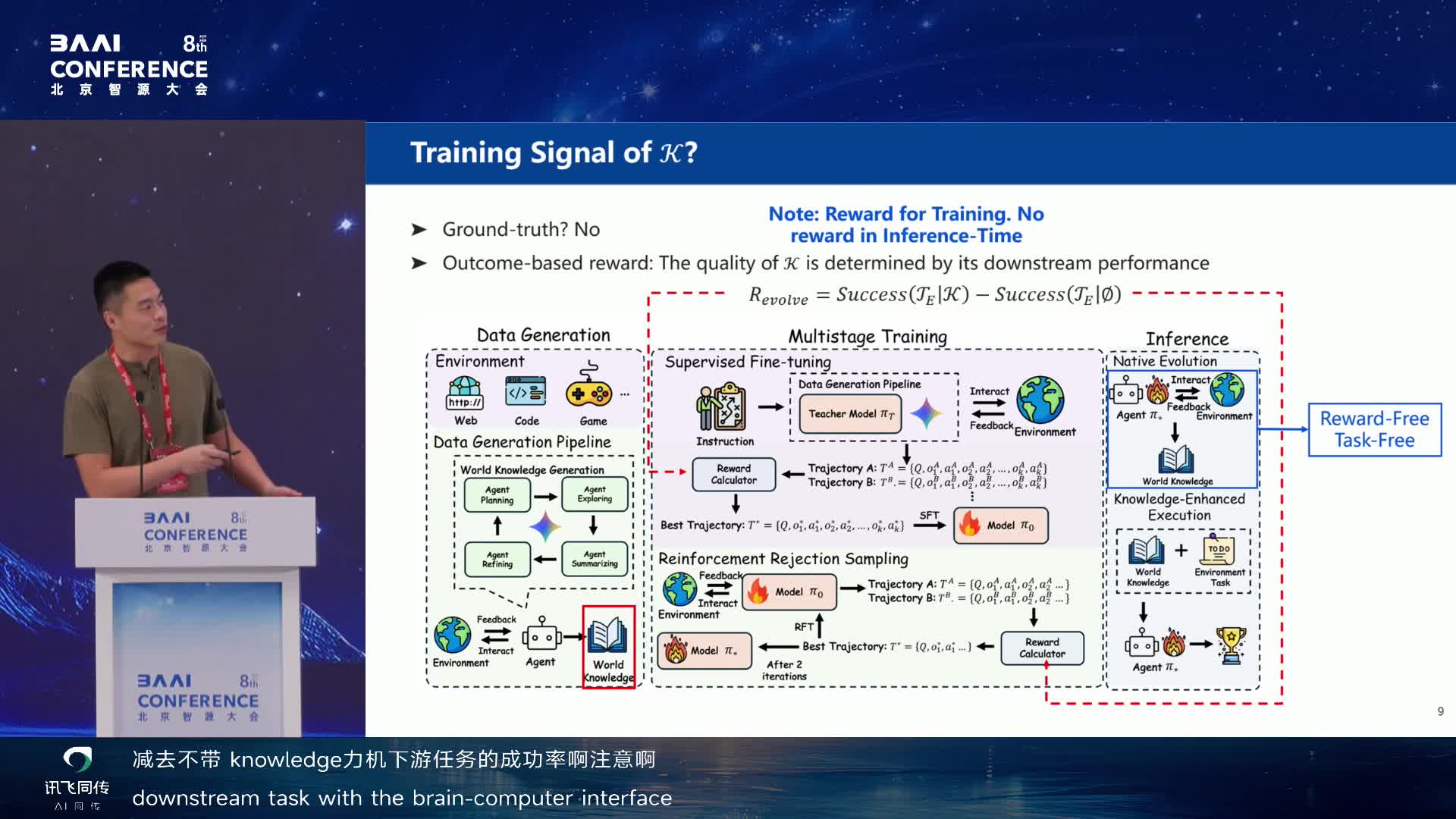
World Knowledge Reward 的定义可以用一句话理解:有 world knowledge
时完成任务的成功率,减去没有 world knowledge
时完成任务的成功率。这个差值衡量了知识本身对未来任务的贡献。
World Knowledge Reward:用下游任务增益定义训练信号 02:23:45
Native self-evolution 实验主结果 02:24:45
报告还强调 cross-model transfer:一个模型探索出来的 world knowledge
可以迁移给另一个模型。这使 knowledge scaling
有可能在某些知识密集任务中比 parameter scaling 更有效。比如千问三
14B 加上 world knowledge 的效果直接超过 Gemini 2.5 Flash,而 Gemini
2.5 Flash 加上世界知识又超过了 2.5 Pro。
Cross-Model World Knowledge Transfer 02:26:15
腾讯小程序长尾场景:自动生成 world knowledge 02:28:30
训练有 reward,推理 reward-free
王琰所说的 reward-free
不是训练完全无监督,而是推理阶段不依赖下游任务 reward。训练时用
World Knowledge Reward 学到哪些环境知识有用;推理时,agent
直接调用这些知识完成新任务。
FlashMemory 与长上下文的工程瓶颈
第三组工作是 FlashMemory-DeepSeek-V4 / Lookahead Sparse
Attention。报告先给出一个观察:很多长上下文 query
并不真正需要全窗口信息,90% 的 query 只需要最后 8K,甚至只需要最后
100 tokens 左右。长上下文的问题不是"没有窗口",而是"KV cache
成本太高且多数 token 在当前 query 中无用"。
上下文窗口瓶颈:90% 长上下文 query 只需最后少量 token 02:30:30
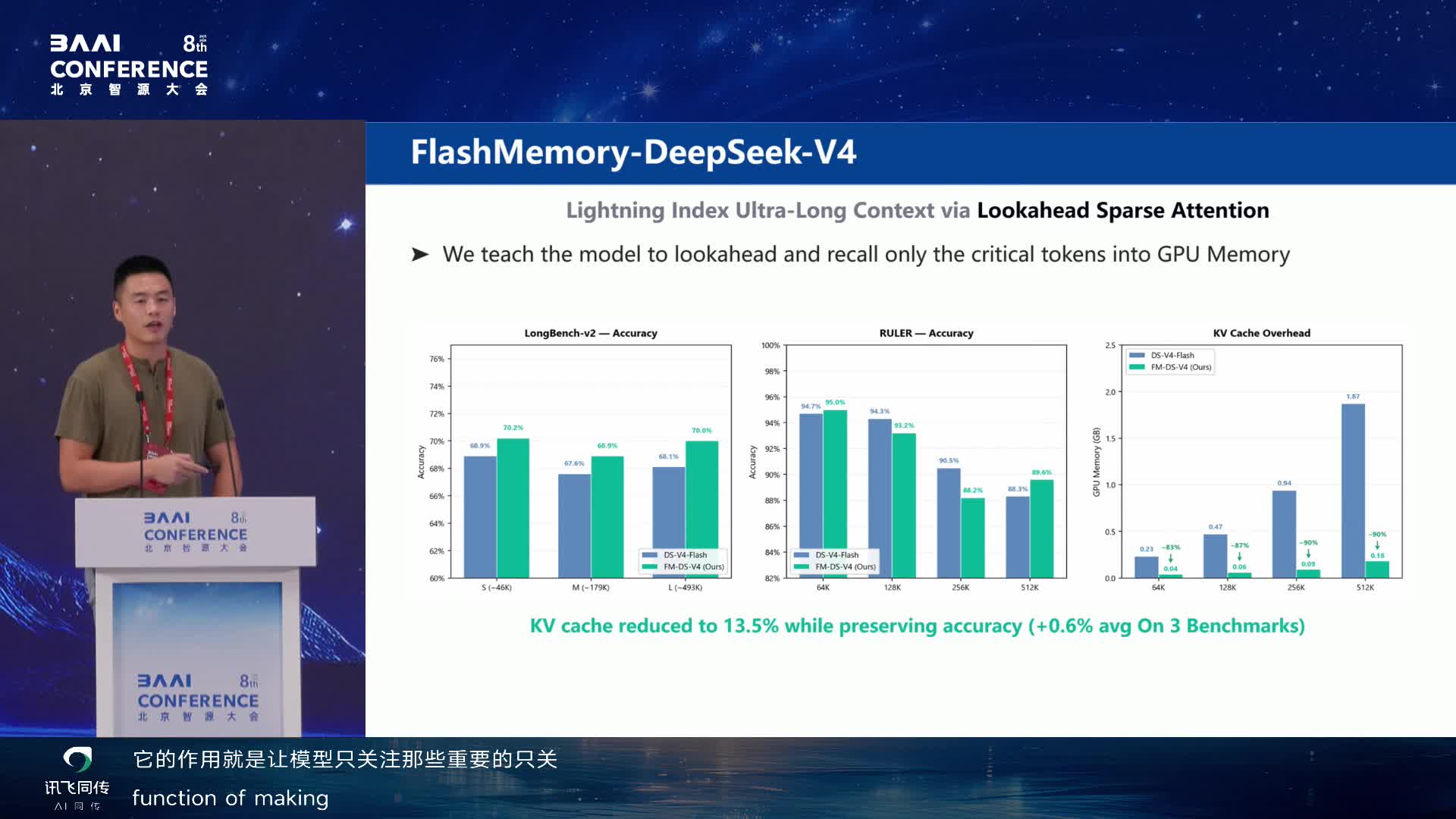
FlashMemory-DeepSeek-V4:只保留关键 token 的 GPU memory 02:31:35
FlashMemory 的工程思路是:全部 KV 放在 CPU 上,GPU 只保留
query-critical 的未来 KV cache。Lookahead Sparse Attention
预测未来若干步需要哪些 critical token,并提前搬到
GPU,从而在长上下文推理中降低 GPU memory 压力。在超过 128K
的场景下能把 KV cache 显存压力降低 90%。
Lookahead Sparse Attention:预测未来 critical KV cache 02:33:35
FlashMemory 的 limitations 02:34:20
局限也很明确:长度泛化仍有问题——训练在 128K
上,泛化到更长就失效,可能是因为位置编码没见过更长范围;KV overhead
不是常数级,始终保持在 10% 左右;dense information tasks(如
NQR)可能掉点。也就是说,FlashMemory
是一条工程上很有意义的路径,但不是长上下文问题的终点。
Q&A:它不能替代 agentic RL
Q&A 中有人问,这些 reward-free/self-engineering 思路是否能替代
agentic RL。王琰明确回答不能。reward、credit assignment、process
reward、人类标注或可验证信号仍然根本。self-engineering
更多是在降低人类手写 context/harness
的比例,让模型参与自身上下文、知识和架构管理。强化学习最根本的还是
reward,不是架构——从游戏 AI 的视角来看,只要 outcome reward
不要过程奖励基本就是在搞笑。
本章小结
王琰报告的主线是把 agency
从人类工程师手中逐步交还给模型:让模型自己管理
context,自己探索环境知识,自己把长上下文中的关键 token 留在
GPU,自己在未知任务前准备 world
knowledge。它与谷雨报告互补:谷雨强调什么才算真正学习,王琰强调模型如何获得更强自主工程能力。
拓展阅读
杨梦月:开放世界中的因果世界理解
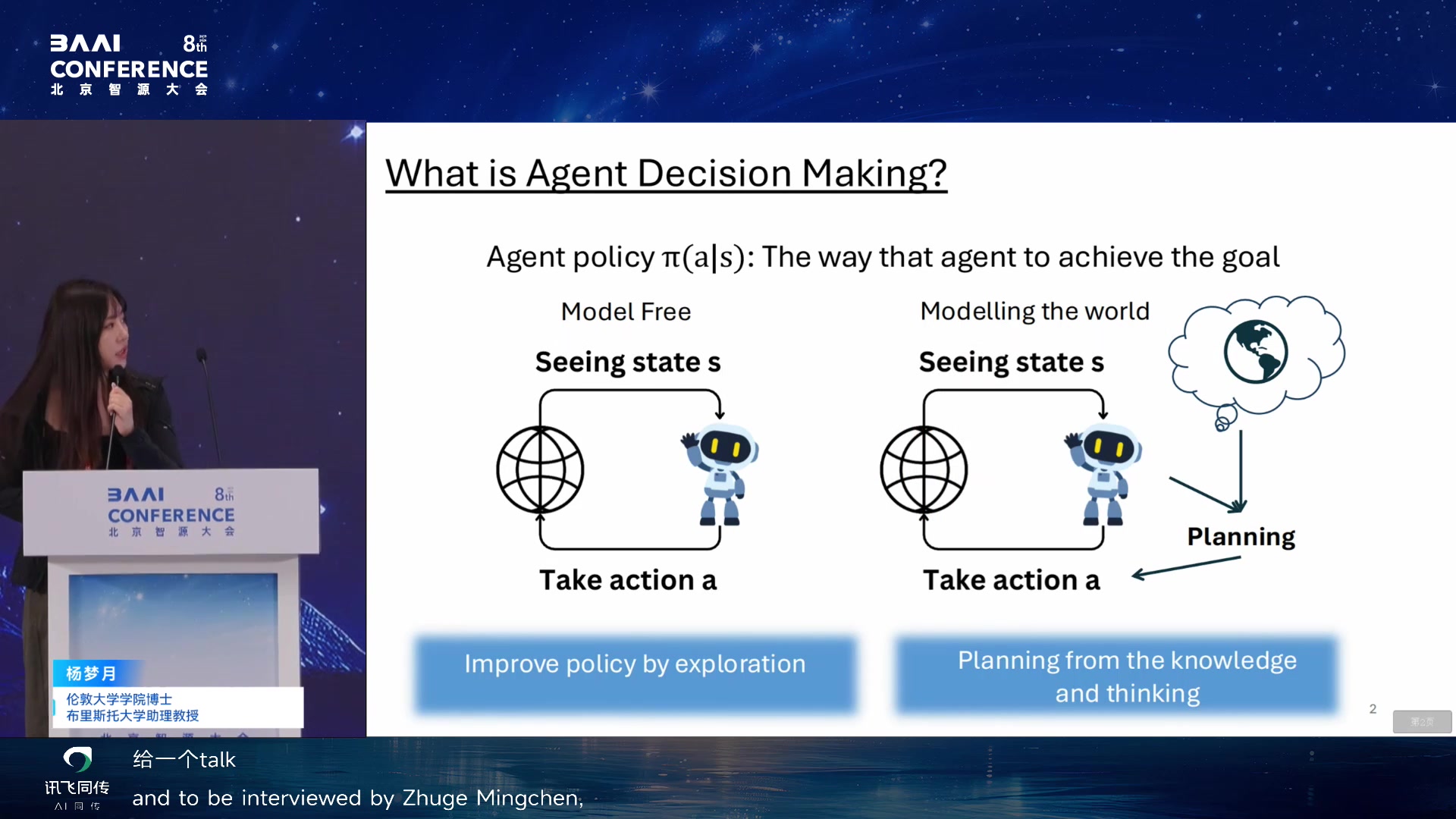
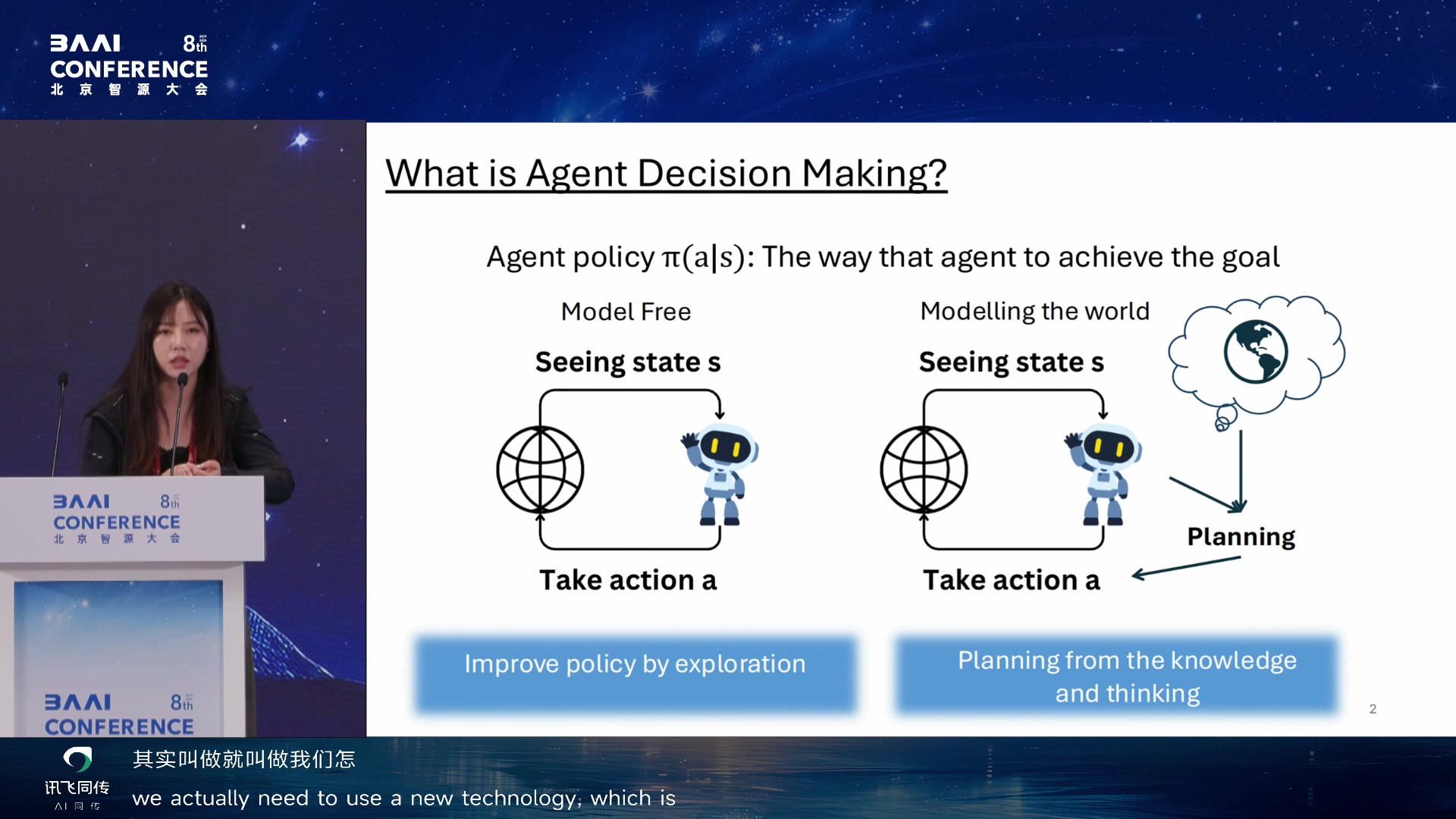
从 model-free 决策到 modelling the world
杨梦月的报告把自进化问题放到因果世界理解中。开头先区分 agent
decision making 的两条路线:model-free
方法直接从状态到动作;modelling world
则先理解世界,再基于世界模型计划行动。
Self-Improving Causality Seeking Agents in Open-Ended
World 02:40:05
Agent decision making:model-free 与 modelling world 02:40:35
她强调,开放世界中 modelling world
是必要的,因为数据无法覆盖所有可能情况,长程控制需要规划,探索也必须有目标,而不是随机试错。
Why modelling world is necessary 02:41:35
World model 不等于 understanding
一个关键区分是:modelling the world 不等于 understanding the
world。世界模型可能能预测下一帧、下一状态,却不一定理解因果关系。真正的理解需要知道哪些变量产生因果影响,哪些只是相关。
Modelling the World is Not Understanding the World 02:42:35
Pearl's Causal Hierarchy 02:48:05
报告用伞、天气、地面湿度的例子说明:看到人打开伞与地面变湿相关,并不意味着打开伞导致地面变湿。若
agent 错把相关当因果,就会做出错误干预。她引入了 Pearl
三层因果阶梯:第一层是 association(当前大部分世界模型和 agentic RL
学到的);第二层是 intervention(做操作看反馈);第三层是
counterfactual(已发生事件中的反事实想象)。
伞/天气/地面湿度例子:相关不等于因果 02:49:05
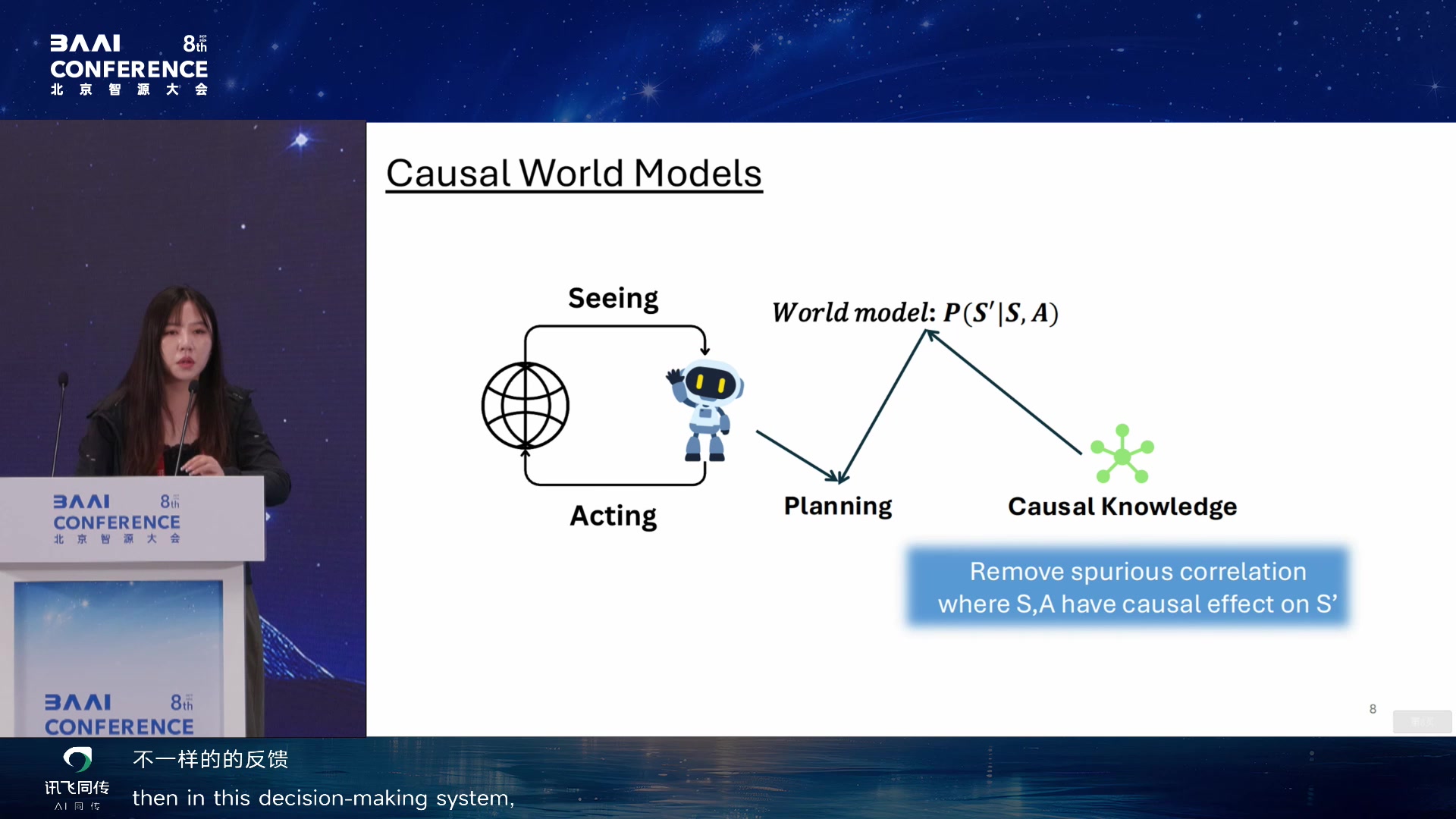
Causal World Models
Causal World Model
的目标是把感知、行动、规划和因果知识联系起来。因果知识能帮助 agent
去除虚假相关,理解行动会改变哪些变量,从而做更好的探索和决策。
Causal World Models 02:51:05
因果知识移除虚假相关并改善决策 02:51:35
Representation + Causal Structure 02:52:05
这与自进化的关系在于:agent 的探索不应只是收集更多
observation,而应针对当前 causal understanding
的边界进行干预,验证或修正因果结构。
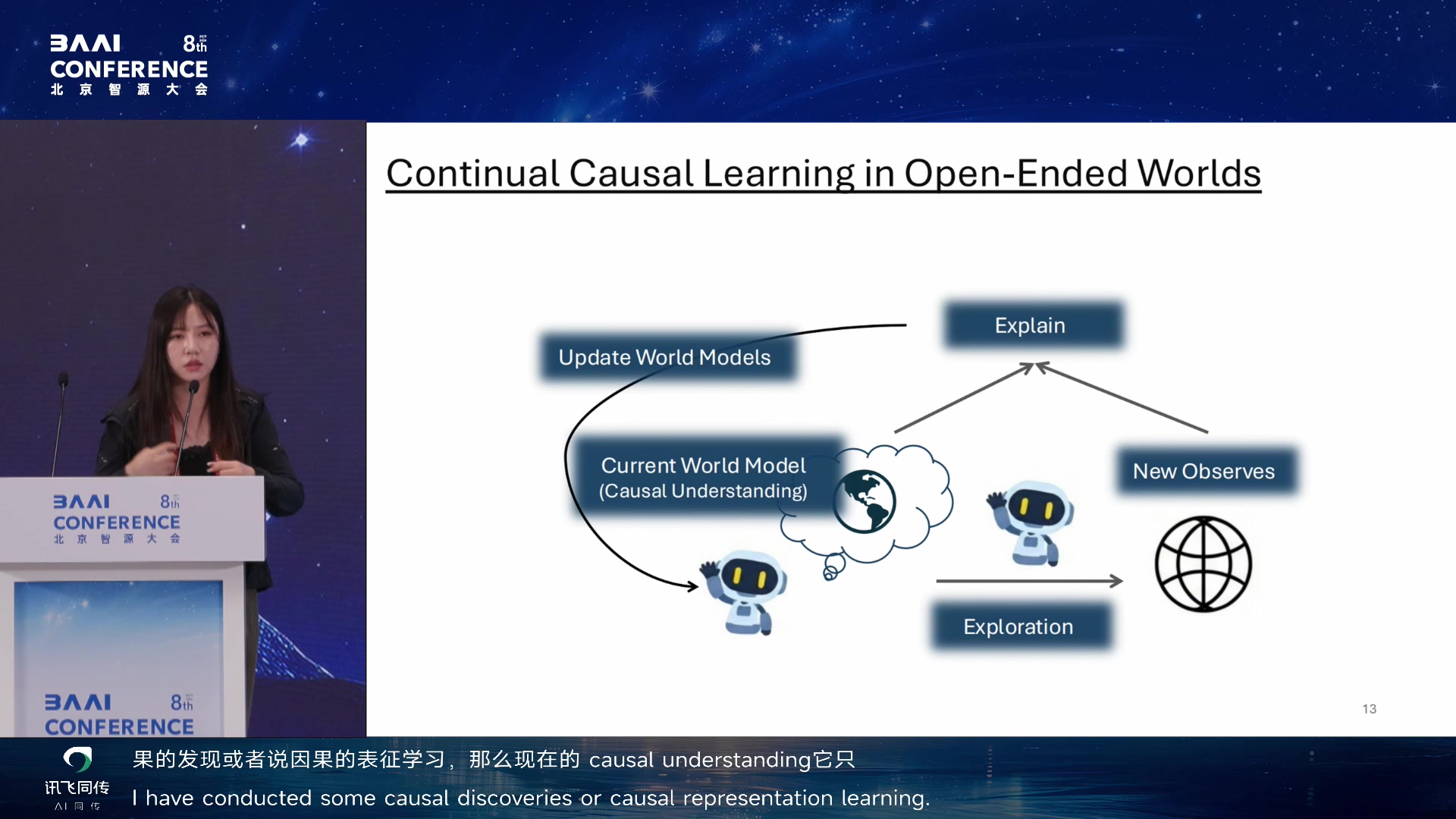
开放世界:causal drift 与 continual causal learning
开放世界带来 scaling challenge:状态和动作空间无限,多 agent
动态复杂,策略空间爆炸,观测窗口不断变化。因果关系也可能
drift:在不同条件下,同一变量之间的关系会改变。
开放世界 scaling challenge 02:53:05
Continual Causal Learning in Open-Ended Worlds 02:54:35
Causal drift in open worlds 02:56:05
Meta-Causal Graph 用来描述不同 context 下 causal mechanism
的变化。agent
不只学一个静态因果图,而是学习因果图如何随条件变化。她用牛顿定律和微观物理的类比:物理规则本身没变,但观察手段不同,看起来物理规则好像变了。所以
agent 需要学会主动向环境提问,突破自己的知识边界。
Meta-Causal Graph: condition-specific causal transitions 02:57:35
LLM Agents 的一般学习循环
报告后半把因果学习接到 LLM agents。她提出一个 general learning
loop:forward design 负责生成高质量数据和任务;evaluation abilities
判断当前 agent 的结果;backward update 把反馈转化为更好的
trajectory;memory/skill bank 保存沉淀下来的知识。
A new general learning loop for LLM agents 02:59:05
Three components for better self-improvement learning 03:01:05
Forward design 与 backward update 03:02:35
这与前面几位讲者形成呼应:谷雨讲 memory 的结构化,王琰讲 world
knowledge,林涛讲行动反馈,杨梦月把它们放进 causal understanding
的框架中。如果 loop 中每一步都能自我改进,就不只是
self-improvement,而是 recursive
self-improvement——不只是知识在积累,学习的能力本身也在进化。
Q&A:因果关系更新是否等于进化
Q&A 中有人问:如果每条因果关系都可以被更新,agent
是否真的进化了,还是指标上看起来进化?杨梦月回答,这正是
self-improvement 面临的最大问题。因果领域可以用 consistency
来判断:当前 causal understanding
设计出的探索,是否被环境反馈支持?如果反馈违背当前因果关系,就说明模型需要更新。
她强调,没有全知全能的 ground truth 告诉我们真实因果图。我们只能鼓励
agent
不断突破当前边界去探索,并观察它能否把新现象压缩成更一致、更简洁的
causal understanding。
本章小结
杨梦月的报告说明:开放世界自进化不能只依赖更多数据,也不能只依赖更长上下文。agent
必须知道哪些关系是因果,哪些只是相关;必须能针对因果边界设计探索;必须能在
causal drift 中持续更新世界理解。
拓展阅读
郑侠武:从 Benchmarking 到可验证自我改进反馈闭环
为什么抽象推理评测是 RSI 的前置条件
郑侠武的报告关注测量与验证。他用一个简单循环描述人类和机器能力提升:observe
experience,abstract rules,reason/apply rules,improve,再把新
observation 放回循环。若 RSI
要可靠发生,就必须知道系统到底有没有抽象出规律,而不是记住表象。
Measuring and Verifying Abstract Reasoning for Recursive
Self-Improvement 03:08:15
循环提升:经验 -> 规律 -> 应用 -> 改进 03:08:45
抽象与推理是循环中的关键两步 03:09:45
报告把人类文明循环和机器 RSI
循环并列:人类从消费者/观测者视角抽象规律,应用规律后反过来改造世界;机器
RSI
也需要经验、抽象、应用、改进,但失败点是:只能靠表象判断任务是否做对,很容易误以为学到了规则。
人类文明循环与机器 RSI 循环对照 03:10:45
怎样测到真实抽象推理
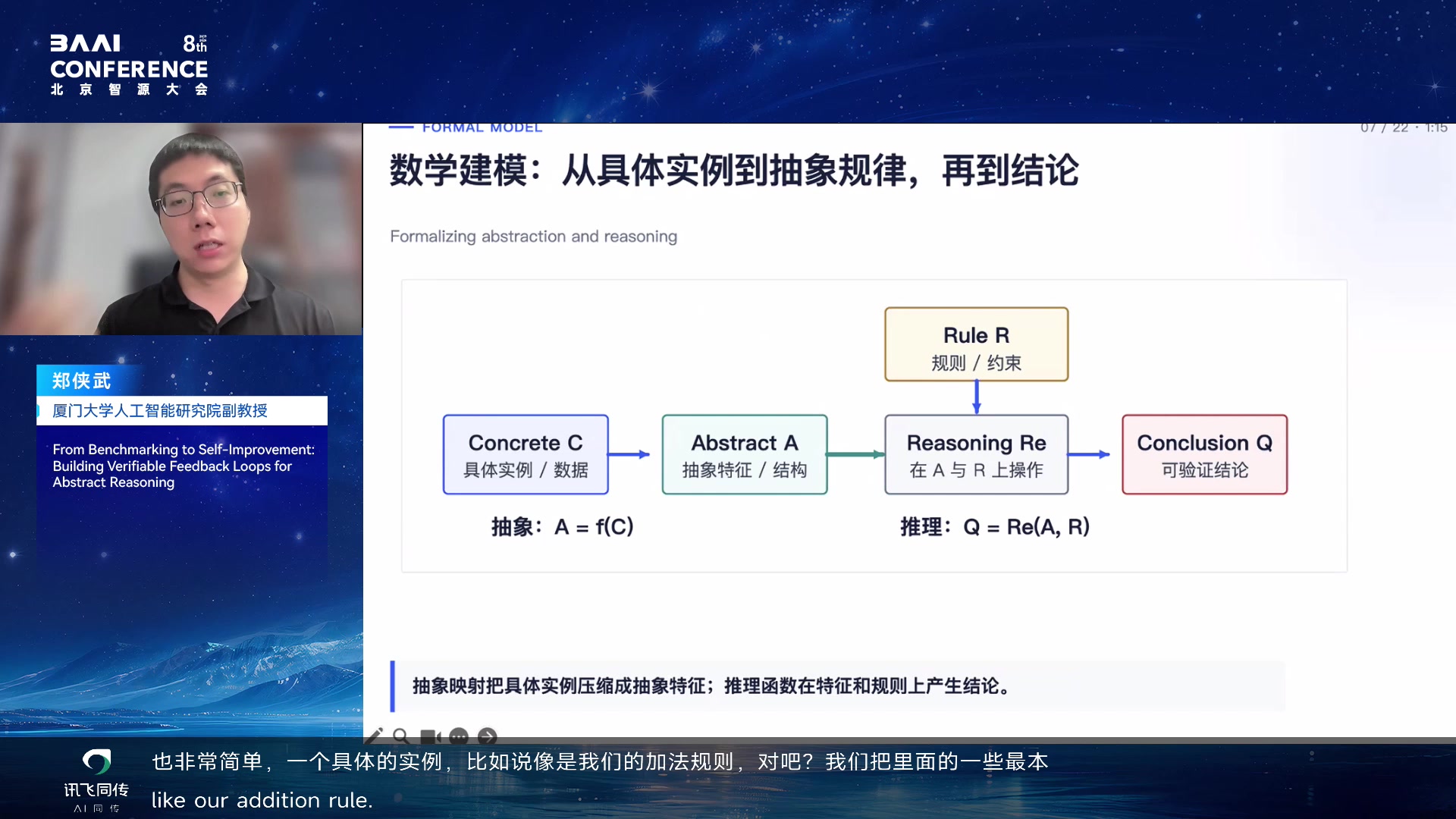
核心问题是:怎样区分模型记住了熟悉符号,还是学会了抽象规则?郑侠武引入理论建模:从具体实例
C 抽象出 A,用 rule R 在 A 上推理得到结论 Q,再映射回具体任务。
问题:怎样测到真实的抽象推理 03:12:15
数学建模:从具体实例到抽象规律再到结论 03:13:15
测试方法是给表象加扰动,例如把符号、颜色、对象替换掉,但底层规则不变。如果模型仍能命中规律,说明更可能学到了抽象结构;如果性能崩掉,说明它依赖表象。
给表象加扰动,看模型是否仍能命中规律 03:13:45
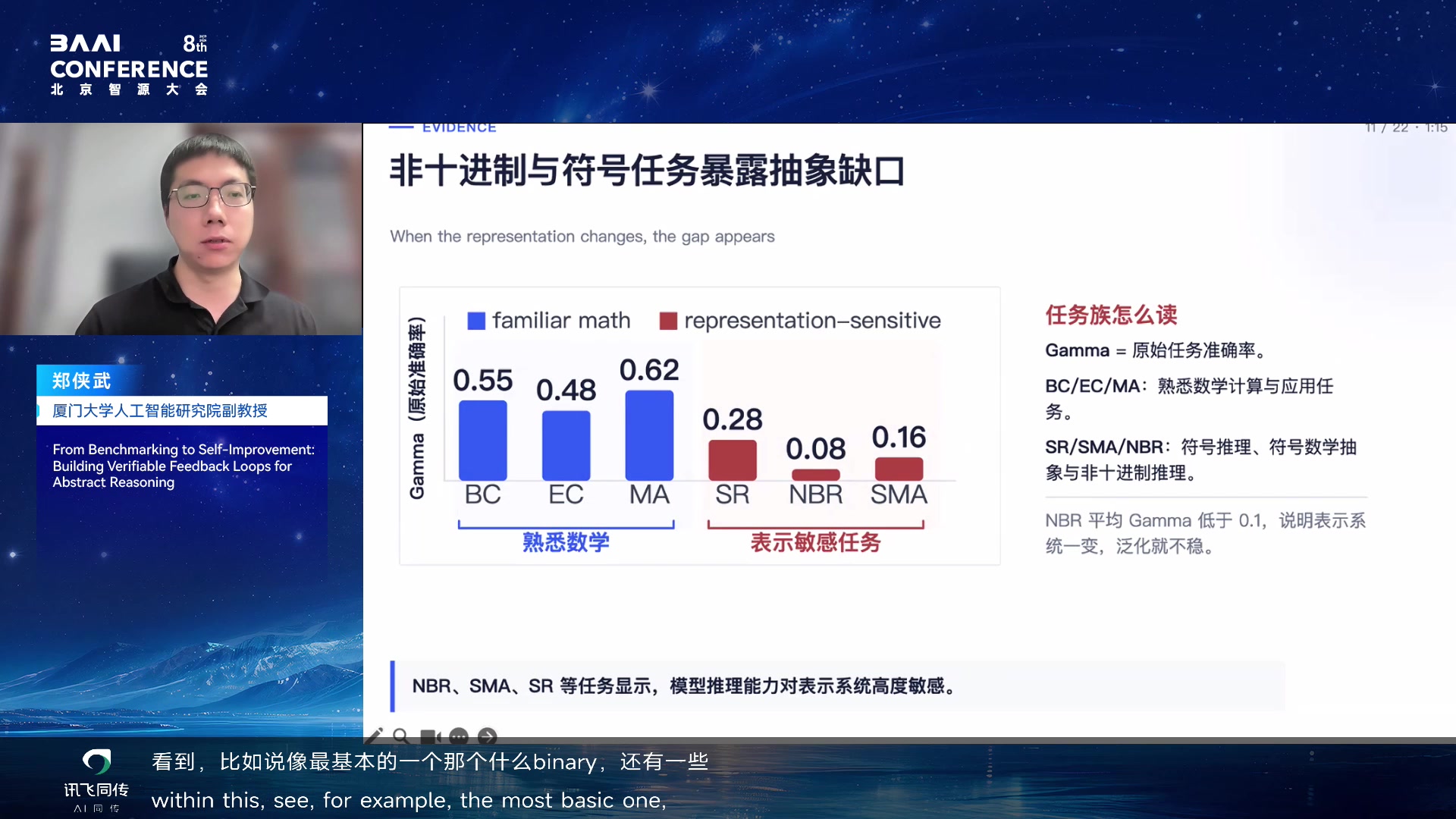
Gamma 与 Delta:把能力和表征依赖分开
报告提出两个分数:Gamma 更像能力分数,衡量 familiar-domain
performance;Delta 更像依赖分数,衡量模型对 representation
的敏感程度。理想模型应该既有高 Gamma,也有低
Delta,即能力强且不依赖具体表象。
Gamma 与 Delta 两个分数 03:15:15
模型常记住符号而不是学习规则 03:16:15
从静态 benchmark 到 A2RBench
郑侠武认为静态 benchmark 不够支撑
RSI。若系统能自我改进,固定测试集很快被刷掉,甚至被 benchmark
hacking。A2RBench
的思路是自动生成、扩展、评估、分析抽象推理任务,让任务本身可验证,并能随模型能力升级。
第一篇工作的 RSI 角色:能力诊断器 03:18:15
为什么静态 benchmark 不够支撑 RSI 03:19:15
A2RBench 自动生成、扩展、评估、分析管线 03:19:45
报告展示规则族如何从 1D sequence 扩展到 2D grid、3D blocks,并用
forward/inverse 机制验证任务成立:forward 能从规则生成样本,inverse
能反推规则是否一致。这样就不用调 LLM
judge——用数学可保证的可逆性就能验证任务有正确答案。
规则族的维度扩展:1D/2D/3D sequence 03:20:15
Forward / inverse 如何验证任务成立 03:21:15
实验发现:LLM 与人类仍有差距
报告中一个显著结果是:自动生成挑战显著难于当前 top LLM。模型最高约
39.8%,人类约
68.5%。这说明即便规则不复杂,只要表象经过转换,模型仍很难稳定发现底层规律。
自动生成挑战仍显著难于当前 LLM 03:22:45
另一个现象是 augmentation
paradox:增加或扩展数据不一定提升抽象能力。模型可能为了保证任务正确性而生成更简单的规则,尤其在
3D 任务上显示出结构理解能力不足——不是因为不能做 3D 的题,而是在生成
3D 任务时没有那么大的想象空间。
Augmentation paradox:扩展数据并不必然提升抽象能力 03:23:15
RSI 的抽象推理反馈闭环
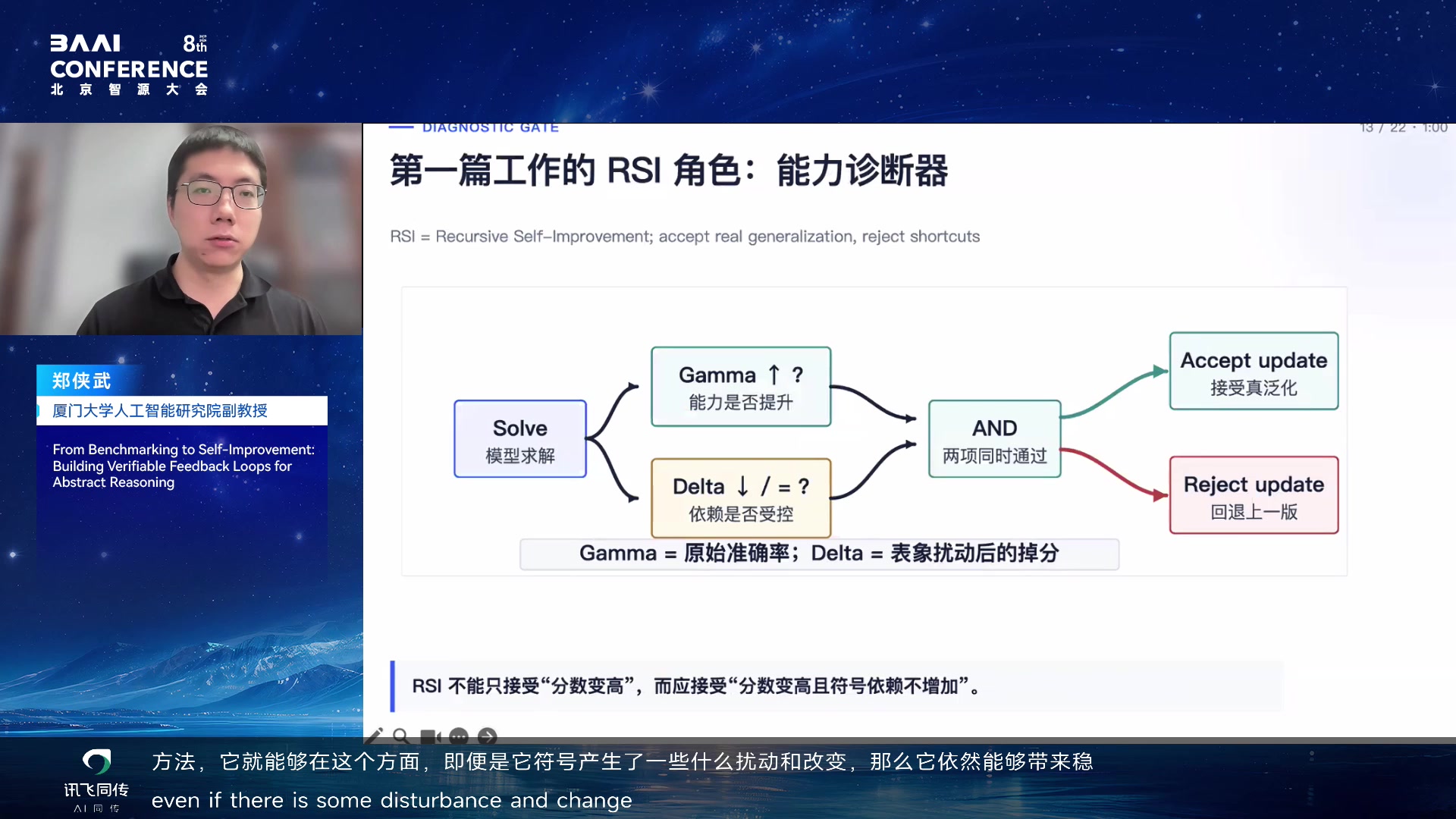
最后,郑侠武把 A2RBench 接到 RSI:Generate
challenge,Verify,Solve,Diagnose,Improve。下一轮 verified
feedback 再返回 challenge generation。这样,benchmark
不只是考试,而是自我改进系统中的反馈发生器。
RSI 的抽象推理反馈闭环 03:24:45
可靠抽象推理评测是 RSI 前置条件 03:26:45
本章小结
郑侠武的报告给整场论坛补上"怎么知道真的变强了"。没有可验证评测,self-improvement
很容易变成
self-delusion。抽象推理评测的核心不是看最终分数,而是判断模型是否从表象中抽出可迁移规则,并在扰动和新任务上保持一致。
拓展阅读
圆桌:觉醒与进化,AI 如何自我迭代
第一问:什么是 AI 自进化
圆桌由主持人先给出背景:今天很多 agent
已经会反思、调用工具、优化指令,但从短期调整到长期自主诊断、持续优化、系统级升级之间仍有很长距离。第一问是请嘉宾给
AI 自进化下定义。
圆桌主题:觉醒与进化,AI 如何自我迭代 03:29:50
圆桌全景与嘉宾构成 03:31:00
林涛从外脑和内脑区分:自进化可以是外脑进化,也可以是内脑进化。关键是
AI 能否认识自己的局限,并把外部
skill、harness、工具中的能力逐步内化到模型本体。
林涛:外脑进化、内脑进化与能力内化 03:32:20
谷雨延续自己报告的框架:self-improving 最重要是 proactiveness 与
learning。what 层面是 metacognition,知道自己缺什么、该学什么;how
层面是具体学习算法。
谷雨:proactiveness 与 learning 03:33:20
王琰给出一个更经验主义的判断:今天很多"自进化"仍然是 human-driven
evolution,但如果比经典 SFT/RL
更少依赖人类设计,也可以算自进化的一部分。
王琰:今天很多自进化仍是 human-driven 03:34:30
杨梦月强调 open-endedness:agent
不只是能力进化,还要进化"发现自身知识边界并提出问题"的能力。也就是进化能力本身的进化。
杨梦月:知识边界、自我提问与自我诊断 03:36:20
哪一层最先成熟:基模、harness 还是 memory
第二个问题是:站在今天,最有价值、最可能成熟的自我改进对象是哪一层?王琰认为基模领域已经在
AI 迭代 AI,模型迭代速度明显加快;即使不改参数,只改
prompt、harness、context,也能产生巨大跃迁——EM 的 prompt
能产生的变化"很恐怖"。
林涛认为对大多数人来说,harness 最容易起步。更好的 harness
发挥当前模型上限;大量用户产生的 harness 和 trajectory
又可能回流到更强基模训练中,形成外脑到内脑的循环。
谷雨用统一 memory
视角回答:harness、skills、tools、模型权重都是长期记忆的不同形态。harness
更像 meta-level memory,tools/skills 更像 workflow/process
knowledge,模型权重更像 system 1
intuition。学术上难以只选一层;创业上可能先从 harness
起步,因为不必和 Frontier Lab 直接竞争基模。
杨梦月从因果和规则理解角度倾向于 memory
层。但她也提醒,基模能力不断增强可能吞噬一部分 harness
的价值,因此要动态看两条路线的进展。
什么时候进化:推理时、事后,还是长期 checkpoint
谷雨强调"learning during inference + long-term
memory"。每一次解决问题都是学习机会,不应浪费。传统深度强化学习主要更新模型参数,难以做到在线学习;未来可能需要非参数更新,使每个
case 都能立即改变 memory。
王琰顺着这个问题谈到 TTT、Doc2LoRA、delta rule
等工作。他关心的是模型能否在 next-token prediction 过程中学会每个
token 对更新梯度的影响,自己决定 data
rule,而不是由人类高维生物替它写更新规则。
林涛从训练阶段补充:harness 可以先影响
post-training,得到更强模型后再反馈到
pre-training、mid-training,形成多尺度闭环。因此"什么时候进化"的答案是时时刻刻,只是尺度不同、更新对象不同。
杨梦月用自己的 forward/backward/memory loop 回答:推理过程是 forward
design,反馈后是 backward update,沉淀下来的 causal
knowledge、rule-based physical knowledge、skills 又进入 memory/skill
层。
Benchmark 是否也要自进化
主持人随后问:当 agent 能力越来越强,静态 benchmark
会被刷掉,评测系统是否也需要动态生成任务?杨梦月认为开放世界需要增长式
benchmark 或增长式 world model,让环境可观察面逐步展开,像
curriculum learning 一样匹配 agent 能力。
王琰更怀疑:open-ended generation 往往没有
benchmark,最终可能回到人评。静态 benchmark 肯定不够,动态 benchmark
能不能评也不确定。
谷雨认为 benchmark 代表目标,因此目标仍应由人提供。但 self-improving
的评估不应只看最终
accuracy,而要看趋势曲线:横轴是完成任务数量,纵轴是
performance,理想系统应随经验持续上升。也就是说,评估对象从"掌握了多少
skill"转向"如何掌握 skill"——how to learn 本身才是 intelligence
最核心的东西。
林涛补充,真正的 intelligence
可以看成能力单位时间增长速度。未来可能需要半自动化 benchmark
发现,再把发现出的 benchmark 用于 post-training。
安全、可控与可验证
当讨论转向安全时,王琰给出很尖锐的判断:AI
失控并不遥远,安全不只取决于技术,也取决于人类是否能克制资本和竞争压力。他甚至直言:看诸葛他们公司叫
RSI 融了很多钱,要是叫 AI 安全能不能融现在 1% 的融资?不可能的。
林涛则给出技术侧回答:半自动化 benchmark
需要有人参与,为系统提供人类定义的约束。至少在一定程度上,可以给系统一些约束,使它不会突破人类想定义的标准。
杨梦月从 trustworthy AI 角度强调
transparency、explanation、causality。要控制系统,首先要知道它为什么做某个决策。传统
causal discovery/inference 方法未必适配大模型时代,需要回到 Pearl
因果阶梯这类基本定义,重新思考约束形式。
谷雨把短期可控性落到两个词:reliability 与
verifiability。reliability
是同一件事这次做对,下次也要做对;verifiability
是模型做错时要知道自己错了。对 agent
落地来说,这两个指标比宏大安全叙事更直接。
AI 与人的协同进化
圆桌后半讨论 AI 进化是否会倒逼人进化。林涛说自己的工作流已大量由 AI
替代,效率提升让他有时间想更多问题;但人如何更高效进化以促进 AI
进化,仍需探索。
杨梦月从教育经验出发:基础扎实的人能驾驭 AI
工具,产出更高质量工作;基础不扎实的人容易被 AI 误导。AI
会让人形成分层,越有基础越能到达顶部,越依赖工具越可能只是镀金。
王琰进一步指出,AI 可能加剧贫富差距和能力差距。孩子或学生如果过早用
AI 完成作业,会 reward hack 掉本应建立基础能力的过程。更 senior
的人有了 AI 助手后,可能减少 junior 的锻炼机会,这会让新人更难成长。
谷雨用"慢就是快"总结:vibe coding
可能让项目初期推进很快,但如果理解没跟上,repo
会越来越失控,后期反而需要更多时间整理。AI
作为工具会和人共同演进;但如果 AI
不只是工具,而成为平等甚至凌驾于人的主体,未来就不一定是共同进步。
历史定位与未来五到十年
最后,圆桌讨论 AI 自进化是现有 agent
技术的自然延伸,还是新阶段。林涛认为这是自然走向,agent
成熟让这件事更简单。王琰更直接:它就是下一阶段。未来每个人可能有独有参数区域,例如个人
LoRA;inference 与 training infra 支持实时 LoRA merge/unmerge
后,个人任务中的反馈就可能直接沉淀到个人模型中。
谷雨认为这不是互斥问题,而是量变引起质变。关键维度是任务长程程度:从单轮对话到多轮推理、deep
research、月/年级任务,再到 lifelong
task。任务越长程,系统越需要在过程中发现不足、节省经验、持续学习。
杨梦月则认为 self-improvement 是通往 AGI
的重要技术手段,但不是全部。AGI
还需要快速适应新环境、开放世界中的精细动作、continual learning
和综合解决方案。
圆桌尾声:未来五到十年自进化 AI 的社会影响讨论 04:23:30
未来五到十年的社会影响讨论很开放:林涛认为自进化 AI
可能改变一切,从出生到养老形成个人数字人;谷雨希望 AI
不是造成大面积失业,而是把五天工作制变成三天、八小时变成四小时;杨梦月担心
AI
过快压缩人的价值感;王琰补充说,技术进步应该创造新空间,而不是只盯着最容易替代人的领域。
本章小结
圆桌把整场报告的技术线索变成判断框架:自进化包括外脑与内脑、what 与
how、基模与 harness、推理时学习与长期 memory、动态 benchmark
与人类目标、安全与可验证、人和 AI 的共同演进。它也提醒我们,AI
自进化不是纯技术乐观主义;它会改变组织、教育、劳动和社会分配。
全局综合:什么样的系统才接近真正自进化
七个必要条件
把整场论坛连起来,可以得到一个比较严格的判别框架。一个接近真正自进化的
AI 系统,至少需要七个条件:
条件
含义
可迭代计算底座
量化、小模型、端侧部署、长上下文缓存等,使系统能 afford
大量尝试。
可扩展经验生成
agent 能在环境中大量 rollout,经验可被收集、管理、复用。
结构化 memory
经验不是简单日志,而是进入可抽象、可更新、可执行的长期状态。
自主目标识别
agent 能知道自己缺什么、何时需要学、如何提出问题。
世界理解与因果结构
系统不只预测相关性,还能用因果关系指导探索和干预。
可验证反馈闭环
改进必须由可靠
benchmark、动态评测、验证器或人类目标约束支撑。
安全与社会约束
系统不能只追求能力上升,还要可靠、可验证、可控,并考虑对人的影响。
各章节之间的关系
刘泽春解决"跑不跑得起"的问题;张少坤解决"经验如何规模化产生"的问题;谷雨解决"经验是否真的变成学习"的问题;林涛解决"多模态理解、想象、行动如何闭环"的问题;王琰解决"模型如何从人类
context engineering
中解放出来"的问题;杨梦月解决"开放世界中世界理解如何具有因果性"的问题;郑侠武解决"如何验证抽象推理改进是真的"的问题;圆桌则把这些问题推向人类目标、安全、教育和社会结构。
最容易混淆的几个点
误区二:reward-free 等于没有 reward
不对。王琰报告中的 reward-free 指推理阶段不依赖下游
reward。训练阶段仍然用 World Knowledge Reward
判断环境知识是否有价值。
误区三:动态 benchmark 可以自动解决安全
不对。benchmark
是目标和约束的表达,目标仍然需要人类给出。动态评测能减少静态刷榜,但不能替代人类价值约束、可靠性和可验证性。
误区四:长上下文就是长期记忆
不对。长上下文只是把更多 token
放进窗口。长期记忆要求信息能跨任务复用、被结构化更新,并影响未来推理。KV
cache、world knowledge、个人 LoRA、harness
都可能是不同层次的长期记忆。
术语表
术语
解释
Recursive Self-Improvement, RSI
系统递归改进自身能力的过程。严格形式需要自引用、自修改和可证明改进;工程形式常通过候选生成、评估和迭代实现。
Harness
包裹模型的外部结构,包括
prompt、tools、workflow、subagents、memory、policies 等。
Memory
本讲义中广义使用:所有会影响未来 inference
的长期状态,包括文本、向量库、工具、harness、模型权重、个人
LoRA、world knowledge 等。
World Knowledge
agent
在环境探索中沉淀的可复用知识,可在未来不同任务中提升成功率。
World Knowledge Reward
有 world knowledge 与无 world knowledge
的任务成功差,用于衡量知识对任务的边际贡献。
Causal World Model
不只预测世界状态,还显式建模变量之间因果关系的世界模型。
Rollout-as-a-Service
把 agentic RL 的 rollout 过程封装成可复用服务,解耦
trainer 与 agent harness。
Lookahead Sparse Attention
预测未来若干 decoding step 需要的 critical KV
cache,并提前搬运到 GPU 的长上下文推理方法。
Gamma / Delta
郑侠武报告中的抽象推理诊断指标,分别用于刻画能力与对表象的依赖程度。
A2RBench
自动生成可形式验证抽象推理 benchmark
的框架,用于从静态考试推进到动态反馈。
外部资料索引
以下资料只作为外部补充,用于校正专名、提供延伸阅读和帮助读者继续深挖。现场内容仍以视频和
ASR 为主。
逐段内容复原层:v2 细节补强
本节不是官方逐字稿
本节来自分章 ASR 与视频画面校验。它比 v1
保留了更多细节,但仍可能存在烧录字幕/ASR
引入的人名、论文名、英文术语误差;关键论文名、讲者姓名和方法名应优先参考前文已校正的章节标题、关键帧说明和外部资料索引。
林涛:统一多模态模型中的想象、行动与反馈闭环
01|01:46:55--01:49:55
林涛的开场回到两三年前的初衷:一开始想用生成模型生成更多数据来训练更好的表征模型,再用表征模型训练更好的生成模型,形成闭环——但一直不
work。这促使他思考:如果要实现真正好的自进化,到底应该怎么做?答案是构建一个闭环:统一的
backbone(他叫 World-Action
Model),可以理解世界、基于理解去想象、在想象基础上行动、从环境得到反馈并用反馈学习。
他展示了团队训练的统一多模态模型的能力:VQA、图像编辑、图像生成、简单的
tool use、interleaved
文本图像生成。但关键问题是:这些能力能不能真正帮助 backbone
提升?答案是 Generation as Imagination,Acting as
Feedback——都可以作为提升模型的信号。但即便是当前 SOTA
模型,也只是在看、想象、行动三个方面中一两个方面比较强,三个都做好、放回学习环就更难了。
02|01:49:55--01:52:58
林涛展示了一个不好的生成例子:小男孩的雨伞生成不符合物理和空间规律,镜子对应关系也有问题。这些问题说明了
generation 不等于好的
imagination。如果模型能做好生成,确实可以把生成作为对未来状态的预测,作为
imagined rollout 去选择更好的 next step 或
action——但想象的未来和真实世界存在
mismatch,所以需要从环境得到反馈来 revise 模型。
他提出了 World-Action Model
的概念:它可以是数字智能体也可以是物理智能体,但背后都应该有共享大脑(shared
backbone),有 world 可以理解、想象、基于 shared backbone
思考未来状态、执行,并从环境得到 feedback。关于 backbone
选择,community 有不同方案:MU3.5 是 AR Native 代表,Bagel 是 AR
加 Diffusion,还有些 Diffusion Native 的。
03|01:52:58--01:55:58
林涛从 self-improving 角度思考更好的 backbone 选择——希望实现
bidirectional attention 和 iterative refinement。他们提出了 LADA
2.0 UNI:把语言模态和视觉模态映射到同一个 Token Space,用统一的
Mask Training Objective
实现任意模态到任意模态的转换。比如从语言通过 Diffusion
变成图片,或者从语言加图片变成图片,或者 interleaved 的情况。
在 unified token space 和 mask objective 下,可以实现
understanding、generation、editing 和 interleaving,并在简单
benchmark 上有不错表现。更重要的是可以初步实现 interleaved
generation 和 interleaved
reasoning:生成后反思、重新思考下一步怎么生成更好的图片。
04|01:55:58--01:58:59
回到闭环核心问题:imagination 必须便宜。如果生成一张图片需要 10
分钟,interleaved generation 和并行 rollout 都毫无意义。他们的
backbone 已经初步支持 cheap imagination:可以通过 Continuous
Diffusion Decoder 实现快速从 random noise 到 good picture
的转换,把原来需要多步的 diffusion 压到八步。
关于如何做到 cheap imagination,他串起了
UCGM、RCGM、TwinFlow、DuMo 系列工作。UCGM 为不同流派的
diffusion/flow matching/consistent model 做了统一理论框架,通过
Lambda 参数调控 multi-step 和 full-step generation。RCGM 解决了
20B 模型上稳定训练的问题——recursive prediction 机制。TwinFlow
真正在 20B 模型上高效落地并实现 SOTA:去除了 teacher
model、descriptive model 等依赖,一步生成代替原来 100 步。DuMo
则更简单:把 full-step 和 multi-step generation decouple 到两个
head。
05|01:58:59--02:02:01
继续深入 UCGM 统一框架:长久以来 Diffusion、Flow
Matching、Consistent Model 分别代表 multi-step 和 few-step
generation,范式割裂,背后有不同理论推导和采样器。UCGM 通过 Lambda
参数把两者统一到一套理论框架下。RCGM
进一步解决少步推理模型的核心瓶颈——20B 模型上难以稳定训练学到 XT 到
X0 的转换,通过多轮 trajectory 重组实现 recursive one-step
generation。
TwinFlow 是试图在 20B 模型上真正落地 SOTA 算法:去除
teacher/descriptive/further model 依赖,一步生成就能达到原来 100
步的质量。DuMo 把 full-step 和 multi-step decouple 到两个
head:低位空间做 multi-step,高位空间做 one-step。
06|02:02:01--02:05:01
有了 cheap imagination 后,生成模型可以变成轻量的 world model
interface:不再是 offline augmentation
或延迟很大的生成,而是可以并行做大量 rollout,从中找到想要的
trajectory 或 future state,帮助做更好的 understanding 或
action。为什么 action 要进入 loop?因为 self-consistency 不等于
correctness——需要模型与环境真实交互,从环境得到反馈,实现 grounded
action 和 grounded feedback。
他分享了实验室在 environment tuning 方面的工作:agent
和环境应该协同进化,环境一开始可能不适合 agent
学习,需要先改造;agent 学得足够好了,又要 revise
环境让它继续支持学习。以及 boundary-aware data 的想法:从环境
rollout
出来的数据有好有坏,需要自适应学习机制找到最适合模型训练的数据,让模型以最高速度学习。
07|02:05:01--02:08:06
林涛总结几个方面的工作:从 backbone understanding 角度、cheap
imagination 角度、环境交互 action
角度、未来从环境学习形成自反馈角度。self-improvement loop
确实很困难,需要从模型、harness、architecture、整个训练方式多角度思考,构建更好的生态让模型变成适应自进化的模型,在适合自进化的环境中自进化。
他展示了 Four Open Interfaces:understanding 到
imagination、imagination 到 action、action 到 feedback、feedback
回到 backbone——四个断开点需要串在一起,在 good backbone
基础上实现自进化。
08|02:08:06--02:11:06
Q&A 第一个问题:self-improvement learning 与 active learning
的关键区别。林涛回答:最重要的概念是模型要有
self-awareness,知道自己的 knowledge
boundary,并构建适合自己进化的环境。传统 active learning
更多是选择样本,self-improvement
要求系统认识自身局限并沿目标改变环境和训练方式。
第二个问题:data scaling、environment scaling、model scaling
之间有没有协同进化规律。林涛认为这是一个很好的 scaling law
问题,包括 environment scaling、data
scaling,以及它们之间怎么串在一起,很值得探索。
王琰:从 Context Engineering 到 Self-Engineering Architecture
01|02:11:22--02:14:22
王琰从实际问题出发:模型在数学、代码等场景已经很强,Claude Code
让他都不想招实习生了。但通用性上还是不如人——agent
会陷入死循环,context 满了不知道自己清,decoding 出问题不知道调
template。这些限制是因为早期模型能力不够时,人类做了很多帮助模型的事(prompt
engineering、context
engineering、harness),现在模型变强了,这些反而变成枷锁。
他的研究方向就是提升模型的通用性(传说中 XDR2025
的"通")。第一组工作:让模型从被动接受 context engineering
变成主动的 self-context manager。
02|02:14:22--02:17:22
Active Context Manager 的核心:让模型学会主动编辑自己的
context——当 context
到一定程度后,模型自己压缩、重排、删改,再用这种方式实现几乎无限的上下文。context
manager 这个说法是他跟 NUS 张贵斌同学讨论出来的。
实验亮点:从来没有在 agent 数据上训练过,但在 BrowseComp
这个非常难的数据集上取得很大提升。更有意思的是同期有个 Recursive
Language Model 的工作——号称下一代语言模型范式——他们 480B 模型在
BrowseComp 上的效果只跟王琰这边 8B 模型差不多,8B
版本更是只有三分之一。这说明模型自己学会的能力跟人类操控的差别很大。
03|02:17:22--02:20:22
但 task-dependent memory
有问题:做哈利波特任务时先给哈利波特做介绍,马上换成给邓布利多做介绍,就不能复用之前的
KV cache,必须重新计算一次。在 OpenAI 出来后最贵的就是
token,这样做很不现实,也跟人类行为不一致——人不会写每个角色介绍都重新看一遍全书。这是反
AGI 的。
他自我进化了思考:更需要的记忆方式是让模型先充分探索环境(比如花三天三夜看完哈利波特全部细节),然后不管来了什么问题都能轻松搞定——KV
cache 在未来任务中可复用。他接着批判了两个工作:DeepMind 许忠文的
Cogito(强依赖游戏环境 reward),和于文豪的
RZERO(强假设下游任务都是数学),认为它们本质上都是 human-driven
evolution。
04|02:20:22--02:23:23
真正的自进化应该是在不知道下一个任务是什么、也没有 reward
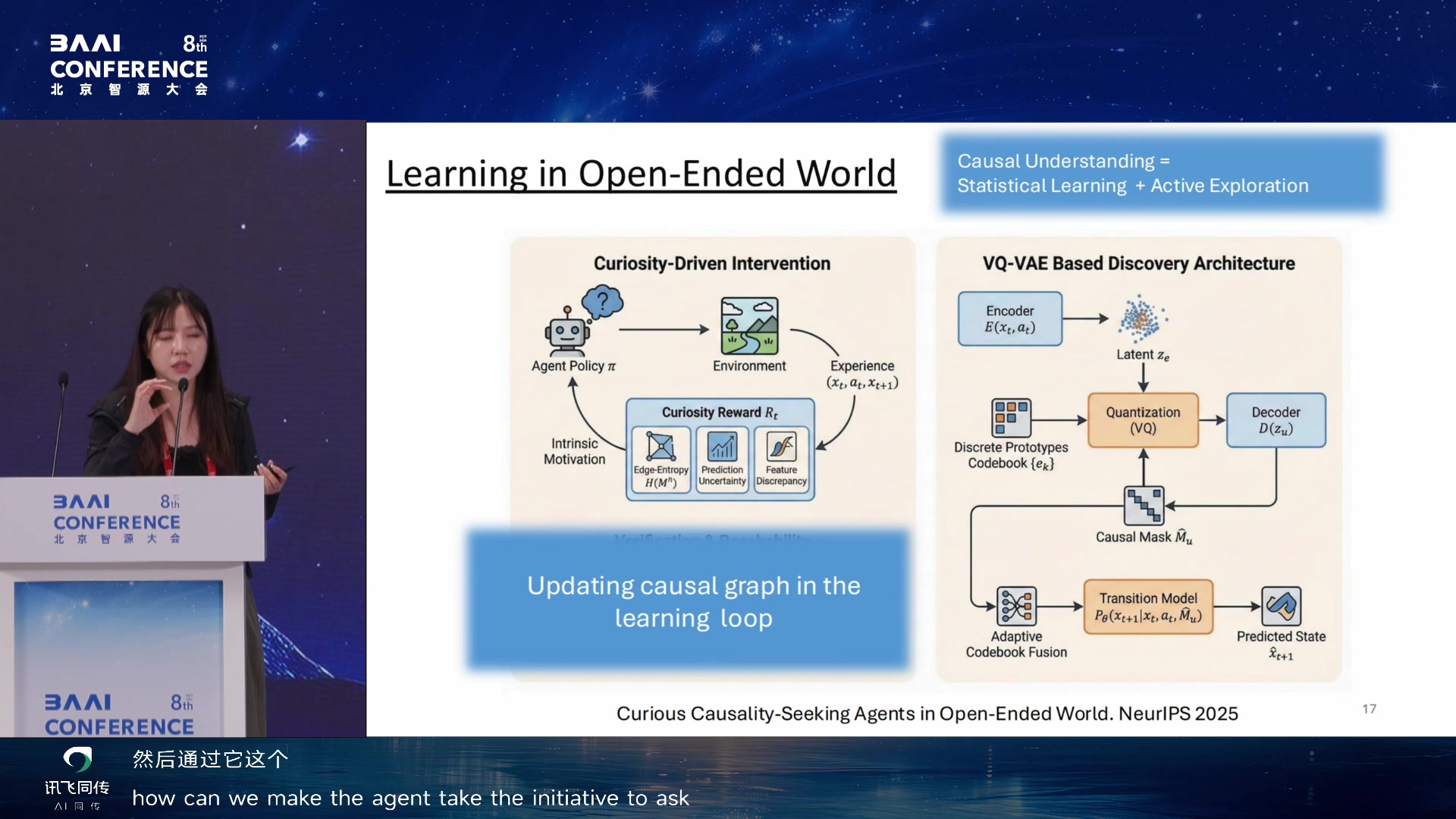
的情况下让模型自主进化。他的 reward-free self-evolution
思路:模型到新环境后先探索(像人到新城市先探索一样),以网页为例,点开很多网页记录重要信息形成
world knowledge。因为环境 token 数远大于 context
window,所以必须做摘要总结。
有了 world knowledge
后,新任务来时先查知识库,没有再实时探索。这个研究最难的一点是什么是
ground truth world knowledge——人也没法标注。卡了两三个月后想到
World Knowledge Reward:带上 world knowledge
的任务成功率减去不带的,差值就是知识对任务的边际贡献。
05|02:23:23--02:26:24
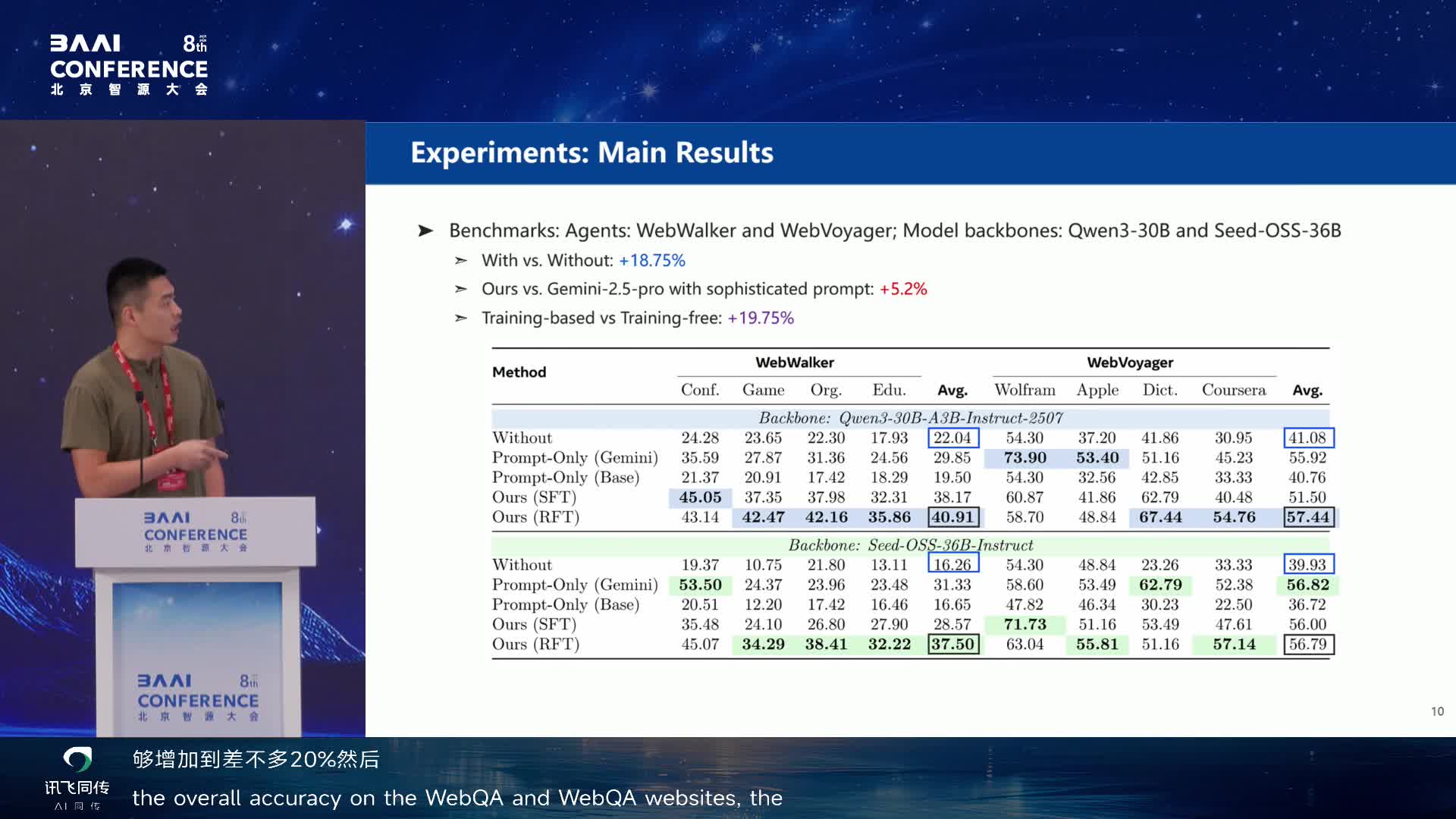
训练流程:先用强模型蒸馏做 supervised learning,再用强化学习(由于
reward 太稀疏太 delay,直接用 rejection sampling 而不是 GRPO
等算法)。效果:有 world knowledge 后整体准确率在 webwalker 和
webvoyager 上增加约 20%。Teacher model 是 Gemini Pro 2.5,但 agent
写出来的 world knowledge 对千问或 StarOS 的增幅比 teacher
本身还多五个点。不训练直接让原始模型做 self-improve 效果反而下降。
Cross-model transfer 实验:用一个模型生成 world knowledge
给不同模型用,发现知识是可以迁移的。惊人发现:在知识密集型任务上,knowledge
scaling 可能比 parameter scaling 更重要——千问三 14B 加知识超过
Gemini 2.5 Flash,Flash 加知识超过 2.5 Pro。而参数增长 10 倍只增加
2.7% 准确率。
06|02:26:24--02:29:26
腾讯小程序应用场景:绿泡泡 AI 要操作所有小程序,top
的小程序可以人标专家轨迹,top 500 的可以标 task 和 reward 做 RL
训练,但长尾的(大部分用户没用过的 minigame 等)怎么办?用
self-evolution 自动为每个小程序生成 world knowledge——上线时先写个
markdown,用户问问题时 agent 查阅世界知识文档直接回答。
做完这个工作后他又在想:为什么需要做那么多总结和
reflection?还是因为模型记忆能力不够,如果 context
足够长直接把所有信息放进去就行了。瓶颈在记忆。
07|02:29:26--02:32:26
为什么不能直接来 100M
context?不是训不起来,是推理成本。他展示了自己的 Claude Code
账单:带着 700k context 问一个简单问题,缓存没命中收 30 块钱。而且
log 分析发现 90% 超过 64K 的 query 根本不需要那么长,只需要最后 8K
甚至 100 个 token。
FlashMemory-DeepSeek-V4 的思路:全部 KV 放 CPU,只把未来 64
步需要用到的 query-critical KV cache 移到 GPU memory。Lookahead
Sparse Attention 不只搜索当前 query 需要的历史 token,还预测未来
64 步 decoding 需要的。在超过 128K 场景下 KV cache 显存压力降低
90%,LongBench V2 和 LongBench VL 上有提升,Ruler 上跟原版
DeepSeek V4 Flash 持平。
08|02:32:26--02:35:26
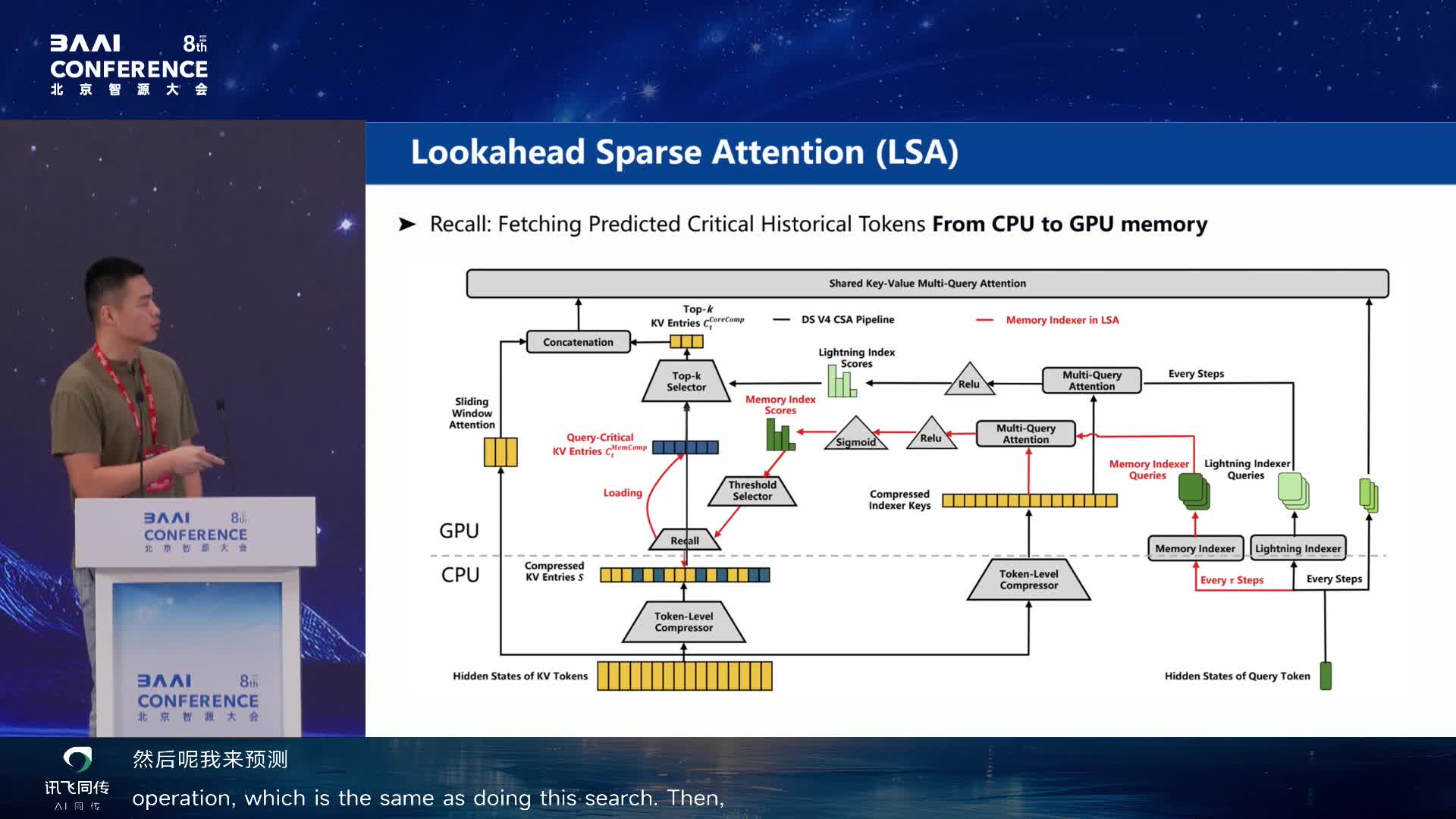
FlashMemory 的架构与 DeepSeek V4 强耦合(蹭一下 DeepSeek
的光),其他模型用不了。DeepSeek V4 原版用 Lightning Index
做搜索和 top-k 选择做 sparse attention,但需要全量历史 token KV
cache 保存在 GPU memory。FlashMemory 把 Lightning Index 复制成
Memory Index,训练目标从只搜索当前 query 需要的 token 变成预测未来
64 步还需要哪些。
Limitation:长度泛化——训练在 128K
上,泛化到更长就失效,可能是位置编码没见过更长范围;KV overhead
不是常数级,始终在 10% 左右;NQR 等 dense information task
上掉点——不确定是结构原因还是没在类似 task 上训练。
09|02:35:26--02:38:27
Q&A:有人问 reward-free/self-engineering 能否替代 agentic RL
训练。王琰明确说不行。从游戏 AI 角度看,只要 outcome reward
不要过程奖励基本就是在搞笑,肯定要加过程奖励。强化学习最根本的还是
reward,不是架构。credit assignment
最好的方法?人标——人还是最准确的判断。国内大厂由于重度依赖蒸馏,人工标注团队没有国外建立得完善,这才是问题。
杨梦月:开放世界中的因果世界理解
01|02:40:00--02:43:04
杨梦月从 agent decision making 两种路线开始:model-free(提供足够
context 和 observation,用 perception 方法让 agent
分析场景,做决策)和 model-based(agent
先理解世界再基于世界模型做决策)。model-free 在 RL
领域很常见且方便,model-based 则需要 agent 对世界建模,通过 world
model 帮助决策。
02|02:43:04--02:46:07
为什么 modelling world
是必要的?三个原因:开放世界中数据永远不够遍历所有可能性(尤其是具身
agent、web agent、game
agent);长程决策任务需要规划而非短程反应;探索机会珍贵,需要有目标的探索而非随机试错。World
model 两个主要功能:预测 take action 后的未来反应;counterfactual
想象能力——假如过去做了不同选择现在会怎样。
03|02:46:07--02:49:10
引入因果的必要性:一般 machine learning
基于关联,很可能学到假相关性。经典例子:天气同时影响伞的开合和地面湿度,但
agent 可能就理解成伞的开合影响地面湿度——基于假相关性做决策就会
fail。对安全性要求高的系统(如自动驾驶),因果和物理理解的准确性至关重要。
Pearl 三层因果阶梯:第一层 association(现有大部分世界模型和
agentic RL 学到的);第二层
intervention(做操作看反馈,了解因果关系);第三层
counterfactual(已发生事件中的反事实想象,比如病人已经服药了,怎么判断假如没服药会怎样)。Intervention
和 counterfactual 都要求了解真实物理关系/因果关系才能做到。
04|02:49:10--02:52:11
Causal World Model 不是那么难理解:agent 在构建 world
understanding 时,先判断因果关系和 physical concept
之间的关系。拥有因果建模的 world model
天然比没有的更进步——当前不管是 world model 还是 agentic RL
都在强调 physical
understanding,但要做到这一点就需要学会对世界做因果建模。
方法分两步:从高维观察(image/video)中提取 physical
concept;通过数据分析 physical concept 之间的因果关系。之前的工作
CausWay 做了初步尝试:从大量数据提取因果关系,做 counterfactual
生成。
05|02:52:11--02:55:26
回归 self-improvement 主题:在 open-ended world 中(chat
agent、自动驾驶、multi-agent 博弈),无法穷举所有可能性,随时有新
factor 进入系统,因果关系也可能变。Agent
需要持续做因果分析,而且分析随时可能被推翻。
方法 Curious Causality Seeking Agent:基于当前 observation
做因果发现和表征学习,然后基于因果 understanding
设计下一个实验(主动向环境提问),鼓励 agent 在 policy
范围外探索新 action,收到环境反馈后更新 causal
understanding。核心信念:不相信当前 causal understanding
是对的,所以需要一步一步主动向环境提问确认。
06|02:55:26--02:58:28
Causal drift
现象:因果关系看起来在变,但其实是观察手段在变。用牛顿定律和微观物理类比:物理规则本身没变,只是观察手段不够充分时看起来规则变了。所以
open-endedness 和 self-improvement
的关键是学会发现不一样的现象——通过主动向环境提问。
Meta-Causal Graph:在不同 context 下因果关系如何变化。Agent
要有能力区分不同 context
之间的边界——一开始不知道宏观世界和微观世界的物理定律有区别,要主动发现边界在哪,以及它们各自适用的规则。他们做了严格证明:meta-causal
graph 能描述不同 context 下的 causal mechanism 变化。
07|02:58:28--03:01:28
新的 LLM agent 范式形成 loop:forward design(设计更好的
exploration 方式和
trajectory)、与世界的充分互动和收益收集、backward update(用
reward 修正 trajectory/thinking chain)、knowledge 沉淀成
memory/skills 再反过来优化 forward
design。如果每一步都能自我改进,就是 recursive
self-improvement——不只是知识在积累,学习的能力本身也在进化。
她分享了之前在 evaluation、reward design、forward design 和
backward update 上的探索。Evaluation 分三个层面:LM 本身的
self-refinement 能力、rule-based/causal-based constraint
帮助评估、learned reward 辅助评估。
08|03:01:28--03:04:34
Forward design 上的探索:Creative
Game——提升大模型创造力的综合设计,本质是提升提问能力。不直接让
agent 探索,而是经过特定设计让它采样到特定数据。这个过程不涉及
reward,归类到 forward design。COT 上的探索:怎么设计更好的
COT、用 causal constraint 来做。Backward update:拿到 reward
后怎么更新 trajectory/experience。
整个 loop:continual causal learning——先做 understanding,基于
understanding 做定向 exploration,探索后提升 causal
understanding,循环往复。
09|03:04:34--03:07:35
Q&A 关键问题:如果每条因果关系都可以被更新/修改,agent
是真的进化了还是指标上看起来进化?杨梦月说这是所有
self-improvement 面临的最大问题。在因果领域用 consistency
判断:当前 causal understanding
设计的探索,环境反馈是否违背当前因果关系——如果违背就需要 update。
没有全知全能的 ground truth 告诉我们真实因果图。唯一能做的是鼓励
agent 不断突破边界探索,看它能否把新现象压缩成更一致、更简洁的
causal understanding。
郑侠武:从 Benchmarking 到可验证反馈闭环
01|03:08:12--03:11:12
郑侠武的核心动机:如何科学地测量和验证抽象推理能力。从人类历史看,从猿猴到工业革命,最重要环节是通过观察世界、用抽象能力总结规律、用推理能力应用到现实、形成
loop
改进。关键问题:能否把杂乱经验压缩成可迁移规律,以及规律能否脱离表象本身。
大模型/深度学习本质上都在数据上做
learning,但到底有没有学到背后的规则?如果 RSI
陷入死循环,可能就是因为没有探寻到背后真正的规律,只看到数据层面表象的正确答案。
02|03:11:12--03:14:12
三个问题:怎样测到真实抽象推理?如何防止模型靠熟悉符号模板过关?怎样形成自动化验证方式?第一篇工作对抽象推理做理论建模,提出
Gamma 和 Delta
分数区分真实提升和表象依赖。方法很简单:对具体规则做符号扰动替换,看模型是否还能找到背后规律。
比如加法规则,把 0 替换成 A、1 替换成
B,其他不变——模型能不能抓到本质规律?如果替换后差距越大,说明模型记住的是表象形式而不是本质规则。GSM8K
同期也有 Symbolic 版本做类似替换。
03|03:14:12--03:17:17
实验发现:在熟悉数学题上很多模型刷得很高(GSM8K
90%+),但做简单符号扰动后性能就极大降低——说明准确率混合了对规则的理解、提醒的熟悉度和模板的记忆。在操作级别替换和操作符替换中都发现大模型更依赖具体数值符号,而不是操作符本质。
有意思的发现:用 agents 方法(如 ReAct、AutoGen
框架)确实能在抽象推理上带来提升——即使符号产生扰动和改变,agent
层面依然能带来稳定提升。这说明通过 harness 或 agent RL
确实能实现某种 self-improvement。
04|03:17:17--03:20:17
第二篇 A2RBench
工作的动机:把第一篇的发现自动化。不想自己去想规律和噪声方法,而是让
LM 自动 generate 规律、自动 generate 噪声扰动,让所有 LM(包括
agent 方法)都很难找到解。规则族从 1D 转移扩展到
2D、3D。所有生成都用 Agentic 方式自动化。
验证机制:用 forward/inverse
的可逆性保证规则本身不会带来信息损失——正向转换和反向转换都能保证正确性,就不需要调
LLM judge 来判断任务是否有正确答案,用数学保证即可。
05|03:20:17--03:23:20
实验结果很有意思:即便是简单规则,经历转换后,最好的模型精度也只有
39.8%,人类能到
68.5%。说明只要规则稍微复杂、表象经过转换,大模型还是非常难发现背后规则。
Augmentation paradox:大模型在生成 3D
任务时,为了保证正确性会故意选择变化程度没那么大的规则——不是不能做
3D 题,而是在生成 3D 任务时没有很大想象空间,3D
空间结构理解能力不足。信息复杂度和 accuracy 也有关系:3D
任务信息复杂程度降低,反而结果更好。
06|03:23:20--03:26:23
郑侠武认为未来重点是
evaluation——评测到底能不能真正探知到大模型是否发现了背后规律,以及为什么不能发现。未来会往更实际的
agentic 路径和 3D 多空间结构理解方向推进。
他想做的方向:从 bench
角度持续监控大模型能力,判断到底是因为符号依赖还是因为发现了规律,以及循环一致性——通过产生任务避免错误信号进行训练,让
LM 自动发现背后规律。
07|03:26:23--03:29:16
整体结论:评测不仅仅是 RSI
的外围工具,而是判断循环能否产生真实改进的核心变量。他们做的是可靠评测——任务本身是否可验证、能力到底是因为表象依赖还是真正发现了规律、以及在扰动后是否仍可迁移。从静态考试推进到加噪声后的可持续反馈机制。
圆桌讨论:觉醒与进化,AI 如何自我迭代
01|03:29:16--03:32:18
主持人开场:现在 agent
已具备反思、调用工具、优化指令能力,但从短期调整到长效迭代的系统还有很长路。AI
自进化意味着智能体如何依托自身运行轨迹、环境反馈与自我判断,完成对模型、记忆、工具、工作流乃至多智能体架构的全方位升级。目前学术界和工业界探索都比较初期。
02|03:32:18--03:35:18
林涛定义自进化为多层级进化:外脑进化、内脑进化,最重要的是 AI
如何认知自己局限并进化外脑和内脑,把外部能力内化到本体。谷雨延续
talk 框架:两个维度——proactiveness(what
dimension:知道自己缺什么、需要什么、应该怎么学)和 learning(how
dimension:具体学习算法)。王琰更经验主义:今天很多自进化还是
human-driven,但比经典 SFT/RL 更少依赖人类就算自进化一部分。
03|03:35:18--03:38:19
杨梦月强调
open-endedness:不只是能力进化,还要进化"发现知识边界和提出问题"的能力——进化能力本身的进化。她提到
Recursive 公司联创团队中 Jeff Cologne 和 Tim Rock Tashel
的研究方向就叫 Open-endedness。
接着讨论哪一层最先成熟:王琰认为基模领域已经在 AI 迭代
AI,迭代速度明显加快。即使不改参数只改 prompt/harness/context
也能产生巨大跃迁。
04|03:38:19--03:41:22
林涛认为对大多数人 harness 最容易起步——更好的 harness
发挥模型上限,用户产生的 harness 和 trajectory
回流到基模训练,形成外脑到内脑循环。谷雨用统一 memory
视角:harness 是 meta-level memory,tools/skills 是 workflow
memory,模型权重是 system 1
intuition——学术上难以只选一层,创业上从 harness 起步因为不必和
Frontier Lab 竞争基模。
杨梦月倾向于 memory
层(因果和规则理解),但提醒基模能力增强可能吞噬 harness
价值,要动态看。王琰补充:harness
有可能被模型进步蚕食,但有些模块(如 guardrail
保证安全性和可验证性)是概率模型永远不可能取代的。
05|03:41:22--03:44:41
什么时候进化?谷雨强调 learning during inference + long-term
memory:人每次推理都是学习机会,不应浪费。传统深度 RL
基于模型参数更新,很难做 online
learning,未来可能需要非参数更新——每来一个 case 立刻完成更新。有
system 1 和 system 2 的感觉:非参数是 system
2(更显示、更慢),但保留了转化到 system 1 的可能性。
王琰谈 TTT、Doc2LoRA、delta
rule:这些都是在前向推理中更改模型参数。但他认为终点是模型在
next-token prediction 时自己学会每个 token
的更新梯度应该怎样、data rule
应该怎样——这才是真正端到端的思想,而不是高维生物替它决定。
06|03:44:42--03:47:42
林涛从训练角度补充:harness 先影响
post-training,提升模型性能后反馈到
pre-training/mid-training,形成多尺度闭环。什么时候进化?时时刻刻,只是尺度不同、更新对象不同。杨梦月用
forward/backward/memory loop 回答:推理是 forward design,反馈后是
backward update,沉淀下来的知识进入 memory/skill 层。
07|03:47:42--03:50:44
Benchmark 是否也要自进化?杨梦月认为需要增长式 benchmark 或增长式
world model——像 curriculum learning
一样让环境可观察面逐步展开,匹配 agent 能力。静态 benchmark 可以被
overfit,没有参考价值通往 AGI。王琰怀疑:open-ended generation
根本没有 benchmark,对话、角色扮演都是人评测——自进化 agent
是否最后也得回归人评测?
08|03:50:44--03:53:45
王琰继续:现在很多模型网上训练得很好,一上线在 agent workflow
里就各种
degeneration,必须用线上数据飞轮再训。谷雨的比喻:拿"一个人每天送多少个老奶奶过马路"来判断好人,一定会被
hack——AI 也一样。但现阶段 AI 还没复杂到那种程度,benchmark
仍能指导前进。
关于谁提供 benchmark:目标还是得人提供,因为 benchmark
代表目标。但 self-improving 的评估和传统不同——不只看最终
accuracy,要看趋势曲线(横轴完成任务数,纵轴
performance,理想系统应持续上升)。
09|03:53:45--03:56:46
谷雨继续:传统 benchmark 只看最终结果——掌握了什么 skill。但
self-improving 要看"如何掌握 skill",看学习过程。Chalet
的话:intelligence
不在于你会做多少事,而在于你是怎么会做这些事。how to learn
本身才是 intelligence
最核心的东西——就像人一样,拿一张试卷,有些人刷题刷上去,有些人是真聪明,只看最终分数分不出来。
林涛补充:真正的 intelligence 应该是 ability
单位时间增长的速度。模型和 benchmark
应该协同进化,未来有半自动化方式发现更有意义的 benchmark。
10|03:56:46--03:59:49
话题转向安全。主持人提到早上两位图灵奖获得者分别从能力(RL)和安全角度谈了
agent 进化。王琰给出尖锐判断:AI
失控不遥远,安全不取决于技术而取决于人性——诸葛公司叫 RSI
能融很多钱,叫 AI 安全能不能融
1%?不可能。作为独立研究员,他认为克制不住。林涛的技术侧回答:半自动化
benchmark 需要有人参与,提供人类定义的约束。
11|03:59:49--04:02:50
杨梦月从 trustworthy AI
出发:safety、explanation、causality——所有组件之间要有 rule
被显示在所有人面前,要知道为什么做这个决策才能控制。传统 causal
discovery/inference 方法不适应大模型时代,需要回到 Pearl
因果阶梯基本定义,重新思考约束形式。
谷雨把短期可控性落到 reliability 和 verifiability:reliability
是一件事做对了下次也要做对,verifiability
是做错了要知道自己错了。对 agent 落地来说比宏大安全叙事更直接。
12|04:02:50--04:05:51
AI 和人的协同进化。林涛:已经把大部分工作流用 AI
替代,效率提升让他有时间想更多问题,但人如何更高效进化以促进 AI
进化仍需探索。杨梦月从教育经验出发:基础扎实的人能用 AI
产出高质量工作,基础不扎实的人会被 AI 误导。AI
让人分层——越有基础越到顶部,越依赖工具越只是镀金。
13|04:05:51--04:08:51
王琰的"暴论":AI 会极大加剧贫富差距。有意识的富人会为孩子创造无 AI
环境刺激基础知识增长,没意识的家庭孩子直接用 AI
完成作业——这是最快的 reward hack 方法。他观察到实习生用 Claude
Code 后初期很快但后面问题不断,根本不知道整个项目在做什么,跟不上
context。更 senior 的人有了 Claude Code
后不太需要他们帮忙了——客观上给他们的锻炼机会变少了,拿到机会时利用能力也下降了。
14|04:08:51--04:11:52
谷雨用"慢就是快"总结:vibe coding 冲得很快但理解没跟上,repo
越来越失控,反而要花更多时间整理。他宣传了自己主持的播客
Ungrounded,上一期刚好聊了 AI 和人共生话题。两个视角:如果把 AI
当工具,工具和人向来有共同演进关系,比较乐观;但如果 AI
不是工具而是平等甚至凌驾于人的东西,未来就不一定是共同进步。
15|04:11:52--04:14:52
历史定位问题:AI 自进化是现有 agent
技术的自然延伸还是新阶段?林涛认为很自然走到 AI 进化,agent
成熟让事情更简单。王琰:就是下一阶段——未来每个人会有独有参数区域(个人
LoRA),inference/training infra 支持实时 LoRA merge/unmerge
后,个人任务反馈直接沉淀到个人模型。RL
已经是监督学习和自进化之间的半自进化阶段,推理时 reward
也没有了或变成 text as reward。
16|04:14:52--04:17:52
谷雨认为不是互斥问题——量变引起质变。关键维度是任务长程程度:从单轮对话到多轮推理、deep
research、月/年级任务、lifelong
task。任务越长程,系统越需要在过程中发现不足、节省经验、持续学习,自然就成了
RSI。杨梦月也同意量变引起质变,但她的评价标准不是长程任务而是综合能力——包括快速适应新环境、continual
learning、每个精细操作都能顺利完成。Self-improvement 只是通往 AGI
的重要技术手段,不是全部。
17|04:17:52--04:20:52
未来五到十年畅想。林涛:会改变一切——出生就有随身设备帮你构建个人数字人,从出生到养老到死亡,5-8
年内可以畅想。谷雨:改变方方面面,希望 AI
能取代自己(创业挺累),但更可能发生的是资本家用 AI
取代更多人。他说"现在没被取代只是因为资本家还不想背名声,而且员工工资没有
token 贵"。希望 AI
让五天工作制变三天、八小时变四小时,而不是造成大面积失业。
18|04:20:52--04:23:54
杨梦月从哲学角度:人类需要对自己在世界上的价值有感知。每天刷小红书推特看到新东西,感觉自己做的研究马上被
AI 基模 scope
掉,非常害怕。需要给人留空间思考自身价值。王琰补了一句:进步快点也行,但进步点好的东西——别总是让人失业。林涛补充:也许进化更快后,SpaceX
和外太空机会更多,人不会只局限在地球——那时候不是失业问题而是人太少。王琰回:就像互联网公司都在做买菜,国家说不要总盯着老百姓菜篮子——钱容易赚,但应该克制。
20|04:26:56--04:27:53
圆桌正式结束。论坛全部结束,感谢参与。